
Biological intelligence experienced its greatest leap not when early humans learned to use a stone to crack a nut, but when they started using skills to build new tools or even learn new skills.
Today, AI agents are stuck in the “using the stone” phase. We have transitioned from LLMs that simply answer questions to agents that can execute pre-defined business specific workflows, largely thanks to portable standards like agentskills.io. This open standard allows us to equip our agents with modular, on-demand capabilities via simple SKILL.md files.
But there is a glaring bottleneck in how we build AI today: agents are still entirely dependent on humans to author those skills.
When faced with an undocumented API or a sudden schema change, static skill loading breaks. If we want to build highly autonomous, resilient systems — the true origin of machine intelligence — our agents must move beyond merely using skills. They must dynamically author them based on situational necessity.
Here is how we design meta-cognitive agent skills, allowing our systems to permanently learn, adapt, and rewrite their own operational memory.
The Meta-Cognitive Architecture
True machine intelligence requires meta-cognition — the ability for a system to monitor its own thought processes, evaluate its performance, and permanently codify successful strategies. By treating the agentskills.io standard as mutable, agent-authored memory, we can create systems that self-heal.
The architecture follows a strict, self-correcting feedback loop:
Agent → Skills → Failure → Asset Analysis → LLM Generation → New Skill.
To see how this works in practice, let’s look at two production-grade scenarios: security vulnerability regression and data pipeline healing.
Use Case 1: Dynamic Vulnerability Regression
In security engineering, targets constantly evolve. Imagine an autonomous agent tasked with continuously verifying a known Broken Object Level Authorization (BOLA) vulnerability on an internal API.
The target engineering team deploys a massive update: endpoints are renamed, and the authentication token is moved from the headers to a signed cookie. A traditional automated scanner fails entirely. Our meta-cognitive agent uses this failure as a trigger to learn.
The Workflow
- Execution & Failure: The agent attempts its existing verify-bola-vuln skill. The HTTP request returns a 401 Unauthorized because the API structure changed. The agent catches the stack trace.
- Asset Retrieval: The agent falls back to a fundamental discovery skill. It scrapes the target’s new OpenAPI swagger spec and saves it as an asset template (target_schema.json).
- LLM Generation: The agent constructs a prompt containing the failed SKILL.md, the error trace, and the newly discovered schema.
- Skill Authoring: The LLM generates an updated SKILL.md and a modified Python execution script, adapting to the new cookie-based auth.
The Implementation
Adhering to the agentskills.io philosophy, the agent writes the new memory to its local file system:
agent_directory/
└── skills/
└── verify-bola-vuln/
├── SKILL.md # The agent-authored skill definition
├── exploit.py # The generated execution script
└── target_schema.json # The asset used for context
---
name: verify-bola-vuln
description: "Verifies BOLA on the target API. Updated to handle the v2 schema where auth is handled via signed cookies."
license: Apache-2.0
metadata:
author: sands
version: "1.0"
---
# Vulnerability Verification: BOLA (v2 API)
## Context
The application migrated to `/api/v2/accounts/{id}/profile`. Authentication no longer uses the `Authorization: Bearer` header; it requires a session cookie from `/auth/login`.
## Execution Steps
1. Execute `python3 exploit.py` in this directory.
2. The script will authenticate, grab the cookie, and attempt to fetch account `ID: 002` using the credentials of `ID: 001`.
3. Read stdout. If the script returns data for `ID: 002`, the BOLA vulnerability is still active.
The Pseudocode:
def execute_skill_with_metacognition(skill_name, target_url):
try:
return agent.execute(skill_name)
except SkillExecutionError as failure_trace:
print(f"Skill {skill_name} failed. Initiating self-healing...")
# Fetch the new environment reality (The Asset)
new_asset = agent.tools.fetch_site_schema(target_url)
save_asset_to_workspace(skill_name, new_asset)
# Meta-Cognitive LLM Call
healing_prompt = f"""
Skill '{skill_name}' failed with trace: {failure_trace}.
New target schema: {new_asset}.
Rewrite the SKILL.md and Python script to adapt.
"""
new_skill_files = llm.generate(healing_prompt)
# Hot-reload and retry
agent.workspace.overwrite_skill(skill_name, new_skill_files)
agent.reload_skills()
return agent.execute(skill_name)
The Challenges
- Execution Safety: Allowing an agent to dynamically author and immediately execute scripts is a security risk. Generated skills must be sandboxed (e.g., in an isolated Docker container) during the verification phase.
- Context Exhaustion: Throwing a 10,000-line OpenAPI spec into the prompt will blow out the context window and defeat the primary purpose of havings skills , the prompt bloat. The agent needs an intermediate step to slice the asset down to the relevant failing component before asking the LLM to write a new skill.
Use Case 2: Autonomous Data Pipeline Healing
Schema evolution is a massive pain point in data engineering. Imagine an agentic workflow ingesting high-velocity JSON telemetry into a columnar database like ClickHouse.
An upstream team pushes an update, changing a core telemetry field from a standard string format ("status": "200") to a nested object ("status": {"code": 200, "msg": "OK"}). The static ingest-telemetry skill crashes with a type mismatch. Instead of paging an on-call engineer at 2 AM, the pipeline self-heals.
The Workflow
- Execution & Failure: The database driver throws a Type mismatch error during batch insertion.
- Dual Asset Retrieval: The agent saves the malformed incoming JSON payload as Asset A. It then queries ClickHouse’s system.columns table to fetch the current destination schema, saving it as Asset B.
- LLM Generation: The agent prompts the LLM with the failed ingestion script, the error trace, the new JSON reality, and the current DB reality.
- Skill Authoring: The LLM rewrites the Python parsing logic to flatten the nested object, updates the SKILL.md, and commits the new skill.
The Implementation
agent_directory/
└── skills/
└── ingest-telemetry/
├── SKILL.md # The updated ingestion logic
├── parse_and_load.py # Regenerated python script
├── incoming_sample.json # Asset A: The new reality
└── db_schema.json # Asset B: The current DB state
The dynamically generated SKILL.md:
---
name: ingest-telemetry
description: "Consumes JSON telemetry into the logs_buffer table. Updated to flatten nested status objects."
license: Apache-2.0
metadata:
author: sands
version: "1.0"
---
# Telemetry Ingestion (Schema Drift Adaptation)
## Context
Upstream services transitioned the `status` field to a nested JSON object containing `code` and `msg`. The downstream ClickHouse table expects flat columns.
## Execution Steps
1. The `parse_and_load.py` script intercepts the payload.
2. It extracts `payload['status']['code']` and maps it to `status_code`.
3. Transformed batch is inserted.
The Pseudocode:
def heal_data_pipeline(skill_name, failed_payload, error_trace):
print(f"Pipeline stalled. Initiating meta-cognition...")
# Gather Assets (The Reality Check)
upstream_asset = save_to_workspace("incoming_sample.json", failed_payload)
downstream_schema = db.execute("SELECT name, type FROM system.columns WHERE table='logs_buffer'")
db_asset = save_to_workspace("db_schema.json", downstream_schema)
# Meta-Cognitive LLM Call
healing_prompt = f"""
Skill '{skill_name}' failed with: {error_trace}.
Incoming data: {upstream_asset}. Current DB schema: {db_asset}.
Rewrite 'parse_and_load.py' to bridge this schema drift.
Update 'SKILL.md'. DO NOT execute destructive DDL.
"""
new_pipeline_files = llm.generate(healing_prompt)
# Reload and Resume
agent.workspace.overwrite_skill(skill_name, new_pipeline_files)
agent.reload_skills()
return agent.execute(skill_name)
The Challenges
- Destructive Operations: An LLM might decide the “easiest” fix is an ALTER TABLE DROP COLUMN command. Agents managing data infrastructure require strict RBAC injected into their system prompts, explicitly forbidding destructive DDL execution.
- Data Loss During the Loop: While the agent takes 45 seconds to write a new skill, telemetry is still streaming. The architecture must include a Failover Skill that routes unparseable data to a Dead Letter Queue (DLQ) so no events are dropped while the agent is “thinking.”
The Architectural Crossroads: Implementing the “Self-Healer”
As you scale these meta-cognitive systems, the primary engineering concern shifts from capability to governance. How do we ensure that an agent generating its own logic doesn’t introduce catastrophic regressions or security vulnerabilities?
The mechanism by which a skill invokes its own evolution dictates the system’s threat model and long-term maintainability. Here are the four architectural patterns for invoking the reasoning layer, evaluated for production readiness.
1. The Direct SDK Pattern: “Fat Skills” (Anti-Pattern)
In this pattern, the execution script imports the LLM provider’s SDK directly. The skill manages its own lifecycle, catching its own exceptions, and calling the LLM to rewrite itself.
- Architecture: Tight coupling. The execution logic and the meta-cognitive logic share the same process space.
- Staff Perspective: This is a production anti-pattern. It leads to Secret Sprawl, requiring raw API keys to be injected into environments where dynamically generated (and potentially unsafe) code is actively executing. Furthermore, it creates severe Observability Gaps. Centralized tracking of token usage, cost allocation, and prompt versioning becomes nearly impossible when thousands of discrete scripts are making out-of-band network calls to an LLM provider.
2. The Agentic Callback: “Inversion of Control”
Here, the skill script acts purely as a deterministic diagnostic probe. Upon failure, it does not attempt to heal itself. Instead, it packages the execution trace and the new asset reality into a structured payload, yields it to stdout, and exits with a specific state code (e.g., Exit 42).
- Architecture: Event-driven bubbling. The Host Agent (the supervisor) catches the exit code, parses the state, and orchestrates the LLM call.
- The Staff Perspective: This successfully achieves Inversion of Control (IoC). The host retains the absolute “Right to Mutate.” This is excellent for Governance, as you can implement a strict Human-in-the-Loop (HITL) or CI/CD gate at the host level before the new SKILL.md is committed. The drawback is that it forces the host runtime to become heavily opinionated, tightly coupling your infrastructure to a bespoke event loop.
3. The Local Proxy Pattern: “Sidecar Reasoning”
The host agent provisions a lightweight, local API gateway (a sidecar) alongside the execution environment. The skill script (whether written in Bash, Go, or Python) issues a standard curl or REST call to localhost:8080/heal to request an updated script.
- Architecture: Out-of-process, decoupled execution mirroring a Service Mesh pattern.
- The Staff Perspective: This solves the language-agnostic problem and centralizes rate limiting. However, it introduces a complex network security perimeter. If the local proxy lacks strict host validation and input sanitization, a compromised or hallucinated script could be manipulated into executing Server-Side Request Forgery (SSRF) or DNS rebinding attacks against the proxy itself, potentially exposing internal infrastructure or hijacking the reasoning engine.
4. The MCP Native Pattern: Standardized Capability Negotiation (The Gold Standard)
Instead of building custom callbacks or proxies, this architecture leverages the Model Context Protocol (MCP). The host agent (e.g., Gemini) handles the non-deterministic reasoning, while an isolated MCP server manages the deterministic file-system mutations.
Deconstructing the Unified Architecture: As shown in the architecture above, we eliminate the anti-pattern of a separate “Reasoning Engine.” The Host Agent consolidates both inference and tool orchestration. When a skill fails in the target environment (e.g., catching an HTTP 401), the error trace and the new reality (the updated OpenAPI schema) flow directly back into the Host Agent’s context window.
- The Meta-Cognitive Turn (Internal): The Host Agent doesn’t just guess the fix. It can use read-only MCP tools to fetch more context (like pulling the full HTML DOM or querying the DB schema) to inform its internal LLM instantiation.
- The File Mutation Boundary (External): Once the Host Agent generates the new_SKILL.md and updated scripts, it does not write them itself. It hands the payload to an isolated MCP Tool Runner.
So, the architecture leverages MCP in two distinct, critical ways:
- Architecture: Protocol-driven decoupling. The skill fails natively, the host agent observes the failure in its standard tool-call loop, and then uses a separate regenerate_skill MCP tool to overwrite the local .agents/skills/ directory.
- The Staff Perspective: This is the only highly scalable, enterprise-grade solution. It establishes a strict Capability Boundary. The LLM operates entirely in the reasoning plane; the MCP server operates in the execution plane. Because MCP enforces standardized capability negotiation, you can apply granular Role-Based Access Control (RBAC) with IAP(Authentication & Authorization) — ensuring the reasoning engine can only overwrite files within the .agents/skills/ path and absolutely nothing else. It also provides a systemic audit trail, turning self-healing from a rogue script execution into a heavily logged, GitOps-ready protocol event.
Architectural Trade-off Matrix
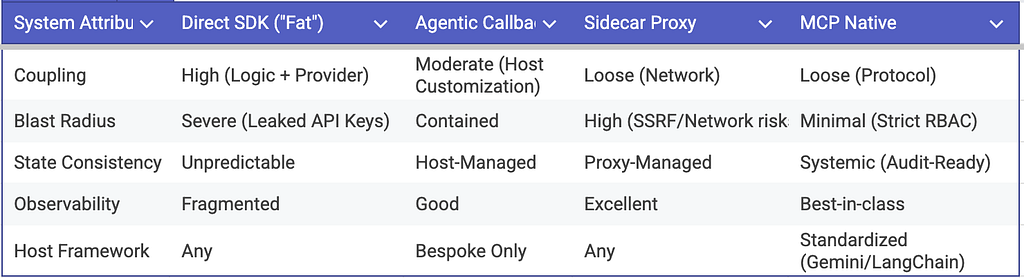
A Note on “The Lobotomy Problem”: To prevent an agent from hallucinating and accidentally overwriting its own ability to self-heal, you must enforce strict architectural separation. Mutable task logic (the SKILL.md) lives in user-space, while the meta-cognitive capability to mutate those files must remain an immutable, system-space tool protected behind the MCP boundary.
Beyond the Basics: Meta-Cognition at Enterprise Scale
While vulnerability scanning and data ingestion perfectly illustrate the mechanics of meta-cognition, the true ROI of this architecture is realized when it is deployed against an enterprise’s most expensive operational bottlenecks: configuration drift, platform migrations, and alert fatigue. Once you establish a secure, MCP-backed capability boundary, your agentic fleet can safely tackle systemic infrastructure challenges that typically require weeks of human toil. Here are three advanced, production-grade scenarios where self-authoring skills transform fragile operations into resilient, self-healing systems.
Use Case 3: Kubernetes API Deprecation & Fleet Upgrades
Managing large-scale container orchestration involves constant battles with API versioning. When a cluster is upgraded, legacy deployment scripts often break.
Imagine an autonomous deployment agent responsible for rolling out microservices across different environments.
- The Failure: The cluster is upgraded, and Kubernetes deprecates a specific API resource (e.g., migrating an Ingress controller from networking.k8s.io/v1beta1 to networking.k8s.io/v1). The agent’s standard deploy-service skill crashes with an API mismatch error.
- The Asset Retrieval: The agent queries the cluster’s native API server to fetch the updated OpenAPI specifications for the active cluster version.
- The Meta-Cognitive Fix: The Host Agent analyzes the failed manifest against the new cluster specs. It uses an MCP tool to rewrite the SKILL.md and the underlying YAML generation script to automatically map legacy configuration syntax to the new v1 standard.
- The Enterprise Value: Zero-downtime fleet upgrades without requiring a massive, multi-week human effort to manually audit and update hundreds of discrete deployment scripts.
Use Case 4: Network Observability & Telemetry Drift
In large-scale network environments, agents are increasingly used to monitor high-velocity event streams for anomalies.
Imagine an agentic workflow consuming network telemetry data from an Apache Kafka topic to identify routing loops or latency spikes.
- The Failure: A core switch receives a firmware update, which silently alters the structure of the JSON payload being published to the Kafka topic (e.g., nesting a previously flat IP array). The agent’s parse-network-events skill starts dropping messages due to schema validation failures.
- The Asset Retrieval: The agent captures the dead-letter payload and queries the enterprise Schema Registry (or introspects the raw Kafka message headers) to understand the new data contract.
- The Meta-Cognitive Fix: The agent rewrites its Python parsing logic to unnest the new array, updates the SKILL.md with a note on the firmware-induced schema drift, and hot-reloads the capability.
- The Enterprise Value: Continuous, uninterrupted observability. Network operations teams no longer suffer from “blind spots” simply because a vendor changed a logging format.
Use Case 5: Dynamic Zero-Trust Policy Generation
Securing enterprise AI applications and distributed systems requires policies that adapt faster than static rulesets allow.
Imagine a security agent tasked with enforcing least-privilege access between internal microservices.
- The Failure: A development team deploys a new internal AI agent that needs to dynamically query a vector database. The traffic is blocked by the default deny policy, triggering a flurry of access-denied alerts, and the new agent fails to operate.
- The Asset Retrieval: The security agent retrieves the blocked traffic logs and cross-references the source IP/identity with the internal developer portal or CI/CD metadata to verify the new application’s intended architecture.
- The Meta-Cognitive Fix: Recognizing this as a legitimate new internal workflow, the security agent authors a new SKILL.md that generates a highly scoped, temporary access policy for that specific service account, applies it, and alerts the security team of the automated remediation.
- The Enterprise Value: It eliminates the friction between rapid application development and strict security posture. Developers aren’t blocked waiting days for a firewall ticket, and security maintains absolute, auditable control via the newly written skill definitions.
The Future: Self-Expanding Agentic Fleets
By closing the loop between execution failure and skill documentation, we transform AI from static software into evolving digital workers.
Because the agentskills.io standard is lightweight and text-based, a skill generated by an agent fixing a broken pipeline can instantly be committed to a centralized Git repository. Within seconds, every other agent in your enterprise fleet pulls the new SKILL.md and instantly "learns" the capability.
This is the origin of machine intelligence: not just reasoning through a novel problem, but expanding the systemic cognitive framework so that the problem is never “novel” again.
Opinions expressed are my own in my personal capacity and do not represent the views, policies or positions of my(or, anyone else’s) employers(current and exes) or its subsidiaries or affiliates.
While the industry is busy chasing ‘vibes’ and better prompt engineering, I’m fortunate to be part of a group defining the architectural patterns that define machine cognition and meta-cognition. If you’re still hard-coding your agent’s ‘thinking,’ maybe it’s time to stop vibing and start architecting. Think hard.
Origin of Machine Intelligence: Designing Meta-Cognitive Agent Skills was originally published in Google Cloud – Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source Credit: https://medium.com/google-cloud/designing-meta-cognitive-agent-skills-ce9db69821d9?source=rss—-e52cf94d98af—4

")

