
Written by:
- Anushka Saxena, Software Engineer Apprentice @ Google (LinkedIn)
- Anubhav Dhawan, Software Engineer @ Google (LinkedIn)
Building multi-step AI agents is a significant milestone, but the path to a production-ready application requires a fundamental shift from informal “vibe checks” to rigorous, automated evaluation. In this post, we share our journey scaling the reliability of the Cymbal Air customer service assistant, an open-source demo designed to handle flight bookings and complex policy queries. By moving beyond manual spot-checks, we established a robust framework to evaluate how our agent reasons through complex, multi-step tasks.
To achieve this reliability, we transitioned our orchestration from LangChain to LangGraph, integrated with MCP Toolbox for unified database connectivity and the Vertex AI Gen AI Evaluation Service. This combination allows us to manage workflows as state machines and track the entire trajectory of an agent’s decision-making process, ensuring consistent and high-quality customer support.
The Architectural Shift
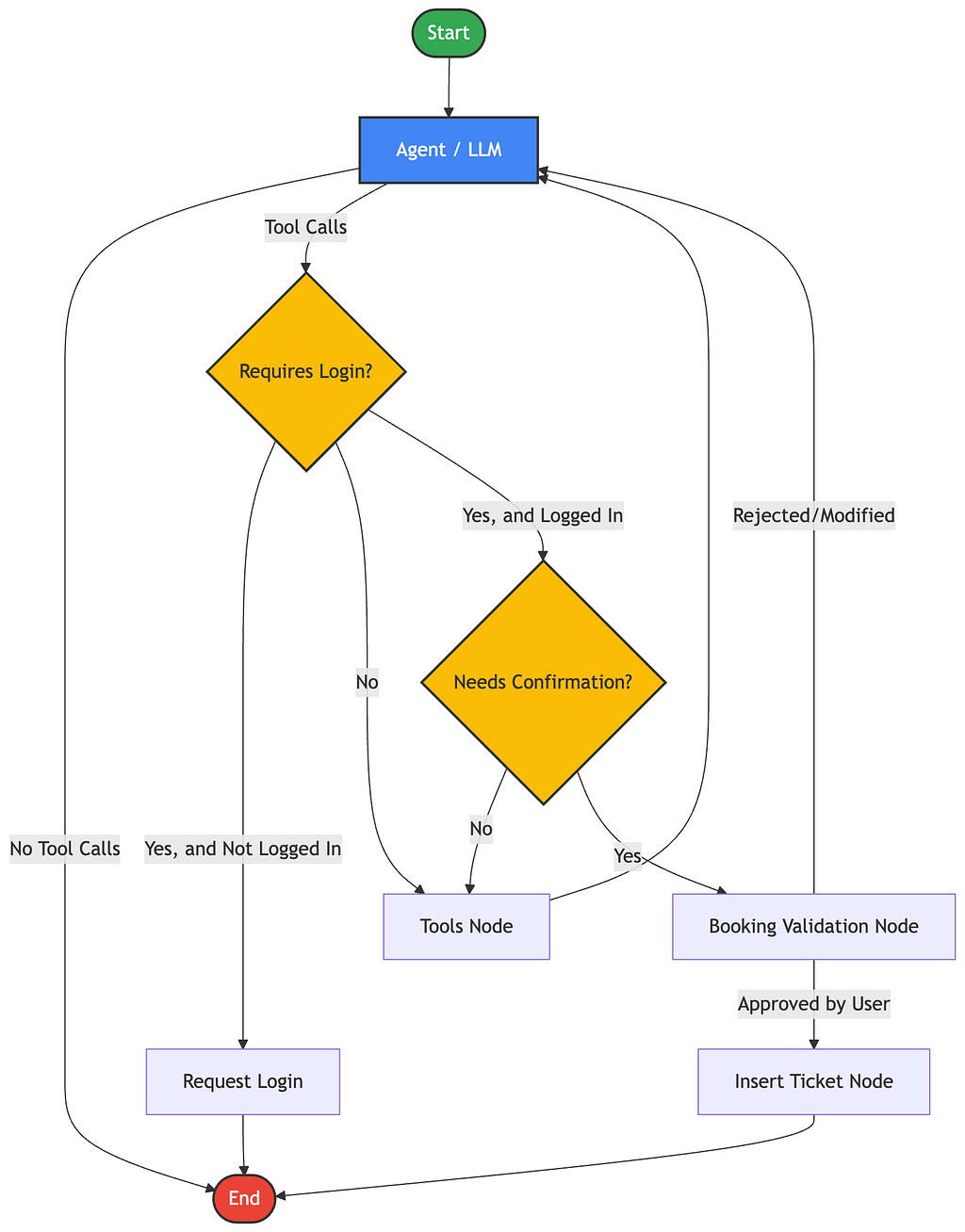
Our early iterations relied on traditional linear chains, which proved insufficient as Cymbal Air grew to handle conditional logic, loops, and human-in-the-loop confirmations. We needed a system that could manage persistent conversation state and cycles, leading us to migrate to LangGraph. By treating the agent’s logic as a state machine rather than a simple sequence, we gained the visibility and control necessary to bridge the gap between simple chat interactions and complex, multi-step tool orchestration.
Using LangGraph state management, we could persist and inspect intermediate execution state throughout the conversation, including:
- message history
- tool calls
- tool outputs
- and transitions between workflow nodes
This persistent workflow state became foundational for building more reliable evaluations, allowing us to inspect intermediate tool interactions rather than relying only on final responses.
Defining a comprehensive evaluation strategy
To move beyond “vibe checks,” we defined three specific pillars for our automated evals (the systematic process of testing AI performance):
- Response Quality: Evaluating whether the final response was helpful, accurate, and grounded in retrieved information.
- Tool Use: Verifying if the agent calls the right tools with the correct parameters.
- Tool Trajectory: Evaluating whether the predicted sequence of tool calls matches the expected execution flow for multi-step tasks. This became particularly important for workflows involving dependent tool calls, where a correct final response alone did not guarantee correct intermediate execution behavior.
Note: What is a Vibe Check? Informal, manual testing where a developer reads a few answers to see if they “feel” right. Automated evals replace vibe checks by testing hundreds of scenarios programmatically using predefined datasets (like eval_golden.py).
Outcomes from the new evaluation workflow
After migrating the evaluation pipeline to LangGraph and expanding evaluation coverage beyond final-response scoring, we were able to evaluate agent behavior at a much deeper level.
The updated workflow gave us:
- Better visibility into intermediate agent behavior
- More reliable evaluation of tool-augmented responses
- Improved validation of parameter extraction
- The ability to evaluate multi-step tool trajectories rather than only final outputs
In practice, this helped surface issues that were previously difficult to detect in the earlier evaluation setup, particularly around:
- Incorrect parameter extraction
- Invoking redundant tools
- Missing tool context during response evaluation
- Executing tool sequences in the wrong order in multi-tool workflows
Overall, the updated evaluation workflow became significantly more effective for debugging orchestration failures and validating multi-step execution behavior.
Lessons learned while improving evals
Handling “no tool required” cases
Generic queries like: “What is Cymbal Air?” correctly required no tool calls. Earlier evaluation flows treated empty trajectories as failures, which incorrectly penalized valid responses. Adding explicit handling for “no action required” cases improved retrieval evaluation reliability.
Detecting incomplete workflows
For the query: “Where can I get a snack near the gate for flight CY 352?”, the expected workflow required:
- Retrieving the flight gate
- Then searching nearby amenities
Trajectory evaluation revealed that the agent completed only the first step and skipped the amenities lookup entirely. This was a failure that response-only evaluation would have missed.
Identifying redundant tool calls
For the query: “What are some flights from SFO to Chicago tomorrow?”, the expected trajectory involved resolving the airport followed by a single flight search. The evaluation surfaced an unnecessary additional flight lookup, reducing trajectory precision despite partially correct retrieval behavior.
LangGraph provided the structured execution state needed to capture intermediate tool interactions, while the Vertex AI Gen AI Evaluation Service enabled us to systematically evaluate response quality, tool usage, and multi-step trajectories against expected workflows.
Get started
Ready to build and evaluate your own robust, stateful agents?
- Explore MCP Toolbox for Databases to build agent workflows with standardized and secure database tool integrations.
- Explore the full implementation and evaluation datasets in the Cymbal Air repo.
- Dive into the Vertex AI Gen AI Evaluation Service documentation.
- Master stateful multi-agent coordination with the LangGraph docs.
Beyond the Vibe Check: Scaling Cymbal Air Agent Reliability with LangGraph and Vertex AI Evals was originally published in Google Cloud – Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source Credit: https://medium.com/google-cloud/beyond-the-vibe-check-scaling-cymbal-air-agent-reliability-with-langgraph-and-vertex-ai-evals-42f6370303e5?source=rss—-e52cf94d98af—4





