
The horrors and safeguards of AI…Seeking guidance from Google Cloud.
I started to write with a specific destination in mind: Google Agentic Gateway. I wanted to dive straight into Google Cloud, architecture, and how to build secure gateways that police AI behavior.
But as a GDE and Splunk Certified Trainer, I soon realized the we need to understand first the dark web, the organized malicious actors, and the exact techniques they use to weaponize these new systems.
Here is the journey we are taking,:
- The Physics of the Threat: Why AI Agents and Machine Learning models are inherently dangerous vectors of attack.
- The Underground Market: How adversaries (who the hell are they?) buy, sell, and deploy AI-driven exploits.
- The Architecture of Defense: How Google Cloud integrates security at scale, and how we map this new telemetry into platforms like Splunk to detect autonomous threats before they break your infrastructure.
Why AI Agents are a Security Nightmare
If we care about security, we need to stop treating AI agents like genies in a bottle.
Traditional Machine Learning models are passive. They are static calculators. You feed an ML model a dataset, and it gives you a probability score — like predicting whether a financial transaction is fraudulent. The model itself cannot change its environment.
AI Agents are active, they use a Large Language Model as its brain, but it is connected to the real world through tools, APIs, databases, and operating system terminals.
This shifts the entire attack surface. Attackers no longer need to find a syntax error in your code to compromise a database. If they can manipulate the natural language prompt that guides the agent, they can simply ask the agent to delete the database for them. The agent becomes an insider threat, executing malicious intents with legitimate system permissions.
The Black Box: What is an ML Model?
Most IT professionals understand the high-level lifecycle of Machine Learning.
- You feed raw data into a training pipeline,
- the system extracts patterns,
- and it outputs a model that processes only numbers, and computes new data with complex math formulas.
It feels like a smart, dynamic program capable of analyzing the past and predicting future, present and past.
But what is a model when it is at rest, and why does its physical structure matter to a security engineer?
Physically, a machine learning model is just a serialized file. When a programmer finishes training a model in an environment like PyTorch or TensorFlow, they freeze the state of that model and save it to disk using standard file extensions like .pkl, .onnx, .pt, or .safetensors.
This file contains two core elements:
- the architectural metadata, which defines the structural rules of the system, similar to DB ones, (Data Types and Shapes and Topology, Constraints and Tokenizer Rules…)
- and the learned parameters, which are the mathematical weights and biases discovered during training.
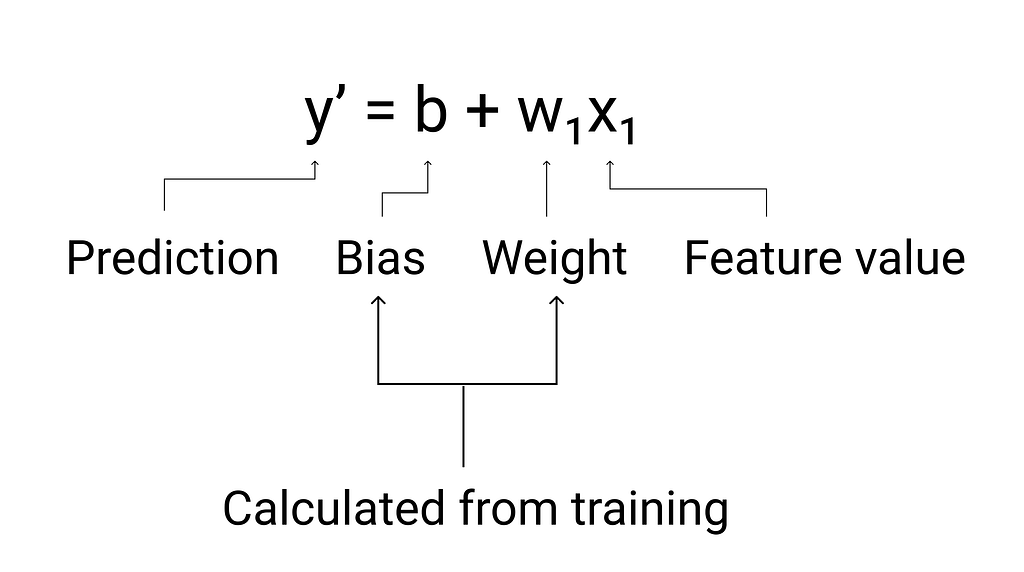
Mathematically, the model is a formula…you put the variables (x) and with weights and bias it will output the prediction (y).
But with Deep Learning and Gen AI this file represents a massive graph of BIG nested functions; it is a static structural network divided into input layers, hidden layers, and output layers. When data passes through the input layer, it undergoes millions of matrix multiplications across the hidden layers based on those saved weights, finally producing a statistical probability at the output layer.
From a security architecture standpoint, this internal design introduces vulnerabilities that traditional enterprise firewalls are completely blind to.
The physical files themselves can be active delivery mechanisms for malware. Legacy serialization formats like Python’s pickle (.pkl) do not just store numbers; they can serialize executable code. If a developer pulls a compromised .pkl file from a public repository and loads it into your environment, that file can execute arbitrary shell commands on the underlying cloud host during the deserialization process.
Example: a pickle file (.pkl) doesn’t just hold numbers; it also contains the instructions on how the computer should unpack those numbers.
An attacker can easily alter these unpacking instructions to include a malicious operating system command — like a script to steal cloud credentials or open a backdoor.
When an unsuspecting developer downloads this model from a public repository and tries to use it, the file forces the underlying server to execute the hidden command immediately, before any AI logic even begins. If this server runs inside your cloud environment, the hacker instantly inherits the exact network access and privileges of that system and can do what they want.
No worries, now we are moving toward safer, data-only formats like .safetensors.
You cannot patch a security flaw with a standard software update.
..because the model is a mathematical graph rather than deterministic code.
If an attacker maps the hidden layers and finds a specific mathematical input vector that confuses the calculation, they can force the model to misclassify data or leak information.
Opacity and Complexity: Because deep learning models contain millions to billions of parameters, they are “black boxes” that are incredibly difficult for security teams to interpret, formally verify, or audit for hidden backdoors
Attackers can Reverse Engineering the Model: Data Reconstruction
An attacker can reverse-engineer a machine learning model to recreate private data, like a user’s face or financial record. They start by feeding completely random noise into the target model. By looking at the model’s output probabilities, they use the mathematical slope of the model’s own function to walk backward.
Example: Imagine a research hospital trains a machine learning model to diagnose a rare, highly stigmatized medical condition. They use a private dataset of 1,000 specific patients.
An attacker wants to find out if a high-profile individual, Bob, was part of that clinical trial — a fact that would instantly leak his private medical diagnosis. The attacker doesn’t have access to the hospital’s database, but they do have access to the model’s public API endpoint.
The attacker queries the API using Bob’s specific medical metrics — his exact blood markers, age, genomic data, and history.
Because the model was trained on Bob’s actual data, it recognizes his exact profile perfectly. The API response spikes, returning its diagnosis with an extreme, near-perfect 99.9% confidence score.
To verify the leak, the attacker queries the API again with an almost identical medical record of a person who was not in the training pool. The model still accurately diagnoses the condition, but because it hasn’t seen this specific combination of variables before, it outputs a standard, generic 75% confidence score.
Embedding: the last layer
What is an Embedding?
An embedding as a precise list of numbers that describes an object or a concept. Each number in that list quantifies a specific characteristic.
For example, if we want to describe a Lion, the model generates a list of numbers. One number represents its “feline status,” another measures its “physical size,” and a third quantifies its “ferocity.”
Because these embeddings are just lists of numbers, computers can perform standard math on them. If you subtract one list from another, the resulting mathematical distance tells you exactly how similar or different the two concepts are.

Using this basic subtraction, the model discovers that a Lion is almost identical to a Lioness because their numbers match closely across the board. It will also find that a Lion is reasonably close to a King because they share abstract characteristics of majesty and power in the text the model was trained on. However, the list of numbers for a Lion will be mathematically lightyears away from the list describing an Oak Tree.
This is how an AI maps human language (english, french, chinese) into a spatial geography it can calculate.
Why a deep learning model produces embeddings at the end?
Lets talk about LLMs, so smart chats.
When you send a prompt into a Large Language Model or an agent, the network passes your text through dozens of internal, deep transformer layers. Each layer calculates relationships between the words to understand the underlying context.
At the very last hidden layer, the model finishes its calculation and outputs a single, high-dimensional vector. This is the embedding.
This embedding represents the cumulative meaning of the entire conversation up to that exact millisecond. It is a dense string of numbers that holds the concept of what was said. But you cannot read this string of numbers, and neither can a standard command line.
To turn that raw mathematical thought into a human response, the model passes that final embedding vector into its ultimate layer, often called the Language Model Head, that converts the raw numerical weights into a clean list of percentages that all add up to 100%.
If the internal embedding represents the concept of a terminal operation, a final function (activation..Softmax by the way) calculates a 92% probability that the next word should be sudo, a 7% probability for run, and a 0.001% probability for banana.
The system then picks the most likely word (or samples from the top choices) and outputs it to the screen. It repeats this entire two-step cycle for every single token it generates.
This is what happens with LLMs. Instead, an Agent takes that raw internal embedding vector and feeds it directly into a (Vector) Database or an API router. The system decides which database row to access or which API to trigger based on how close those numbers are to each other in mathematical space.
This creates a potential big problem. If an attacker manipulates a prompt, they can subtly shift the values inside that hidden embedding vector. To a human security analyst reading the text log, the phrase might look completely benign. But at the machine level, the numbers in the embedding have shifted just enough to map directly onto a highly restricted database query.
Gaining Access: How Attackers Steal the Model
Unsecured Cloud Storage Buckets During development, data scientists often save serialized model files (.pkl or .safetensors) into cloud storage infrastructure like Google Cloud Storage or AWS S3. If the Identity and Access Management (IAM) policies are configured too loosely, or if an automated script temporarily sets the bucket to public, attackers use automated internet scanners to find and download the entire model file directly to their local machines. Once they have the file, they have the entire mathematical graph.
Supply Chain and Registry Leaks Modern development rely heavily on public repositories and model hubs like Hugging Face or GitHub. Attackers regularly compromise developer accounts, exploit vulnerabilities in automated CI/CD deployment pipelines, or scan for accidentally committed API keys and access tokens. If a developer unintentionally leaves corporate model assets in a public-facing repository, the attacker can clone the entire architecture instantly.
Public API Over-Exposure An attacker does not always need the physical file to compromise a system. If your application exposes the model via a public API endpoint to serve users, it is vulnerable. By flooding the endpoint with thousands of rapid, automated queries, the attacker can use the shifting confidence scores in the API’s text or numerical output to map out the model’s behavior from the outside, achieving the exact same mathematical exploitation without ever touching your internal servers.
A Practical Threat-to-Defense
Worried? Let’s have some relief and look at the big picture and the main methods for securing AI. By the way I am speaking about Google Cloud but there are other solution in the market and inside other Platform.
Model Exfiltration and Data Reconstruction
An attacker compromises loosely secured infrastructure, downloads a serialized model, and walks backward through the math functions to recreate private data like user images or sensitive credentials.
The Google Cloud Defense: Secure Storage and Attestation
To stop attackers from ever downloading the model, Google Cloud uses Vertex AI registries combined with strict Identity and Access Management (IAM) policies. For high-security environments, you can run training and inference workloads inside Google Cloud Confidential Computing. This encrypts data and model weights directly inside the CPU memory during execution, ensuring that even if an attacker gets root access to the host machine, they cannot read the underlying mathematical graph.
Membership Inference
Adversaries use public-facing APIs to flood your model with high-speed queries. By analyzing the tiny variations in how confidently the model responds, they reverse-engineer whether a specific individual’s private data was used to train the system. Look at the hospital example.
The Google Cloud Defense: Rate Limiting and Privacy Filters
Google Cloud Armor (but also a simple API gateway) acts as the first line of defense, using advanced rate-limiting and machine learning-driven web application firewalling to block automated API scraping. Deeper in the pipeline, Vertex AI implements Differential Privacy frameworks during training. This injects controlled mathematical noise into the model’s learning process, erasing the signature “confidence patterns” and preventing attackers from deducing the training contents. So, it will not expose the exact confidence score to the client.
Supply Chain File Poisoning
An engineer unknowingly pulls a model package from a public repo containing hidden malicious code inside a legacy serialization format like .pkl. The moment the file is loaded into your server memory, it executes shell commands and compromises the host.
The Google Cloud Defense: Secure Artifact Registries and Formatting
Google Cloud Artifact Registry continuously scans containers and software packages for known structural vulnerabilities. To mitigate this threat entirely, the platform enforces the use of modern data-only serialization formats like .safetensors. This format completely strips out the capability to store or execute code, rendering deserialization attacks physically impossible.
Data Poisoning and Label Flipping
Attackers inject malicious samples or intentionally misidentify labels during the data collection phase to corrupt the model’s logic. For example, they might flood a dataset with fake bank emails to train a spam filter to ignore actual phishing attempts, or deliberately mark a virus file as “safe” so the finished security AI skips it during a scan.
The Defense: Teams often mistakenly prioritize expensive front-door data filtering to block “unsafe” inputs.
This strategy fails at enterprise scale; achieving 100% pure ingestion across terabytes of cloud telemetry is an expensive illusion.
The Google Cloud Defense: Lineage and Statistical Resilience
Resilient architectures assume raw data is always compromised, focusing on transparency over perfect filtering.
Google Cloud utilizes Dataplex Knowledge Catalog to map Data Lineage across BigQuery, Dataflow, and Cloud Storage. This allows teams to trace erratic model behavior back to the exact origin and timing of poisoned files.
To automate detection, BigQuery ML identifies anomalies by evaluating the statistical distribution of the entire dataset. This flags mathematical shifts caused by Clean-Label or Feature Collision attacks designed to warp model embeddings.
Clean-Label and Feature Collision Attacks
Adversaries alter training data with invisible digital noise while keeping the text or image labels completely correct. This math trick forces the model to misinterpret broader logic — like subtly tweaking images of cats so the model eventually learns to misidentify all dogs as cats. Similarly, they can engineer a malicious file to collide with the exact internal embedding coordinates of a “safe” object, making a cyber threat look like a trusted Windows update in the model’s internal map.
Defenses
Training Dynamics and Loss Tracing
During the early stages of training, a model learns broad, clean patterns first. If an attacker flipped the label on 1% of those samples to say “Safe,” the model will struggle heavily with those specific files during the first few training cycles. The mathematical error — known as the loss value — for those poisoned samples will spike dramatically. The model is essentially screaming that the label contradicts the rest of reality.
Spatial neighborhood analysis detects label flips by identifying data points with labels that oppose the majority of their geometric neighbors, stopping corruption before it occurs.
Confident Learning Frameworks
There are programmatic validation frameworks inside modern data pipelines. These algorithms calculate a “confident joint distribution” between the raw features of the data and its assigned labels. It mathematically estimates the probability of label errors across the entire dataset, automatically clean-cutting the intentionally flipped labels from the legitimate data.
Statistical Anomaly Detection So, defenses must audit the data mathematically. Google Cloud handles this by utilizing BigQuery ML anomaly detection combined with Dataplex data profiling. By automatically evaluating statistical distributions and mapping embedding spaces across massive datasets, the infrastructure flags unnatural coordinate overlaps and suspicious data distributions before they reach the model engine.
Backdoors and Poisoned Augmentation
An attacker compromises the data-loading code — such as modifying an image-rotation script to secretly plant a single malicious pixel onto every processed photo. This plants a hidden Trojan trigger in the model. In production, the system works flawlessly until it encounters that specific trigger, forcing an intentional failure, like a security camera system that instantly unlocks for anyone wearing a specific red tie.
The Google Cloud Defense: Immutable Pipelines and Batch Auditing To safeguard the data-processing workflow, Vertex AI Pipelines can use container images verified by Artifact Registry. To hunt down backdoors already hiding inside trained models, security teams implement Batch Aggregation Auditing. Instead of evaluating data samples one by one, this technique asynchronously inspects massive groups of data together, discovering hidden, artificial trigger clusters that easily disguise themselves when viewed individually.
Agent Manipulation and Privilege Creep
An attacker uses conversational language to bypass an LLM’s guardrails, manipulating the underlying agent into running unauthorized API commands or accessing databases it shouldn’t touch.
The Google Cloud Defense: Model Armor and Agent Gateway
This is the core of our upcoming chapters. Google Cloud handles this through a zero-trust network component called Agent Gateway. The gateway acts as a secure, programmable data plane that works as a guardian and intercepts every agent-to-tool and user-to-agent connection. It automatically enforces Agent Identity — giving each autonomous agent its own distinct, cryptographically attested identity based on the SPIFFE standard.
By running Model Armor directly inside this gateway, Google Cloud inspects prompts and responses in real-time, stripping out prompt injections and blocking unauthorized database tools before the agent can even execute the math.
Conclusion: let’s Meet the Enemy.
We have officially demystified the black box. We stripped away the AI marketing hype and broke down exactly what a model looks like at rest, how embeddings translate human concepts into numerical maps, and how data pipelines can be compromised through mathematical manipulation.
Now let’s understand the active psychology and mechanics of the people trying to destroy it.
In our next article, we will unmask the organized cyber syndicates, the nation-state threat actors, and the script kiddies who are actively buying, selling, and weaponizing these exact AI exploits against enterprise cloud networks.
Breaking and Securing AI: an introduction was originally published in Google Cloud – Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source Credit: https://medium.com/google-cloud/breaking-and-securing-ai-an-introduction-4798dbf71672?source=rss—-e52cf94d98af—4




