
As artificial intelligence and machine learning (AI/ML) workflows grow in scale and complexity, it becomes harder for practitioners to organize and deploy their models. AI projects often struggle to move from pilot to production. AI projects often fail not because models are bad, but because infrastructure and processes are fragmented and brittle, and the original pilot code base is often forced to bloat by these additional requirements. This makes it difficult for data scientists and engineers to quickly move from laptop to cluster (local development to production deployment) and reproduce the exact results they had seen during the pilot.
In this post, we explain how you can use the Flyte Python SDK to orchestrate and scale AI/ML workflows. We explore how the Union.ai 2.0 system enables deployment of Flyte on Amazon Elastic Kubernetes Service (Amazon EKS), integrating seamlessly with AWS services like Amazon Simple Storage Service (Amazon S3), Amazon Aurora, AWS Identity and Access Management (IAM), and Amazon CloudWatch. We explore the solution through an AI workflow example, using the new Amazon S3 Vectors service.
Common challenges running AI/ML workflows on Kubernetes
AI/ML workflows running on Kubernetes present several orchestration challenges:
- Infrastructure complexity – Provisioning the right compute resources (CPUs, GPUs, memory) dynamically across Kubernetes clusters
- Experiment-to-production gap – Moving from experimentation to production often requires rebuilding pipelines in different environments
- Reproducibility – Tracking data lineage, model versions, and experiment parameters to facilitate reliable results
- Cost management – Efficiently utilizing spot instances, automatic scaling, and avoiding over-provisioning
- Reliability – Handling failures gracefully with automatic retries, checkpointing, and recovery mechanisms
Purpose-built AI/ML tooling is essential for orchestrating complex workflows, offering specialized capabilities like intelligent caching, automatic versioning, and dynamic resource allocation that streamline development and deployment cycles.
Why Flyte/Union for Amazon EKS
The Flyte on Amazon EKS Python workflows scale from laptop-to-cluster with dynamic execution, reproducibility, and compute-aware orchestration. These workflows, along with Union.ai’s managed deployment, facilitate seamless, crash-proof operations that fully utilize Amazon EKS without the infrastructure overhead. Flyte transforms how you can orchestrate AI/ML workloads on Amazon EKS, making workflows simple to build. Some key factors include:
- Pure Python workflows – Write orchestration logic in Python with 66% less code than traditional orchestrators, alleviating the need to learn domain-specific languages and removing barriers for ML engineers and AI developers migrating existing code
- Dynamic execution – Make real-time decisions at runtime with flexible branching, loops, and conditional logic, which is essential for agentic AI systems
- Reproducibility by default – Every execution is versioned, cached, and tracked with complete data lineage
- Compute-aware orchestration – Dynamically provision the right compute resources for each task, from CPUs for data processing to GPUs for model training
- Robustness – Pipelines can quickly recover from failures, isolate errors, and manage checkpoints without manual intervention
Union.ai 2.0 is built on Flyte, the open source, Kubernetes-based workflow orchestration system originally developed at Lyft to power mission-critical ML systems like ETA prediction, pricing, and mapping. After Flyte was open sourced in 2020 and became a Linux Foundation AI & Data project, the core engineering team founded Union.ai 2.0 to deliver an enterprise-grade service purposed-built for teams running AI/ML workloads on Amazon EKS. Union.ai 2.0 reduces the complexity of managing Kubernetes infrastructure through managed operations, a multi-cloud control plane, and abstracted infrastructure management, while providing ML-based capabilities that help data scientists and engineers focus on building models with enhanced scale, speed, security, and reliability.
Additional benefits of using Union.ai 2.0 include:
- Enhanced scalability – Workflows respond at runtime with flexible branching, task fanout, and real-time infrastructure scaling.
- Crash-proof reliability – Automatic retries, checkpointing, and failure recovery allow workflows to stay resilient without manual intervention.
- Agentic AI runtime – Union.ai is designed for long-lived agentic AI systems, supporting stateful agents and truly durable orchestration.
- Compliance – For regulated industries, built-in lineage, auditability, and secure execution (SOC2, RBAC, SSO) are critical. Orchestration on Amazon EKS and Union.ai helps facilitate compliance.
- Resource awareness – It offers first-class support for compute provisioning, spot instances, and automatic scaling.
The benefits of Flyte and Union.ai 2.0 elevate modern orchestration to a first-class requirement: dynamic execution, fault tolerance, and resource awareness are now built-in, providing a more developer-friendly experience compared to 1.0.
Amazon EKS provides your compute, storage, and networking backbone. Flyte (the open source project) handles workflow orchestration. Union.ai extends Flyte with infrastructure-aware orchestration, enterprise-grade security, and turnkey scalability, giving you production-ready Flyte without the DIY setup. Both Flyte and Union.ai 2.0 run on Amazon EKS, but serve different needs, as detailed in the following table.
| Feature | Open Source Flyte | Union.ai 2.0 |
| Deployment | Self-managed on your EKS cluster | Fully managed or BYOC options |
| Best for | Teams with Kubernetes expertise | Teams wanting managed operations |
| Performance | Standard scale | 10–100 times greater scale, speed, task fanout, and parallelism |
| Infrastructure | You manage upgrades, scaling | White-glove managed infrastructure |
| Enterprise features | No role-based access control | Fine-grained role-based access control, single sign-on, managed secrets, cost dashboards |
| Support | Community-driven | Enterprise SLA with Union.ai team |
| Real-time serving | Build your own | Built-in real-time inference and near real-time inference with reusable containers |
Enterprises like Woven Toyota, Lockheed Martin, Spotify, and Artera orchestrate millions of dollars of compute annually with Flyte and Union, accelerating experimentation by 25 times faster and cutting iteration cycles by 96%.
Both options (open source Flyte and Union.ai 2.0) integrate with the open source community, facilitating rapid feature rollout and continuous improvement.
Solution overview
Although open source Flyte provides powerful orchestration capabilities, Union.ai 2.0 delivers the same core technology with enterprise-grade management, removing the operational overhead so your team can focus on building AI applications instead of managing infrastructure. This is achieved through a hybrid architecture that combines managed simplicity with complete data control. The Regional control plane handles workflow metadata and coordination, while the Union Operator deploys directly into your EKS clusters—keeping your data, code, and secrets entirely within your AWS perimeter.
The following figure illustrates the operational flow between Union’s control plane and your data plane. The Union-managed control plane (left) orchestrates workflows through Elastic Load Balancing (ELB), storing task data in Amazon S3 and execution metadata in Aurora. Within your Amazon EKS environment (right), the data plane executes workflows that pull customer code from your container registry, access secrets from AWS Secrets Manager, and read/write data to your S3 buckets—with the execution logs flowing to both CloudWatch and the Union control plane for observability.
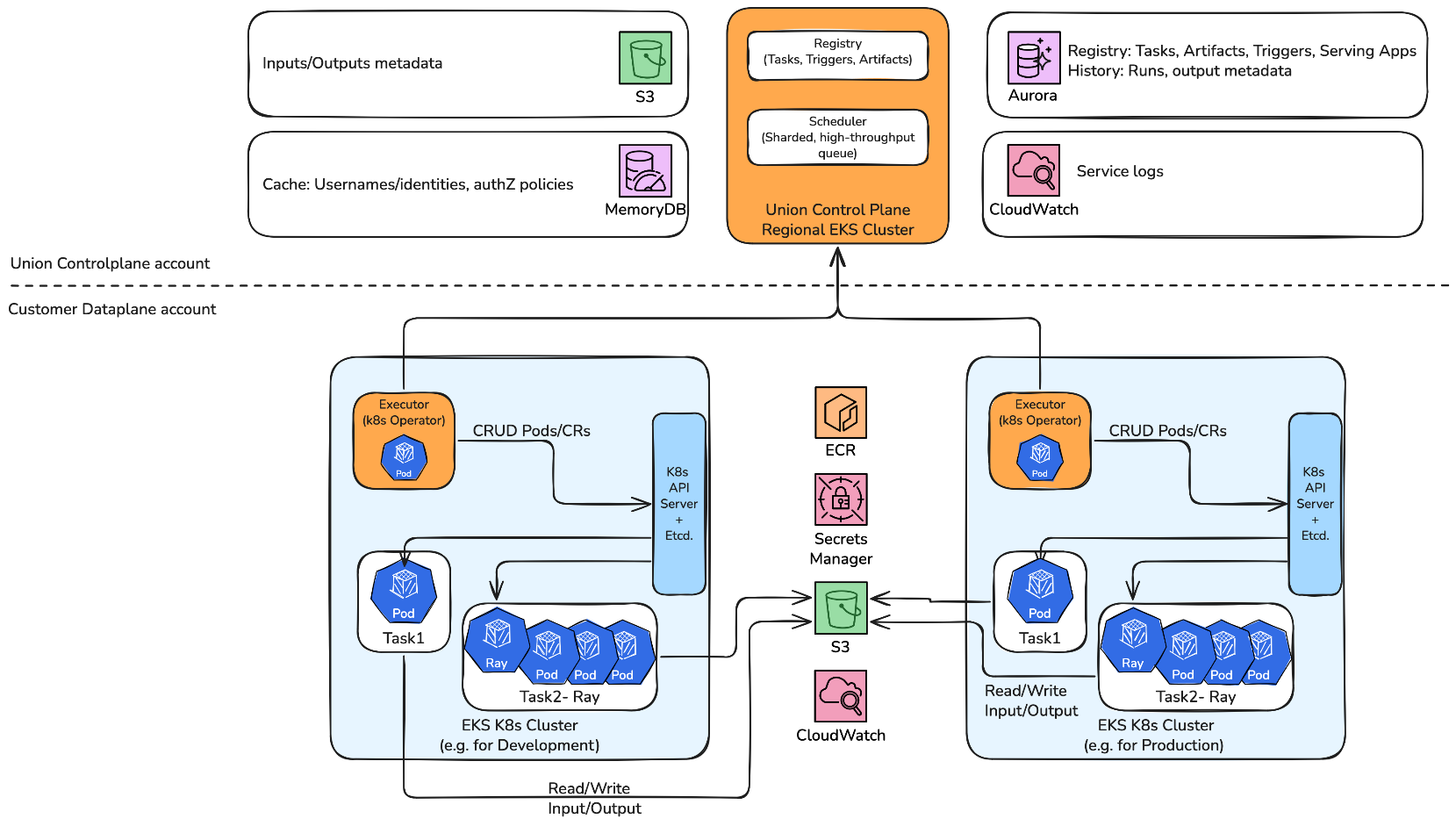
Union.ai 2.0’s AWS integration architecture is built on six key service components that provide end-to-end workflow management:
- Control plane and data plane – The control plane operates within the Union.ai AWS account and serves as the central management interface, providing users with authentication and authorization capabilities, observation and monitoring functions, and system management tools. It also orchestrates execution placement on data plane clusters and handles cluster control and management operations. Union.ai 2.0 maintains one control plane per AWS Region, managing the Regional data planes. Available Regions for data plane deployment include
us-west,us-east,eu-west, andeu-central, with ongoing expansion to additional Regions. - Data plane object store – This component stores data comprising files, directories, data frames, models, and Python-pickled types, which are passed as references and read by the control plane.
- Container registry – This component contains registry data that include names of workflows, tasks, launch plans, and artifacts; input and output types for workflows and tasks; execution status, start time, end time, and duration of workflows and tasks; version information for workflows, tasks, launch plans, and artifacts; and artifact definitions. With the Union.ai 2.0 architecture, you can retain full ownership of your data and compute resources while it manages the infrastructure operations. The Union.ai 2.0 operator resides in the data plane and handles management tasks with least privilege permissions. It enables cluster lifecycle operations and provides support engineers with system-level log access and change implementation capabilities—without exposing secrets or data. Security is further strengthened through unidirectional communication: the data plane operator initiates the connections to the control plane, not the reverse.
- Logging and monitoring – CloudWatch provides centralized logging and monitoring through deep integration with Flyte. The system automatically builds logging links for each execution and displays them in the console, with links pointing directly to the AWS Management Console and the specific log stream for that execution—a feature that significantly accelerates troubleshooting during failures.
- Security – Security is handled through IAM roles for service accounts (IRSA), which maps the identity between Kubernetes resources and the AWS services they depend on. These configurations enable more secure, fine-grained access control for backend services, and Union.ai 2.0 adds enterprise role-based access control (RBAC) for user access control on top of these AWS security features.
- Storage layer – Amazon S3 serves as the durable storage layer for workflows and data. When you register a workflow with Flyte, your code is compiled into a language-independent representation that captures the workflow definition, input, and output types. This representation is packaged and stored in Amazon S3, where FlytePropeller—Flyte’s execution engine—retrieves it to instruct the respective compute framework (such as Kubernetes or Spark) to run workflows and report status. Raw input data used to train and validate models is also stored in Amazon S3. Union.ai 2.0 now includes a new integration with Amazon S3 Vectors, enabling vector storage for Retrieval Augmented Generation (RAG), semantic search, and agentic AI workflows.
With this robust infrastructure in place, Union.ai 2.0 on Amazon EKS excels at orchestrating a wide range of AI/ML workloads. It handles large-scale model training by orchestrating distributed training pipelines across GPU clusters with automatic resource provisioning and spot instance support. For data processing, it can process petabyte-scale datasets with dynamic parallelism and efficient task fanout, scaling to 100,000 task fanouts with 50,000 concurrent actions in Union.ai 2.0. By using Union.ai 2.0 and Flyte on Amazon EKS, you can build and deploy agentic AI systems—long-running, stateful AI agents that make autonomous decisions at runtime. For production deployments, it supports real-time inference with low-latency model serving, using reusable containers for sub-100 millisecond task startup times. Throughout the entire process, Union.ai 2.0 provides comprehensive MLOps and model lifecycle management, automating everything from experimentation to production deployment with built-in versioning and rollback capabilities.
These capabilities are exemplified in specialized implementations like distributed training on AWS Trainium instances, where Flyte orchestrates large-scale training workloads on Amazon EKS.
Deployment options for Union.ai 2.0 on Amazon EKS
Union.ai 2.0 and Flyte offer three flexible deployment models for Amazon EKS, each balancing managed convenience with operational control. Select the approach that best fits your team’s expertise, compliance requirements, and development velocity:
- Union BYOC (fully managed) – The fastest path to production. Union.ai 2.0 manages the infrastructure, upgrades, and scaling while your workloads run in your AWS account. This option is ideal for teams that want to focus entirely on AI development rather than infrastructure operations.
- Union Self Managed – You can deploy Union.ai 2.0’s managed control plane while maintaining control of your data and compute resources in your AWS account. This option combines the benefits of managed services with data sovereignty and governance requirements.
- Flyte OSS on Amazon EKS – You can deploy and operate open source Flyte directly on your EKS cluster using the AWS Cloud Development Kit (AWS CDK). This option provides maximum control and is ideal for teams with strong Kubernetes expertise who want to customize their deployment. (edited)
The Amazon EKS Blueprints for AWS CDK Union add-on helps AWS customers deploy, scale, and optimize AI/ML workloads using Union on Amazon EKS. It provides modular infrastructure as code (IaC) AWS CDK templates and curated deployment blueprints for running scalable AI workloads, including:
- Model training and fine-tuning pipelines
- Large language model (LLM) inference and serving
- Multi-model deployment and management
- Agentic AI pipeline orchestration
Union.ai 2.0 and Flyte provide IaC templates for deploying on Amazon EKS:
- Terraform modules – Preconfigured modules for deploying Flyte on Amazon EKS with best practices for networking, security, and observability
- AWS CDK support – AWS CDK constructs for integrating Union into existing AWS infrastructure
- GitOps workflows – Support for Flux and ArgoCD for declarative infrastructure management
The Union add-on is available by blog publication, and the Flyte add-on is coming—keep watching the GitHub repo.
These templates automate the provisioning of EKS clusters, node groups (including GPU instances), IAM roles, S3 buckets, Aurora databases, and the required Flyte components.
Prerequisites
To start using this solution, you must have the following prerequisites:
- An AWS account with appropriate permissions.
- Amazon EKS version on standard support.
- Required IAM roles. Using IAM roles for service accounts, Flyte can map identity between the Kubernetes resources and AWS services it depends on. These configurations are for the backend and do not interfere with user-control plane communication
How Union.ai 2.0 supports Amazon S3 Vectors
As AI applications increasingly rely on vector embeddings for semantic search and RAG, Union.ai 2.0 empowers teams with Amazon S3 Vectors integration, simplifying vector data management at scale. Built into Flyte 2.0, this feature is available today. Amazon S3 Vectors delivers purpose-built, cost-optimized vector storage for semantic search and AI applications. With Amazon S3 level elasticity and durability for storing vector datasets with subsecond query performance, Amazon S3 Vectors is ideal for applications that need to build and grow vector indexes at scale. Union.ai 2.0 provides support for Amazon S3 Vectors for RAG, semantic search, and multi-agent systems. If you’re using Union.ai 2.0 today with Amazon S3 as your object store, you can start using Amazon S3 Vectors immediately with minimal configuration changes.
To set it up, use Boto’s dedicated APIs to store and query vectors. Your Amazon S3 IAM roles are already in place. Just update the permissions.
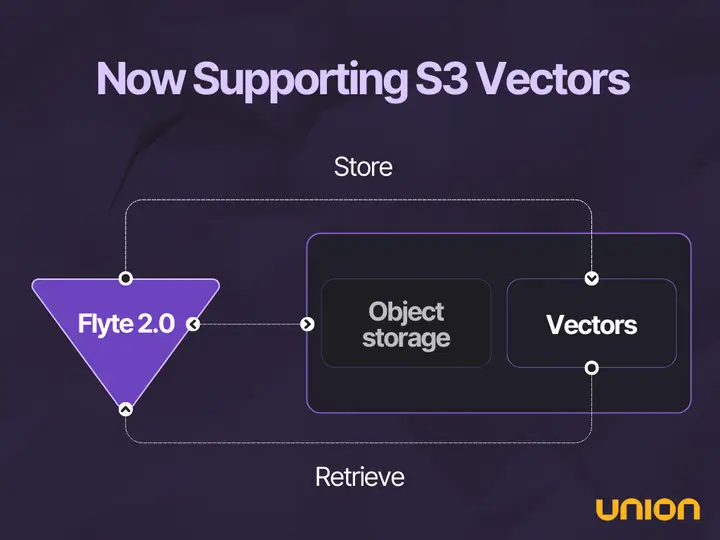
By combining Flyte 2.0’s orchestration with Amazon S3 Vector support, multi-agent trading simulations can scale to hundreds of agents that learn from historical data, share industry insights, and execute coordinated strategies in real time. These architectural advantages support sophisticated AI applications like multi-agent systems that require both semantic memory and real-time coordination.
To learn more, refer to the example use case of a multi-agent trading simulation using Flyte 2.0 with Amazon S3 Vectors. In this example, you will learn to build a trading simulation featuring multiple agents that represent team members in a firm, illustrating their interactions, strategic planning, and collaborative trading activities
Consider a multi-agent trading simulation where AI agents interact, test strategies, and continuously learn from their experiences. For realistic agent behavior, each agent must retain context from previous interactions, essentially building a memory of semantic artifacts that inform future decisions. The process includes the following steps:
- After each simulation round, embed the agent’s learnings into vector representations using embedding models.
- Store embeddings in Amazon S3 using Amazon S3 Vectors with appropriate metadata and tags.
- During subsequent executions, retrieve relevant memories using semantic search to ground agent decisions in past experience.
With Flyte 2.0, your agents already run in an orchestration-aware environment. Amazon S3 becomes your vector store. It’s inexpensive, fast, and fully integrated, alleviating the need for separate vector databases. For the steps and associated code to implement the multi-agent trading simulation, refer to the GitHub repo.
In summary, this architecture helps deliver measurable advantages for production AI systems:
- Reduced operational complexity – Consolidate your AI/ML orchestration and vector storage on a single environment, alleviating the need to provision, maintain, and secure separate vector database infrastructure
- Significant cost savings – Amazon S3 Vectors delivers significantly lower storage costs compared to purpose-built vector databases, while providing subsecond similarity search performance at scale
- Zero-friction AWS integration – Use your existing Amazon S3 infrastructure, IRSA configuration, and virtual private cloud (VPC) networking—no additional authentication layers or network configurations are required
- Battle-tested scalability – Build on the 99.999999999% durability and elastic scalability of Amazon S3 to support vector datasets from gigabytes to petabytes without re-architecture
Customer success: Woven by Toyota
Toyota’s autonomous driving arm, Woven by Toyota, faced challenges orchestrating complex AI workloads for their autonomous driving technology, requiring petabyte-scale data processing and GPU-intensive training pipelines. After outgrowing their open source Flyte implementation, they migrated to Union.ai’s managed service on AWS in 2023. The impact was transformative: over 20 times faster ML iteration cycles, millions of dollars in annual cost savings through spot instance optimization, and thousands of parallel workers enabling massive scale.
“Union.ai’s wealth of expertise has enabled us to focus our efforts on key ADAS-related functionalities, move fast, and rely on Union.ai to deliver data at scale,”
– Alborz Alavian, Senior Engineering Manager at Woven by Toyota.
Read the full case study about Woven by Toyota’s migration to Union.ai.
Conclusion
Union.ai and Flyte provide the foundation for reliable, scalable AI on Amazon EKS for your AI/ML workflows, such as building autonomous systems, training LLMs, or orchestrating complex data pipelines.To get started, choose your path:
About the authors
 ND Ngoka is Senior Solutions Architect at AWS with specialized focus on AI/ML and storage technologies. Guides customers through complex architectural decisions, enabling them to build resilient, scalable solutions that drive business outcomes.
ND Ngoka is Senior Solutions Architect at AWS with specialized focus on AI/ML and storage technologies. Guides customers through complex architectural decisions, enabling them to build resilient, scalable solutions that drive business outcomes.
 Samhita Alla is a Senior Solutions Engineer for Partnerships at Union.ai, where she leads the technical execution of strategic integrations across the AI stack, from distributed training and experiment tracking to data platform integrations. She works closely with partners and cross-functional teams to evaluate feasibility, build production-ready solutions, and deliver technical content that drives real-world adoption.
Samhita Alla is a Senior Solutions Engineer for Partnerships at Union.ai, where she leads the technical execution of strategic integrations across the AI stack, from distributed training and experiment tracking to data platform integrations. She works closely with partners and cross-functional teams to evaluate feasibility, build production-ready solutions, and deliver technical content that drives real-world adoption.
 Kristy Cook is Head of Partnerships at Union.ai, where she builds strategic alliances across the AI/ML ecosystem focused on sustained growth. Having forged impactful partnerships at Meta, Yahoo, and Neustar she brings deep expertise in operationalizing AI solutions at scale.
Kristy Cook is Head of Partnerships at Union.ai, where she builds strategic alliances across the AI/ML ecosystem focused on sustained growth. Having forged impactful partnerships at Meta, Yahoo, and Neustar she brings deep expertise in operationalizing AI solutions at scale.
 Jim Fratantoni is a GenAI Account Manager at AWS, focused on helping AI startups scale and co-sell with AWS. He is passionate about working with founders to jointly go to market and drive enterprise customer success.
Jim Fratantoni is a GenAI Account Manager at AWS, focused on helping AI startups scale and co-sell with AWS. He is passionate about working with founders to jointly go to market and drive enterprise customer success.
 Theo Rashid is an Applied Scientist at Amazon building probabilistic machine learning and forecasting models. He is an active open source contributor, and is passionate about open source tooling across the machine learning stack, from probabilistic programming libraries to workflow orchestration. He holds a PhD in Epidemiology and Biostatistics from Imperial College London.
Theo Rashid is an Applied Scientist at Amazon building probabilistic machine learning and forecasting models. He is an active open source contributor, and is passionate about open source tooling across the machine learning stack, from probabilistic programming libraries to workflow orchestration. He holds a PhD in Epidemiology and Biostatistics from Imperial College London.
 Alex Fabisiak is a Senior Applied Scientist at Amazon working on applied forecasting and supply chain problems. He specializes in probabilistic and causal modeling as they relate to optimal policy decisions. He holds a PhD in Finance from UCLA.
Alex Fabisiak is a Senior Applied Scientist at Amazon working on applied forecasting and supply chain problems. He specializes in probabilistic and causal modeling as they relate to optimal policy decisions. He holds a PhD in Finance from UCLA.
Source Credit: https://aws.amazon.com/blogs/machine-learning/build-ai-workflows-on-amazon-eks-with-union-ai-and-flyte/





