
Asking a large language model to generate synthetic data is a reasonable approach to get started. But how realistic is the data? I took the Gemini CLI through a set of experiments to find out.
If you look at the populations of every city on Earth, or the lengths of every river, you’ll find a weirdly consistent pattern. About 30.1% of those numbers start with the digit 1. Only about 4.6% start with a 9.
This is Benford’s Law, also known as the first-digit law. It describes the frequency distribution of leading digits in many real-life sets of numerical data. The law states that in many naturally occurring collections of numbers, the leading significant digit is likely to be small. The mathematical reason for this is that many natural processes are multiplicative rather than additive. Populations, stock prices, and city sizes grow by a percentage of their current value.

In forensic accounting, this law is a powerful tool. By comparing a dataset’s leading digits to the Benford distribution, auditors can quickly flag unnatural data for further investigation.
A baseline with real-world estimates
I started with a simple experiment. I asked Gemini to list the estimated populations of 250 random cities around the world. I wanted to see if the model’s internal knowledge of real-world data followed the first-digit law.
The setup was straightforward. I used a Python script to call the CLI, using the Gemini 3 Flash Preview model:
# Initial experiment call
prompt = "List the estimated populations of 250 random cities. Format: 'City: 123456'."
result = subprocess.run(["gemini", "ask", prompt], capture_output=True, text=True)
At first glance, the results weren’t too far off! You can see that there’s a spike with the digit 5, where the model mimics a human habit of rounding to the nearest 5 known as heaping.
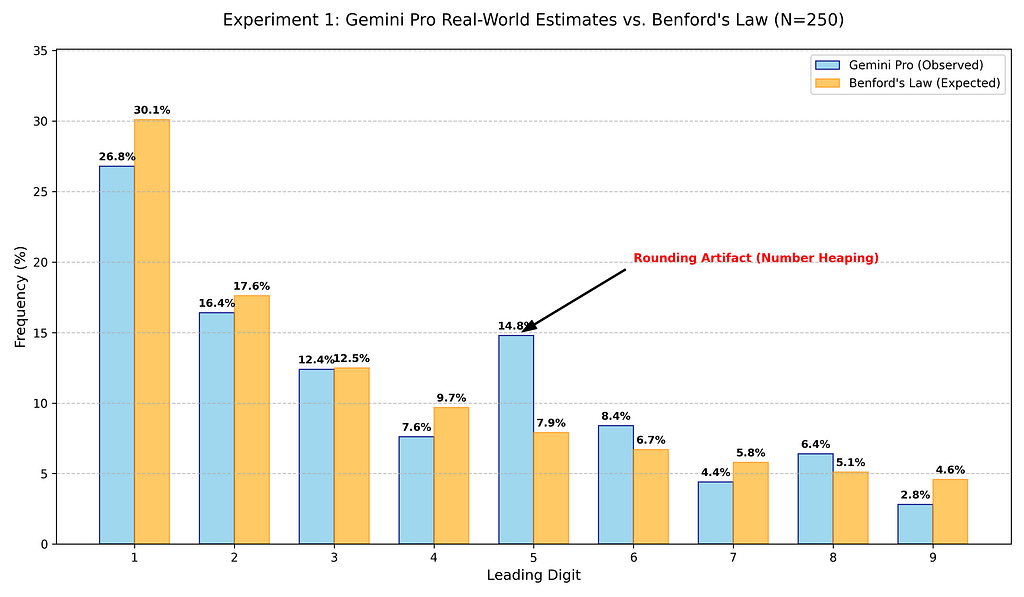
Experiments with Gemini 3 models
You might note that Gemini is simply recalling the existing population of cities, which should already follow Benford’s Law. In the next experiment, updated the experiment design to generate new data for fictional interplanetary cities.
Also, to avoid the rounding issue we saw with the leading digit 5, I would ask for “exact, unrounded” answers.
I used 10 batches of 100 items each, with unique random seeds and varying the planetary biome (e.g., “Volcanic Archipelago”) in each prompt.
# Batching logic with contextual seeding
for i in range(10):
biome = BIOMES[i]
prompt = f"Generate 100 fictional settlements in the {biome} of Zephyr-9. Provide exact, unrounded populations."
# API call follows...
We see that Gemini overweighted the leading digit of 1 compared to random chance (1/9), but the results look way off from the expected distribution. A chi-squared test with eight degrees of freedom gave a p-value of 0.000, confirming that the distribution did not match.
I tried the same experiment across other Gemini models: Gemini 3.1 Flash Lite Preview and Gemini 3.1 Pro Preview. Same conclusion: far from a match.
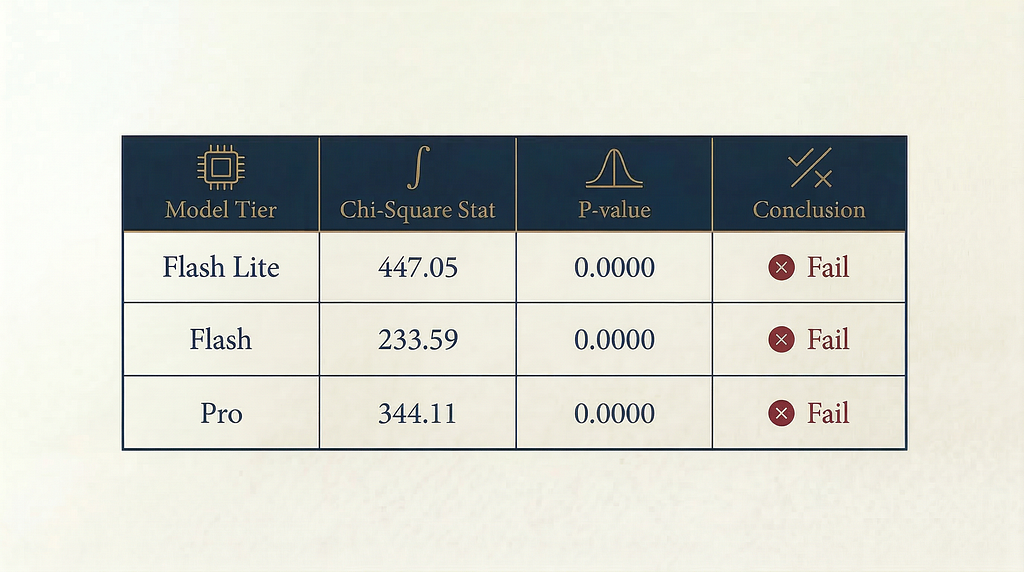
Prompt calibration
In my final experiment, I provided the expected distribution in the prompt:
# Calibration constraint
BENFORD_DIST = "1: 30.1%, 2: 17.6%, 3: 12.5%, 4: 9.7%, 5: 7.9%, 6: 6.7%, 7: 5.8%, 8: 5.1%, 9: 4.6%"
prompt = f"Generate 100 settlements. Follow this distribution: {BENFORD_DIST}."
This worked well! The p-value from this chi-squared test was 0.97, showing that the model’s instruction-following capability is high enough to manually override its internal biases.
While the generated data adheres to Benford’s law for the leading digit, it doesn’t necessarily mean it resembles natural data. We can extend this analysis to second and third digits, and apply other statistical tests that may fail.
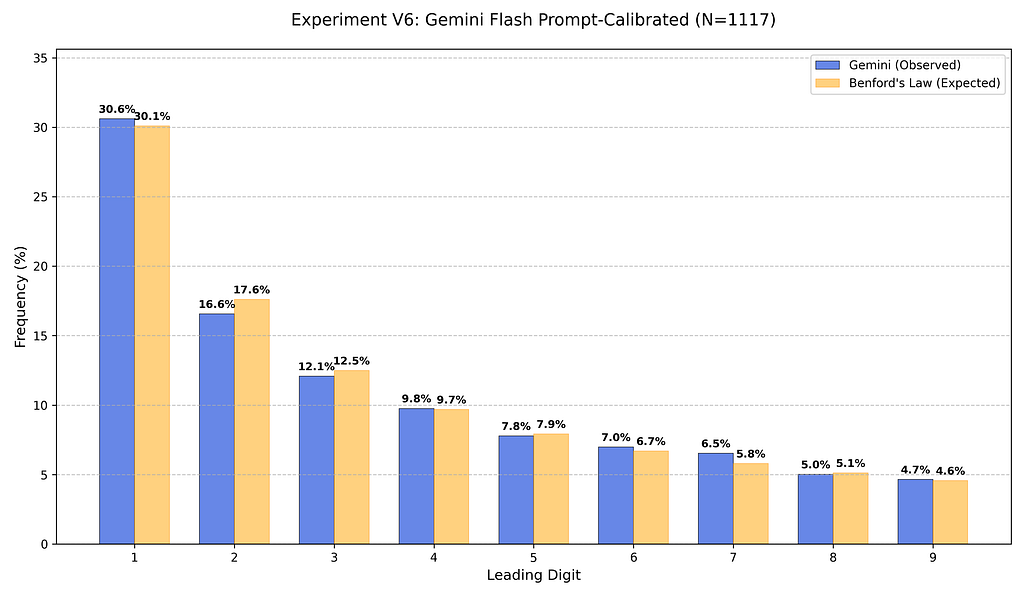
The engineering solution: Tool-augmented generation
Even with prompt calibration, the results are fragile. My recommendation is to treat the LLM as a planner. Use the model to define the logic of your world — the names of the cities, the biomes, the economy — but use tools and function calling to produce the numbers.
Instead of asking for 1,000 populations, you could ask the model to define the parameters (like the mean and standard deviation) for a distribution and then trigger a Python script to sample from a true numpy.random.lognormal distribution.
Gemini is a master of language, but natural data follows statistical laws. To build a world that feels real, you have to bridge that gap with code.
I’d love to hear how you’re working with synthetic data. Let’s keep the conversation going over on X, LinkedIn, or Bluesky.
https://medium.com/media/c0bb7ca470eb93041b1d3e7027fe977f/href
Do Large Language Models follow Benford’s Law? was originally published in Google Cloud – Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source Credit: https://medium.com/google-cloud/do-large-language-models-follow-benfords-law-c47c9f0f9070?source=rss—-e52cf94d98af—4


")
