
Spanner has long been the backbone for Google’s most critical services, from Gmail and YouTube to Photos and Chat. Spanner is a one of a kind database. Some even say it defies the CAP Theorem. This is an engineering hero story on a new release for Spanner: Schema insights.
This feature, long used by Google engineers to optimize the applications millions use every day, is now available to help you harness Spanner’s superpowers with ease.
As applications grow, their access patterns naturally change. To ensure your database remains perfectly tuned to these evolving needs, Google Cloud engineers have made these internal optimization tools accessible to everyone. Schema Insights acts as a proactive guide right next to your tables in Spanner Studio, helping you maintain a schema that is always optimized for speed and scale.
Designing for High-Throughput Distribution
Spanner achieves horizontal scalability by partitioning and distributing data across different splits and servers. To ensure maximum performance, it is a best practice to distribute your workload evenly across these servers. Think of it as balancing the amount of data each server has, so they can all search and update at the same time.
Monotonic keys and hotspots
When a primary key uses a timestamp or an increasing integer, new records may land in the same partition. This can potentially create a “hotspot” as your applications access one partition predominantly more than others.
Insights will recommend strategies like hashing, bucketing, or bit-reversing key columns to ensure your data is distributed effectively for parallel processing.

This is a common design pitfall that might not be obvious if we don’t have the distributed data storage aspect in mind. The good news is this can also be easily fixed. Consider these recommendations when designing the schema for your distributed database on Spanner.
Streamlining Schema Architecture
In a distributed database, the complexity of your schema directly impacts the performance of transactions and queries. Keeping the schema lean ensures that our application stays fast and maintainable.
A complex schema not only gets in the way of clean and maintainable code, it can make it harder to scale horizontally, increase latency and degrade performance of write and read operations. The insights below basically are designed to guide you through this process of designing and fine-tuning your schema the right way, and to avoid certain pitfalls that might not necessarily be obvious but lead to huge performance penalties.
Table density
While Spanner is fully relational, highly normalized schemas can increase memory and server overhead. A large number of tables may indicate a schema may need a redesign to apply patterns such as multitenancy.
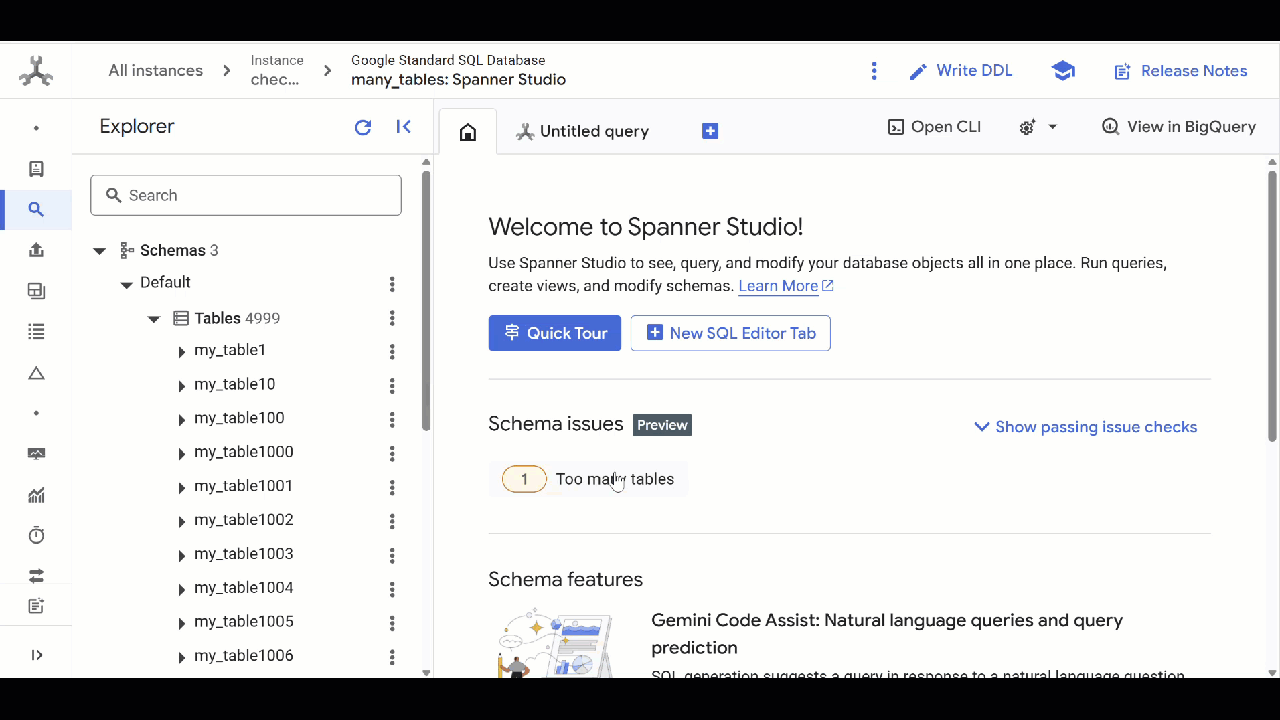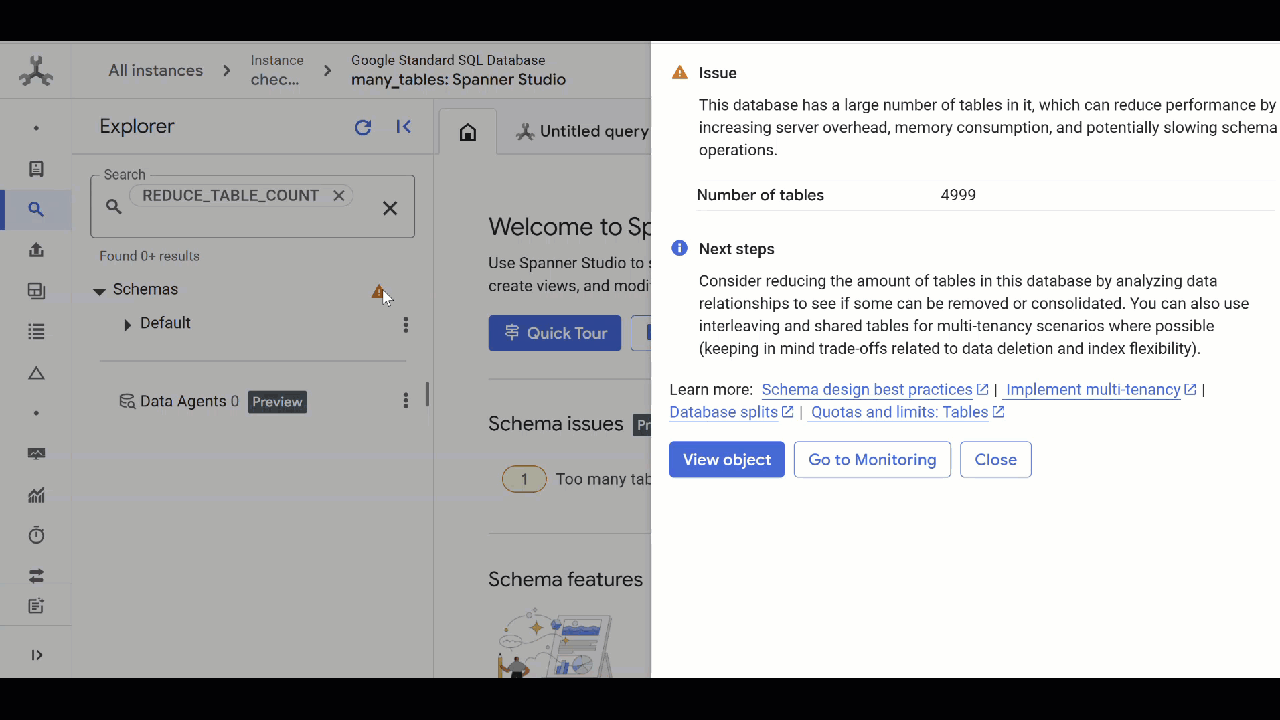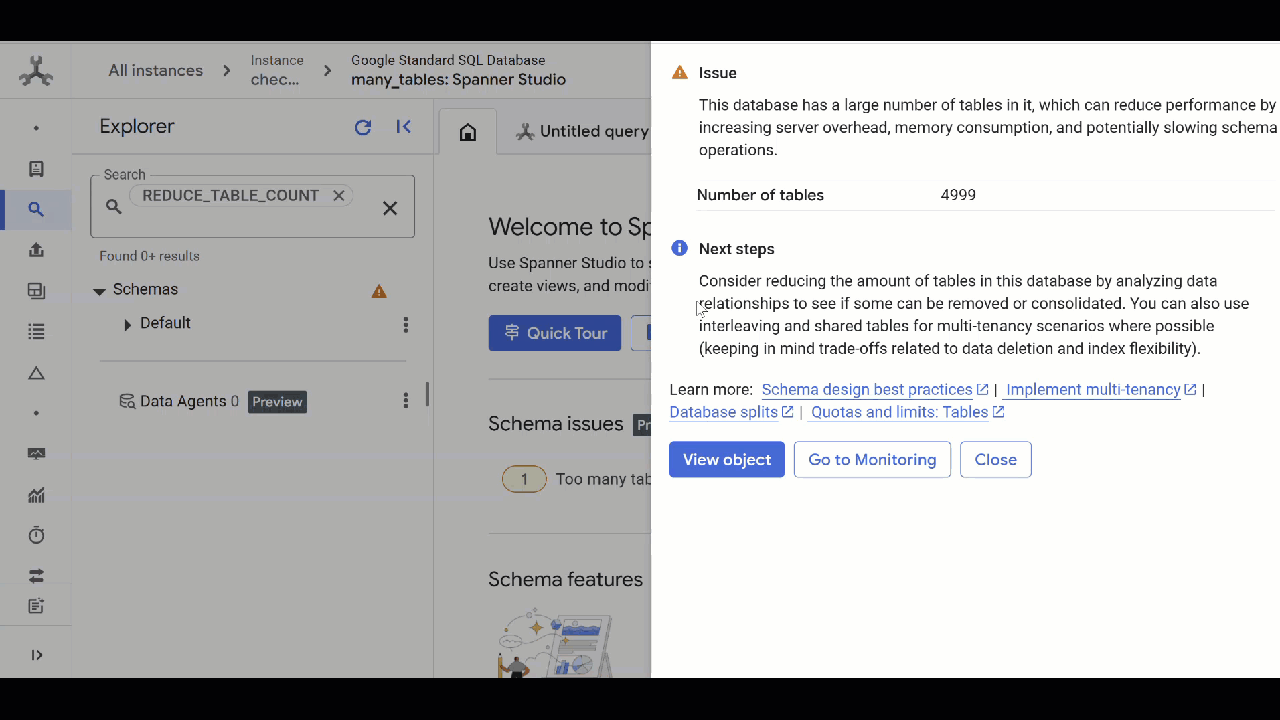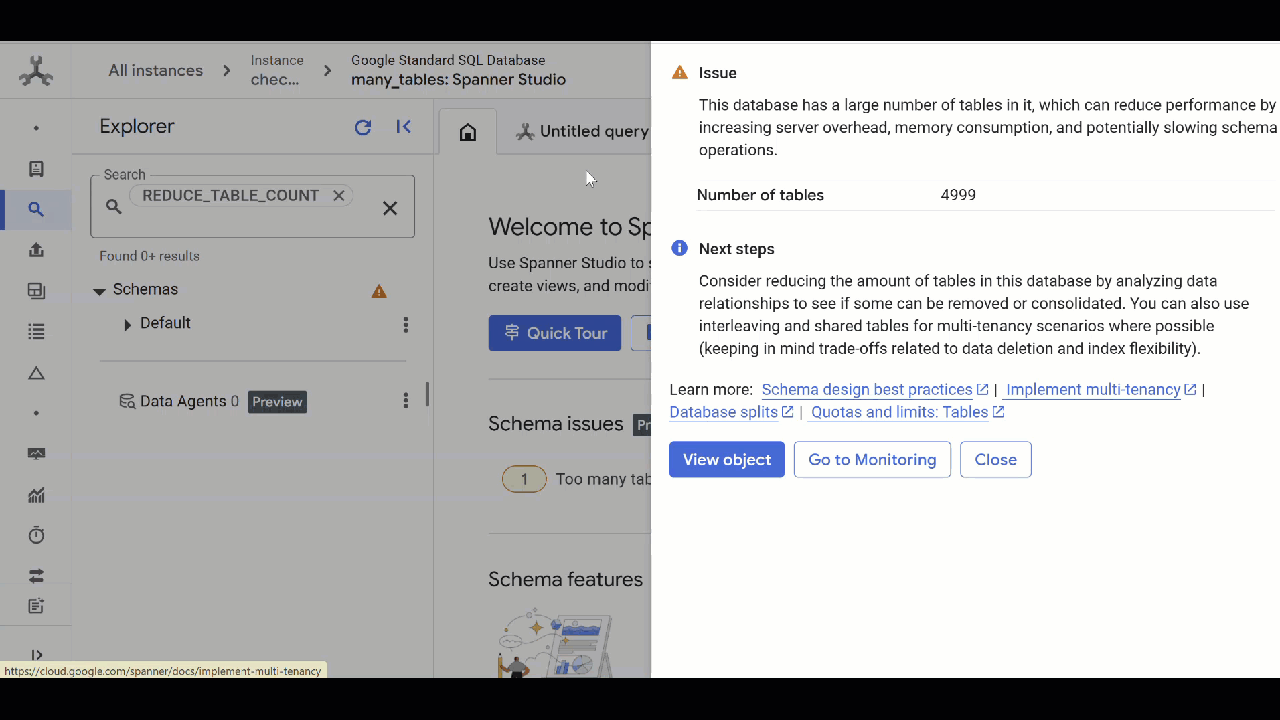
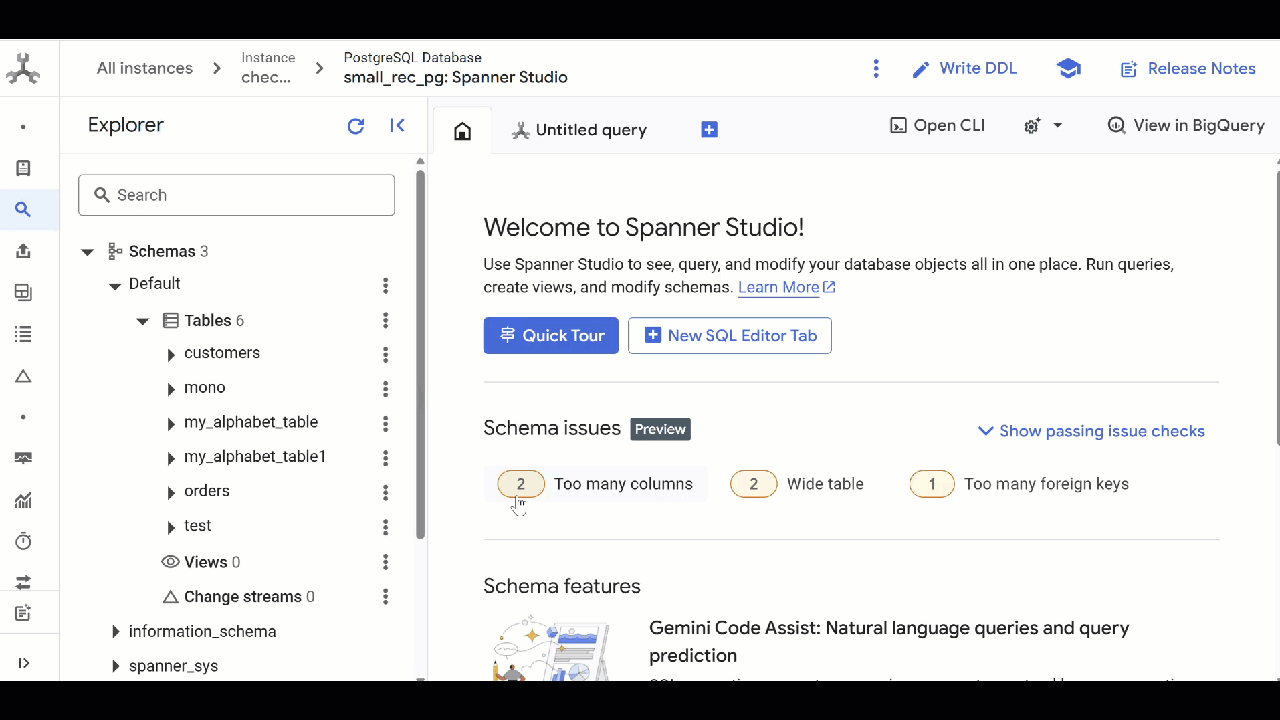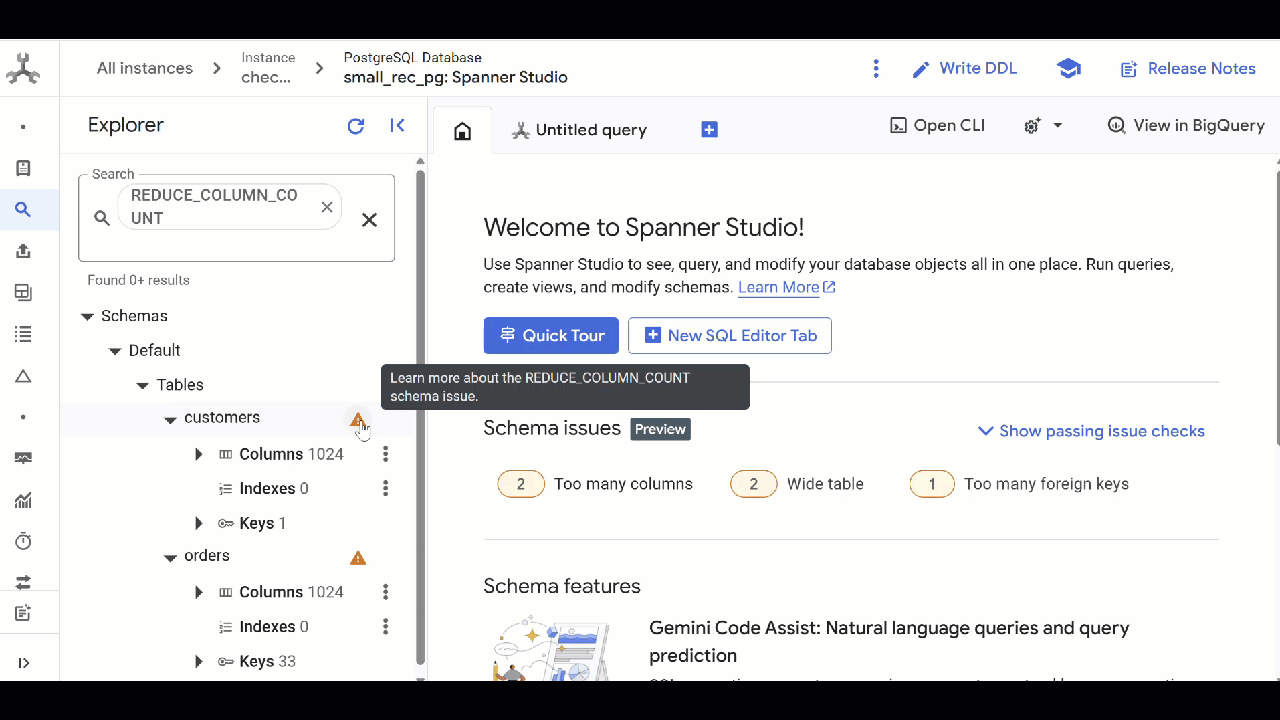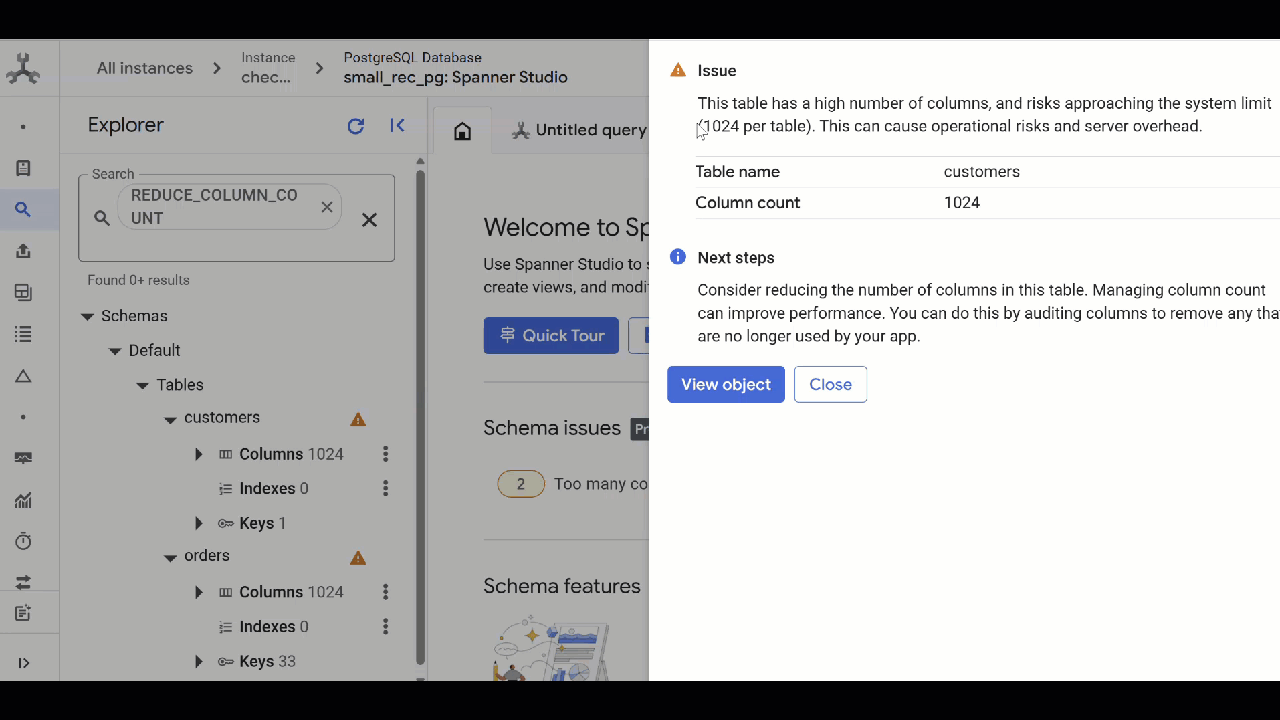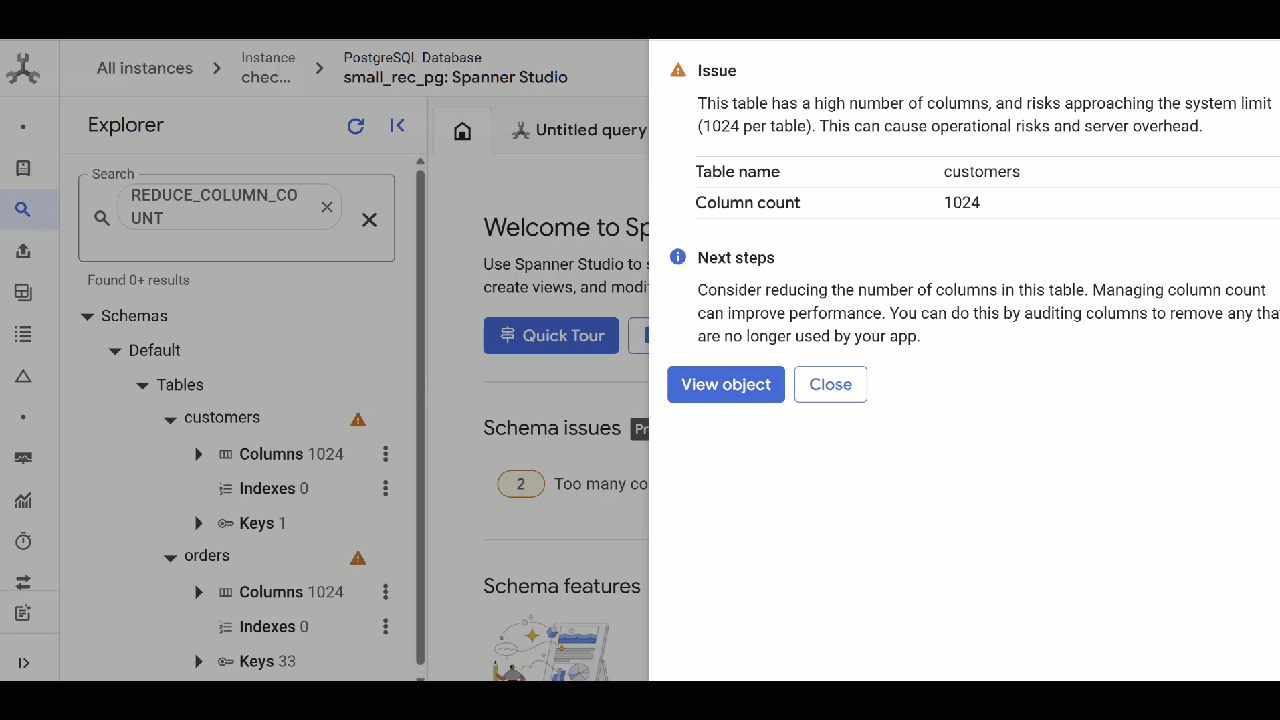
Too many columns
This should be hard to reach and it probably means it’s time for a more holistic view of the schema design, but a table can have a maximum of 1024 columns. The issue will be highlighted when a table starts approaching that limit so we have time to react.
Relational integrity
Maintaining foreign key references requires additional data to be consulted during transactions, which can slow down processing. Optimize for transactional speed by balancing the number of foreign key references.

Unlock Deeper Observability
Schema Insights works within Spanner Studio so you have the schema and context handy. It also works in tandem with Spanner’s suite of observability tools.
For example, the Key Visualizer allows you to visualize your specific traffic patterns and see exactly how your schema choices affect data distribution. To further understand potential problematic queries, Query Insights will highlight issues like high CPU utilization.
The best part of these tools is they highlight your specific access patterns, so you can tailor your next steps based on your needs and knowledge of your applications.
We’d love to know how this is working for you.
Let’s stay in touch on TikTok, Instagram or YouTube!
This post was co-authored with the product and engineering heroes of this story:
Guoqiang Pan, Igor Grunskyi, Jagan Athreya, Masha Lifshits
Introducing Spanner Schema Insights: Optimizing Your Global Database Design was originally published in Google Cloud – Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source Credit: https://medium.com/google-cloud/introducing-spanner-schema-insights-optimizing-your-global-database-design-aa0ae7d4843f?source=rss—-e52cf94d98af—4




