
Introduction: The Document Deluge in Finance
In fast-paced sectors like loan origination, the flood of documents — bank statements, tax forms, and IDs — is a constant operational challenge. Manual processing is not just slow; it’s a costly bottleneck prone to human error that directly delays loan approvals and frustrates customers. The goal is to move beyond this legacy process and build an innovative, automated solution that works at scale.
This post walks through a demonstration application built to tackle this exact problem. But more than just a technical walkthrough, it’s a case study in architectural philosophy: showing how pragmatic design choices, combined with the strategic use of new AI features, enable the rapid delivery of a robust, intelligent document processing MVP primed for scalable evolution. We’ll explore how it classifies loan documents and extracts key data using Google’s powerful new Gemini 3 Flash model.
The Game Changer: Why Gemini 3 Flash?
Gemini 3 Flash is a new model that fundamentally changes the cost-benefit analysis for building intelligent applications. It combines the advanced reasoning of larger models with the speed and efficiency needed for production systems.
Based on the official developer guide, its key capabilities for this use case include:
- Pro-Level Intelligence: It delivers Pro-level intelligence at the speed and favorable pricing of a lightweight model, making it ideal for high-throughput production systems.
- Exceptional Speed and Cost: It is designed for high-throughput applications, with favorable pricing and a free tier available in the Gemini API, making it ideal for an MVP.
- New Developer Controls: It introduces new parameters like thinking_level, giving developers more granular control over the model's performance and latency.
The Surprising Secret to Better, Faster Document OCR
One of the most impactful new features in Gemini 3 for document processing is the media_resolution parameter.
While it might seem logical to always use the highest possible resolution for better Optical Character Recognition (OCR), the Gemini 3 developer guide reveals a crucial, counter-intuitive insight:
“Optimal for document understanding; quality typically saturates at medium. Increasing to high rarely improves OCR results for standard documents."
This is a game-changer for developers. It means we can achieve high-quality data extraction from PDFs while significantly reducing token costs and processing latency. By using the medium setting, the system becomes more efficient and cost-effective without sacrificing accuracy—a critical advantage for a scalable solution.
The Mission: An MVP for Intelligent Loan Processing
The objective was to build a Minimum Viable Product (MVP) that could intelligently process a variety of loan documents. The application was designed with several core functions to create a complete, end-to-end workflow.
- Classify Documents: Automatically tag uploaded PDFs into specific types, such as Bank Statement, W-9, Government ID, or a multi-page Certificate of Insurance.
- Extract Key Data: Pull specific data fields from each document — like account_holder_name or policy_number—into a structured JSON format.
- Score Confidence: Assign a confidence score (from 0 to 1) to the document classification and to each individual extracted field.
- Human-in-the-Loop (HITL): If any confidence score falls below a configurable threshold, the document is automatically routed to a human operator for review and correction via a simple UI.
- Measure and Learn: Display live operational metrics on a dashboard and implement a feedback loop that stores and uses human corrections (e.g., reclassifying a document or fixing an extracted field) as few-shot examples to improve the accuracy of subsequent processing runs.
Our Blueprint: A Pragmatic MVP Architecture
To maximize time-to-market, the MVP architecture was a strategic choice that de-risked the initial build by intentionally keeping it simple and pragmatic. The technology stack was chosen to enable rapid development and eliminate operational overhead.
Architecture & Components:
- Modular Monolith: The entire system resides in a single repository and runs in a single process, eliminating DevOps operational complexity.
- AI Engine: Multimodal LLMs with Few-Shot Prompting unify document classification and data extraction.
- Interface (HITL): Streamlit (Python) is used for agile development of the Human-in-the-Loop workflow.
- Persistence: Firestore is used for storing results and metrics.
Relevant Quality Attributes:
- Performance: The system must have a response time of under 30 seconds for classification and extraction.
- Performance: The system must have a dashboard load time of under 5 seconds.
- Portability: The system must be accessible via major web browsers.
- Security: The system must mask sensitive data in logs.
- Maintainability: The system must be modular to facilitate maintenance.
- Availability: The system must be available during business hours.
Trade-offs & Limitations:
- Scalability: Tight coupling prevents independent scaling of resources (CPU vs. I/O) within each module. It does not allow for granular component scaling.
- External Dependency: Reliance on third-party APIs introduces variable costs and a risk of vendor lock-in.
The key trade-off with this approach is that the tight coupling of a monolithic architecture prevents granular, independent scaling of system components. This was a conscious choice to prioritize development speed for the initial MVP.
C4 Model
To help visualize this, you can think of the Context as a map of a whole city (who lives there and where they go), the Container as a map of a specific building (the different rooms and utilities), and the Component as a blueprint of the machinery inside one of those rooms (the individual gears and circuits)
System Context Diagram
This diagram provides a high-level overview of the system’s ecosystem. The Loan Officer is the primary user who interacts with the Loan Origination System to review and validate document information. To perform its core functions, the system communicates with two external software systems: a Large Language Model (LLM) for document classification and data extraction (Gemini 3 Flash), and a Data Loss Prevention (DLP) API to protect sensitive data.

Container Diagram
This level describes the high-level technology choices and the distribution of responsibilities. The system is built as a modular monolith consisting of four main containers:
• Loan System UI: A web application developed with Streamlit (Python) that provides an interface for uploading documents and viewing dashboards.
• Loan System Backend: A Python container that houses the business logic, orchestration, and data validation.
• Database: A Firestore instance used to persist user corrections.
• Storage: GCP Cloud Storage is used to store the uploaded loan documents physically

Component Diagram
This diagram zooms into the Loan System Backend to show its internal logical components and their interactions:
• Facade Logic Business: Acts as a simplified interface to coordinate the core services of the backend.
• Document Classifier & Data Extraction: These components handle the specific logic for identifying document types and pulling structured data using the LLM.
• Learning: A specialized module that stores human corrections to feed the learning loop, improving future extraction and classification.
• Dashboard: Contains the logic for aggregating data and metrics for the user interface.
• Commons & Prompts: Shared utilities and a repository for the instructions (prompts) used by the AI engine

The Application in Action: A Step-by-Step Flow
The application provides a seamless flow from document submission to final data validation, integrating the AI engine with a human operator in a production-aware design.
- Document Upload: A Loan Officer uploads a PDF document (e.g., a multi-page bank statement) through the web interface. The backend first securely stores the uploaded PDF in a dedicated object store, such as Google Cloud Storage.
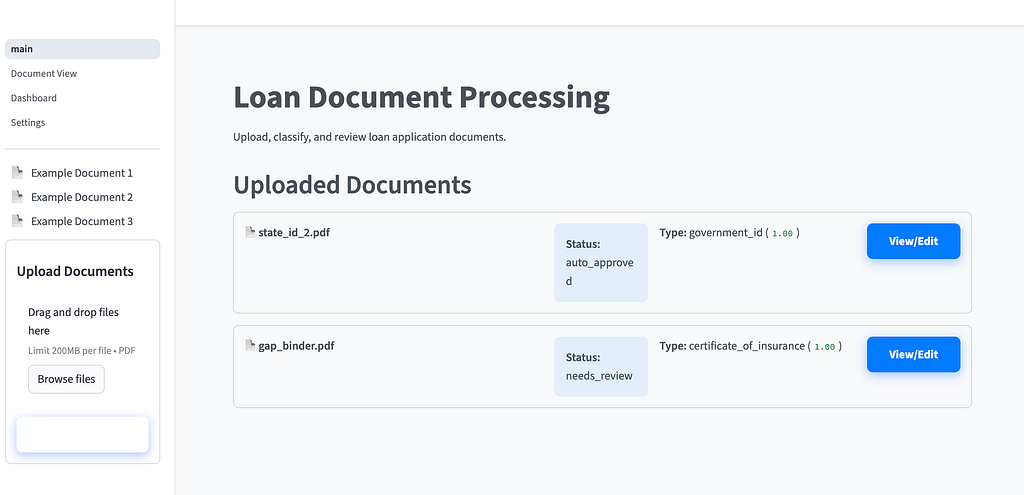
- Classification & Extraction: The backend sends the document to the Gemini LLM, which classifies the document type and extracts relevant fields into a JSON object with confidence scores. Before storing results, the system could optionally call a Data Loss Prevention (DLP) API to mask or redact sensitive information, such as full account numbers, in line with security best practices.
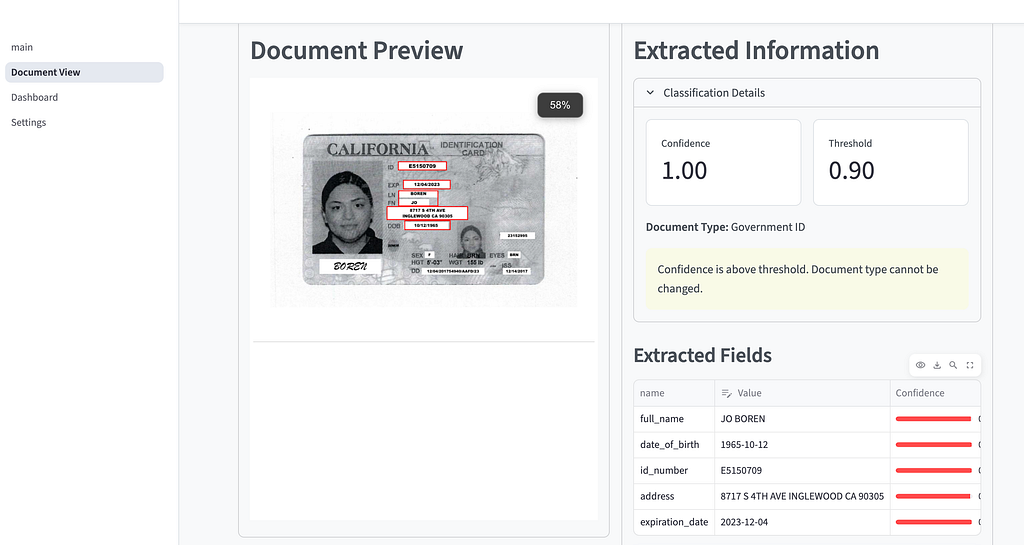

- Human Review (HITL): If confidence scores are below a set threshold, the document is flagged. The Loan Officer uses the UI to review the extracted data, correct any errors, and save the changes.
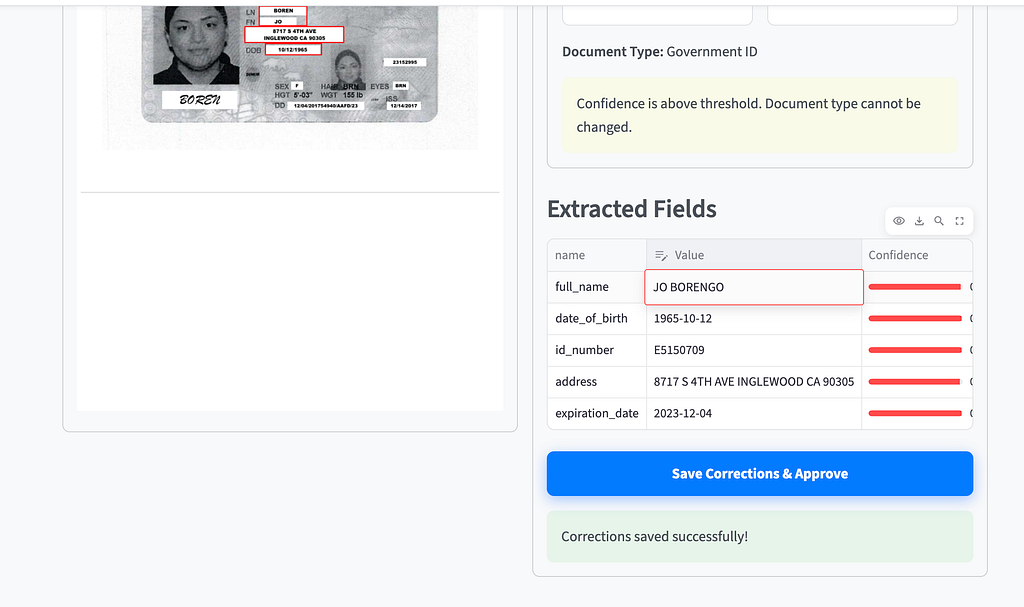
- Learning Loop & Continuous Improvement When a Loan Officer saves corrections during the Human-in-the-Loop (HITL) process, these updates are sent to the Learning module within the backend. The system stores these human-verified corrections — organized by document type — in a persistent store such as Firestore. In subsequent document uploads, the system leverages past corrections to improve accuracy through several methods, including Few-Shot Prompting, where the backend retrieves corrected examples and includes them as context in the prompt sent to the Gemini LLM, allowing the model to learn from previous mistakes. This creates an adaptive system in which the “learning loop” ensures that human feedback directly improves future automated results, which are then reflected in the live metrics dashboard.
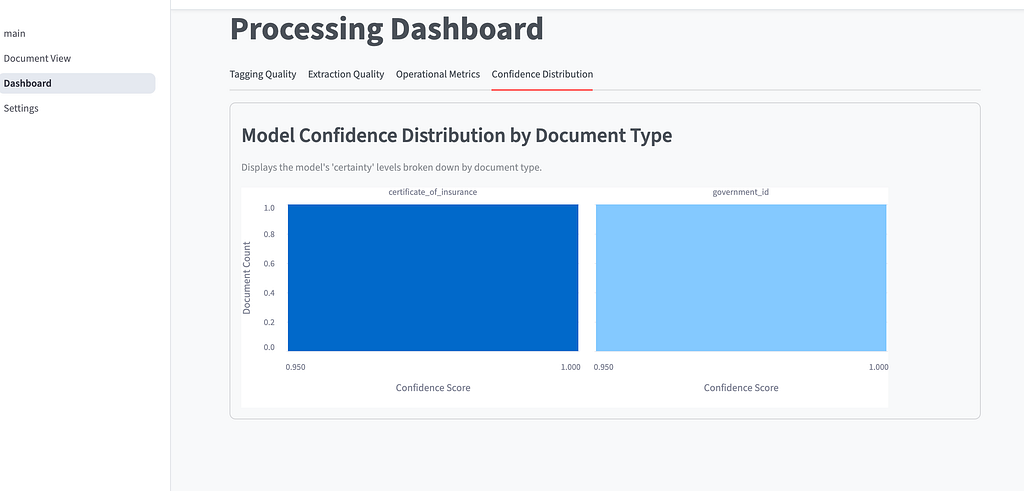
- Metrics Update: All results, including human corrections, are updated immediately on the metrics dashboard. This shows performance indicators like accuracy, latency, and human review rates.



From Smart MVP to Scalable System
By leveraging the efficiency of Gemini 3 Flash and a pragmatic architectural design, we rapidly built a functional, intelligent document processing MVP. This strategic approach — prioritizing speed and a tight feedback loop over premature scaling — delivered a system that successfully automates classification, integrates a critical human-in-the-loop workflow, and is already primed for its next stage of evolution.
Looking forward, the natural evolution for this system is to transition from a monolith to a distributed microservices architecture. This would involve decoupling services to enable independent deployment and scaling, and potentially replacing the single AI engine with specialized, self-hosted models — such as fine-tuned PaliGemma or DeepSeek-OCR — to maximize performance, control data sovereignty, and further reduce operational costs at scale.
As AI models become more capable and efficient, how quickly can we eliminate the last vestiges of manual data entry in our workflows?
Thank you for reaching the end of this article. Remember to visit our website, devhack.co, and leave your comments on what topics you want us to delve into. See you next time! Chao chao!
Visit my social networks:
- https://twitter.com/jggomezt
- https://www.linkedin.com/in/jggomezt/
- https://www.youtube.com/devhack
- https://devhack.co/
More Info
- https://ai.google.dev/gemini-api/docs/gemini-3
- https://load-document-processing-gzedfdcm3q-uc.a.run.app/
- https://github.com/jggomez/AI-loan-document-processing
Creating a document classifier and OCR: How to use Gemini 3 Flash to simplify the process was originally published in Google Cloud – Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source Credit: https://medium.com/google-cloud/creating-a-document-classifier-and-ocr-how-to-use-gemini-3-flash-to-simplify-the-process-98029bea684a?source=rss—-e52cf94d98af—4


 in Cisco Catalyst SD-WAN Manager")


