
Low-Rank Adaptation and Key-Value Cache utilization
The GKE Inference Gateway endpoint picker extension is specifically designed to perform LoRA and KV cache utilization routing. But why does it matter?
Low-Rank Adaptation
Let’s start with LoRA using an analogy: your main warehouse is staffed by a world-class, general-purpose expert (the Base Model). This expert can package anything: books, electronics, clothing, etc. They are incredibly knowledgeable but very “general.” What happens when a customer has a highly specific, custom request? For example Gift-wrap this book in blue paper with a handwritten note in Spanish.
- The Old Way (Full Fine-Tuning): You would have to hire and train a brand new, full-time expert who only does Spanish gift-wrapping. This is expensive, slow, and you need a separate expert for every single custom task (one for Italian, one for poetry, etc.)
- The LoRA Way: You keep your single, world-class expert. But next to their main workstation, you place a small “Finishing Touches” Kiosk (the LoRA Adapter). This kiosk contains a small set of instructions and a few special tools — a roll of blue paper, a specific pen, and a card with a few key Spanish phrases.

When a custom order comes in, the main expert does 99% of the work, then, they simply take the package to the LoRA kiosk, apply the small, specific adjustments, and send it out. This is LoRA: lightweight, fast to “train”, and swappable.
Key-Value Cache
The KV cache in LLMs is a brilliant optimization technique and I would argue a key pillar in making the transformer architecture viable. It speeds up text generation by storing and reusing previously computed key and value tensors during the decoding process. Instead of recalculating these tensors for each new token, the model retrieves them from the cache, significantly reducing computation time.
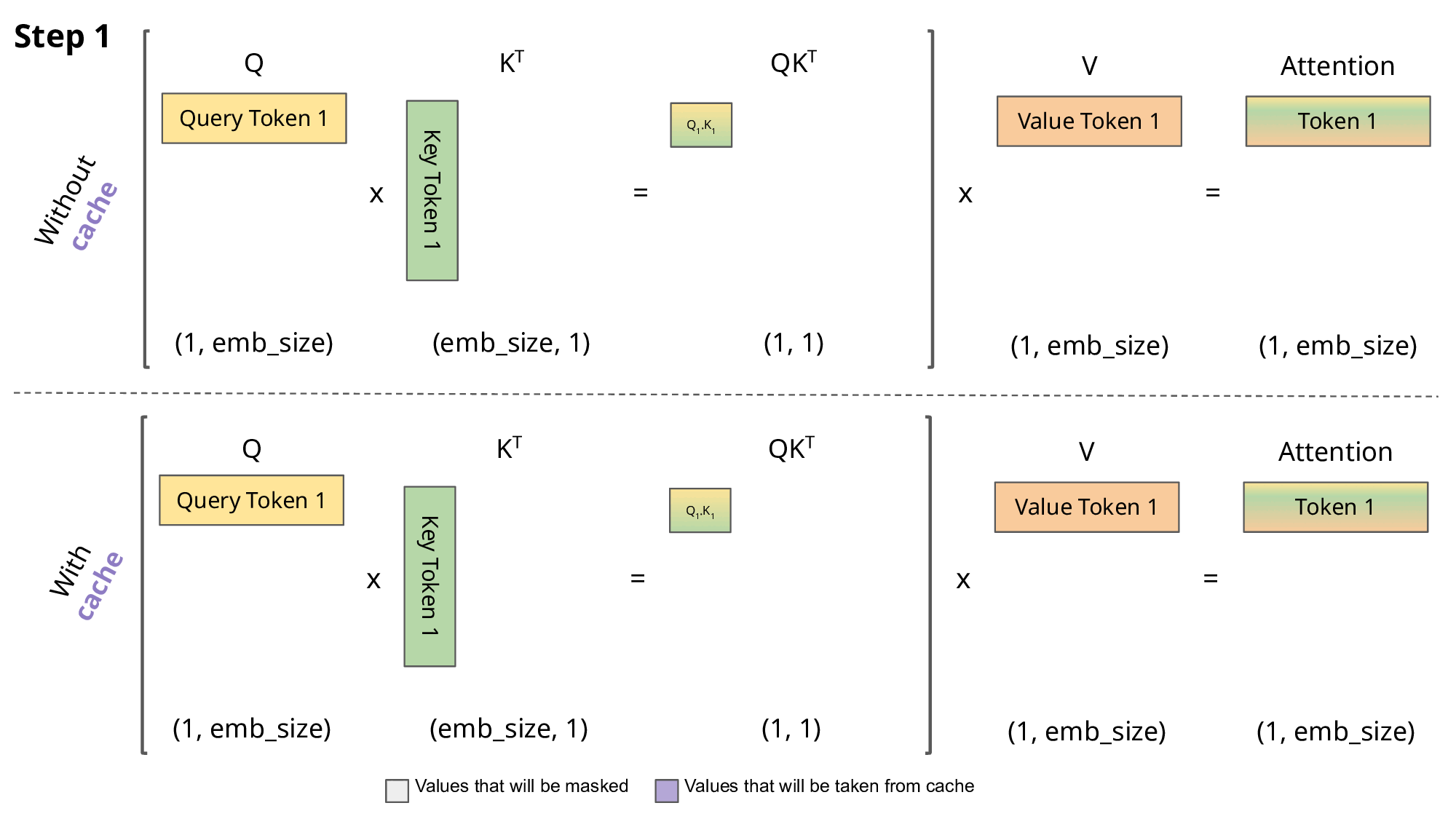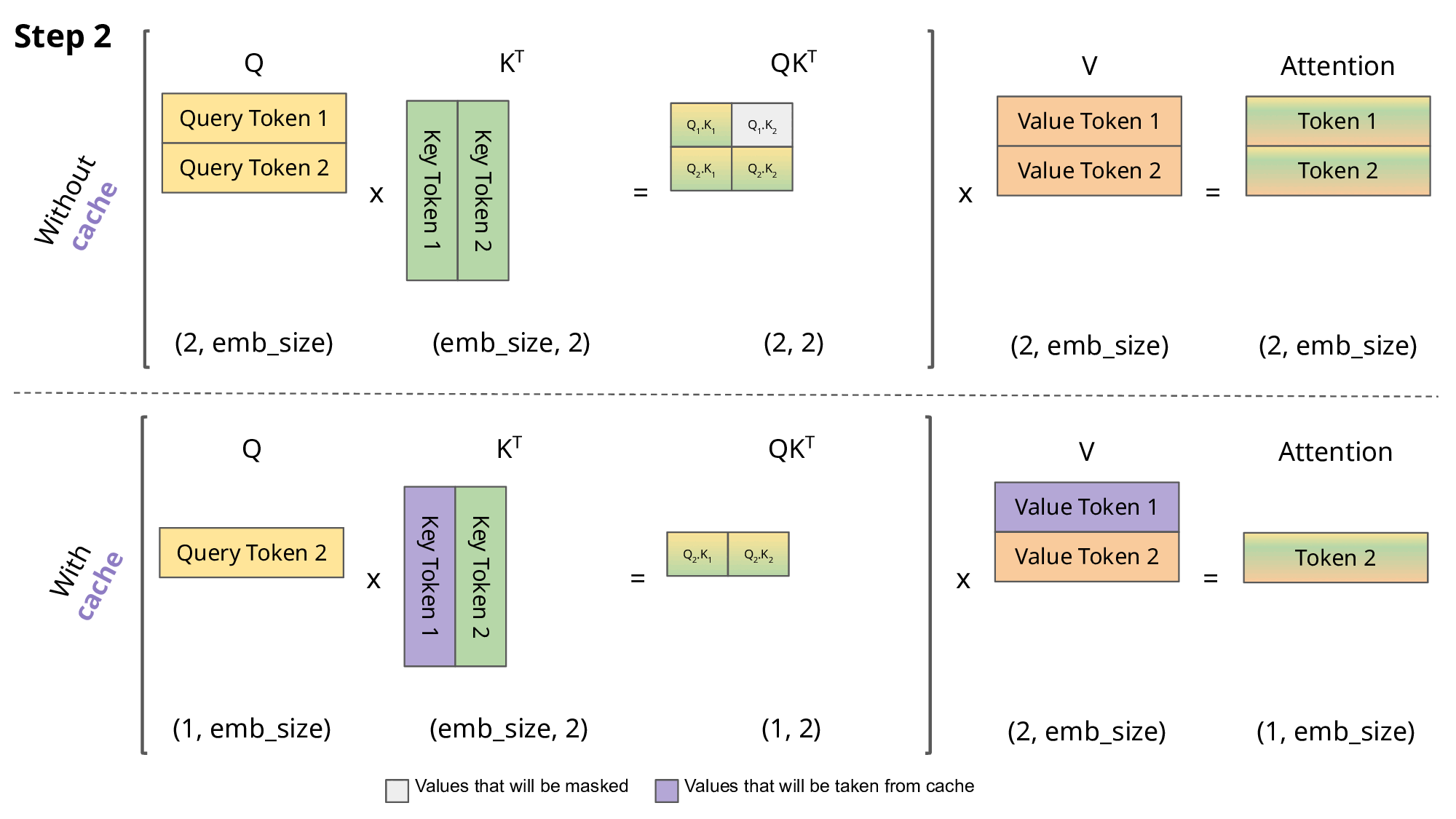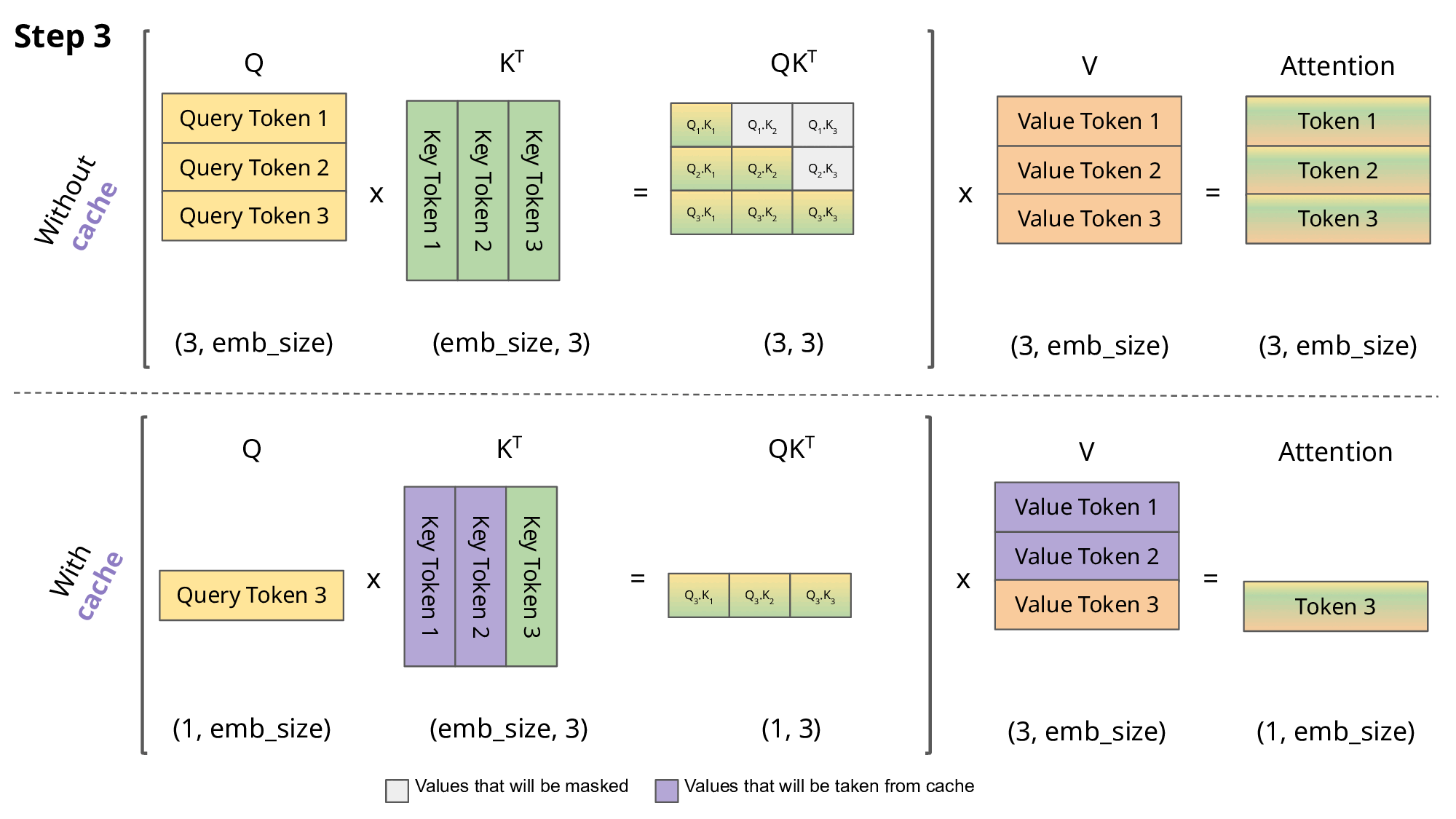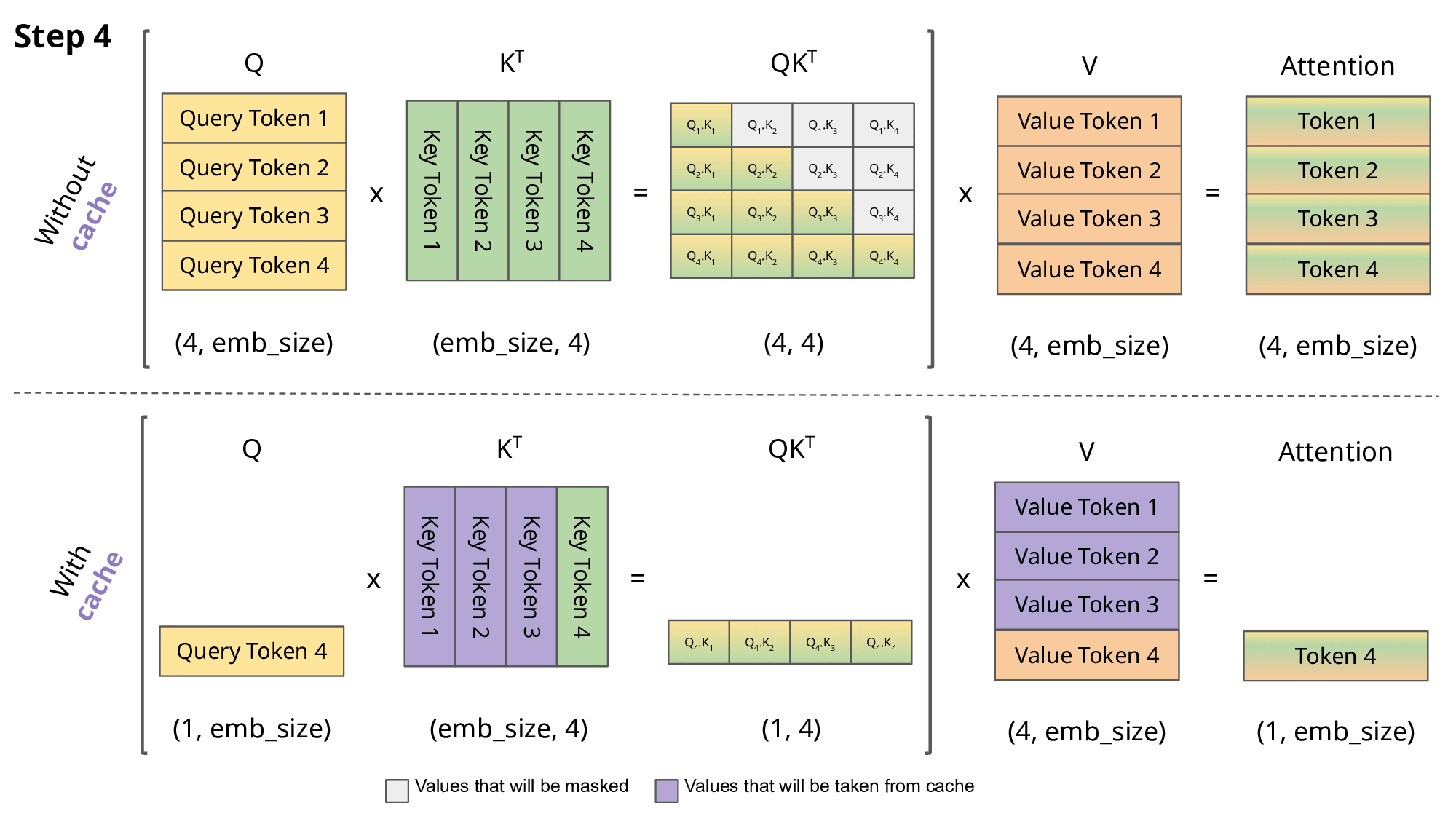
We therefore have a uniform KV cache utilization across the inference engines ensuring the model servers do not get saturated, The queue of incoming requests is minimized, directly leading to lower TTFT (Time-to-First-Token) latency.
Serving AI to billions requires a global nervous system. Google Cloud provides this with two foundational pillars. First, its anycast network offers a single, global IP address. This means a user’s request from Tokyo and another from Berlin hit the same IP but are instantly routed to the closest network edge, slashing latency.

Second, this traffic is then intelligently directed across a vast footprint of 42 cloud regions. With GPU and TPU resources distributed globally, GKE Inference Gateway can route inference requests not just to the nearest region, but to the one with the most optimal capacity. This combination of a universal front door (anycast) and a distributed backend (regions) is the core architecture that enables massive, low-latency AI inference at a planetary scale.
To run inference at scale, you must master the art of acquiring capacity. Google’s answer is GKE Custom Compute Classes — CCC for friends. Think of it as a smart, prioritized shopping list for your AI infrastructure. As a Kubernetes custom resource, a CCC lets you define a fallback hierarchy of different accelerators (GPUs, TPUs) and pricing models (Reservations, DWS Flex, On-demand, and even Spot).

In the example above, we can see a CCC targeting A3 machine families (A3 features NVIDIA H100 GPUs). It starts by consuming A3 through a reservation, then moves to DWS (Dynamic Workload Scheduler) Flex, and ultimately, if nothing else is available, it will spin up some A3 in Spot mode.
This gives you nuanced control over your risk profile, prioritizing acquired reservations for the business-as-usual workloads and opportunistic Spot VMs for dire times. The GKE autoscaler then acts as your expert capacity hunter, following these declarative rules to find the best available hardware. It’s a resilient, cost-aware foundation for ensuring your inference workloads always have a place to run, optimally and efficiently.
From my first day at Google Cloud, I fell in love with our hands-off approach for observability. You get pretty much everything out-of-the-box, it works like a charm, and it’s mostly free or at a very low cost.
NVIDIA DCGM and Inference Engines metrics are immediately available.
Source Credit: https://medium.com/google-cloud/scaling-inference-to-billions-of-users-and-agents-516d5d9f5da7?source=rss—-e52cf94d98af—4




