
Authored by: Dwij Sheth & Vinay Damle
The cloud is built on the promise of elasticity, but certain workloads demand dedicated hardware for strict compliance, licensing restrictions, or absolute performance isolation. In Google Cloud Platform (GCP), this is achieved using Sole-Tenant Nodes.
However, moving to dedicated hardware brings back a physical constraint: you pay for the entire server node you provision, regardless of whether you are utilizing 1% or 100% of its capacity.
Imagine you operate a massive fleet of cargo ships (Sole-Tenant Nodes) carrying shipping containers (Virtual Machines). Managing this fleet effectively means playing a high-stakes game of Tetris on the open ocean:
- You pay the fuel and crew costs for a ship whether it is fully loaded or carrying just two containers.
- As workloads are spun up and destroyed over time, your cargo capacity becomes highly fragmented with scattered gaps.
- To drastically reduce costs, you must perfectly pack the remaining cargo so you can send empty ships back to port.
Google Cloud provides powerful primitives like Sole-Tenant Nodes and seamless Live Migration that empower teams to build highly customized orchestrators. Here is a technical deep-dive into how we built an automated Sole Tenancy Node Optimizer, creating a digital “harbor master” to play and win this game of Cloud Tetris.
Orchestrating Live Migrations: Transferring Cargo at Sea
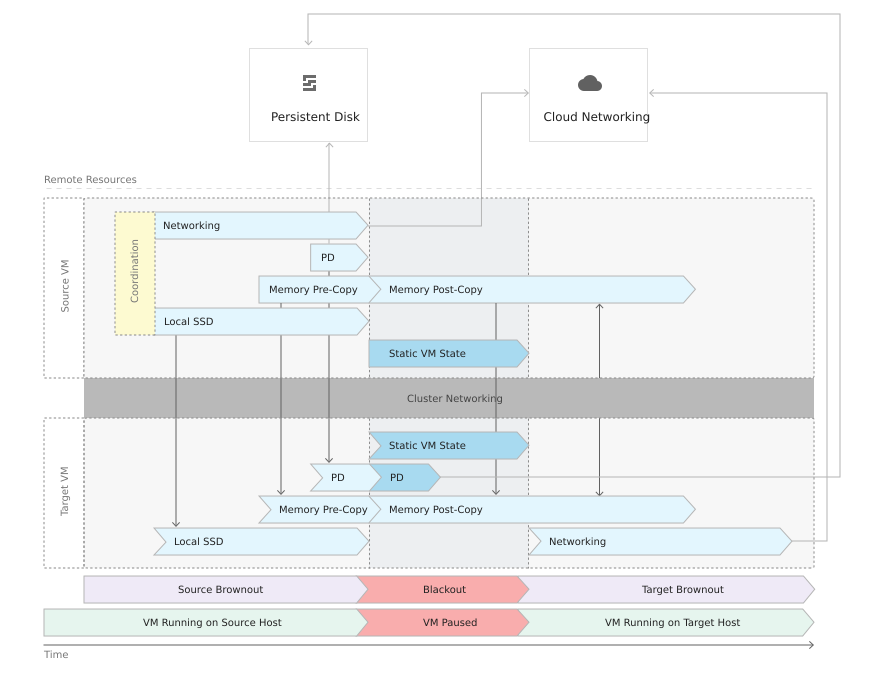
In traditional logistics, transferring heavy containers between ships requires halting operations and docking at a port. In the cloud, halting an enterprise system is simply not an option; applications must remain completely online.
Google Cloud’s Live Migration feature acts as our mid-ocean transfer mechanism, allowing us to move workloads without disrupting the fleet:
- Pre-Copy Phase: The hypervisor iteratively copies the VM’s active memory pages from the source ship (node) to the destination ship, meticulously tracking any memory changed during the transfer.
- Blackout Phase: Once the memory states are nearly synchronized, the VM is paused for just milliseconds to transfer the final state and device registers.
- Resumption: The VM resumes execution on the new hardware seamlessly, completely unaware it has been moved.
While this process is incredibly robust, it carries a time cost. A single Live Migration typically takes minutes to complete from start to finish. Because moving a single container takes minutes, sequential moves across a massive fleet would take days. To rapidly consolidate the fleet, our harbor master needed a highly efficient, automated strategy to move dozens of containers simultaneously.
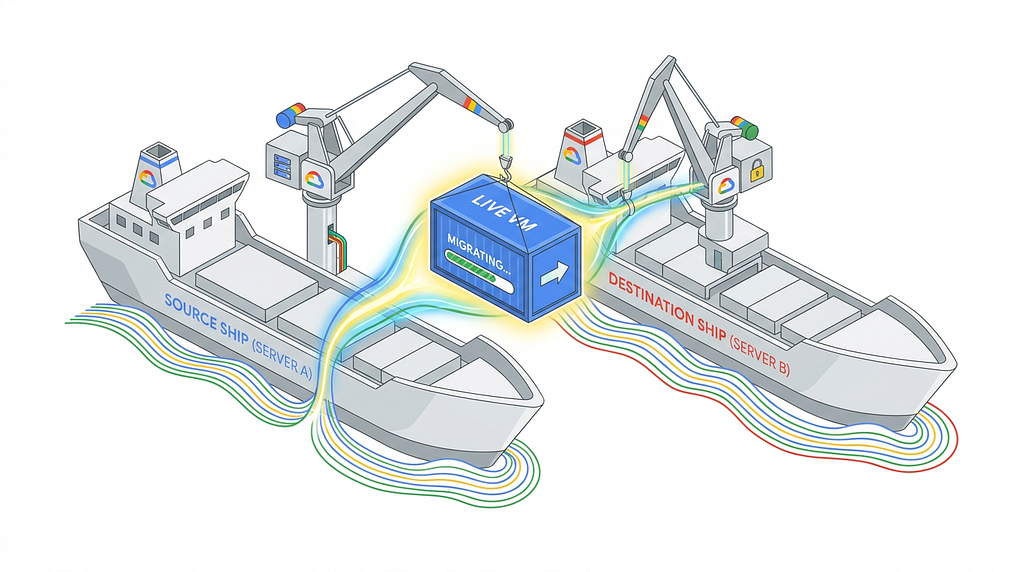
The Algorithm: Greedy Drain and Best-Fit Packing
We structured the orchestration engine around a four-step continuous loop: Discover State, Analyze & Plan, Live Migrate, and Refine. But the core intelligence lies in the planning phase, where the harbor master executes a Greedy Drain algorithm.
To maximize the number of empty ships we can decommission, the engine follows two strict rules:
- Candidate Selection (The Greedy Drain): The engine actively searches for the “emptiest ships” first sorting source nodes by minimum instance count and minimum utilization. These are the easiest to completely clear out.
- Destination Selection (Best-Fit): Instead of spreading containers evenly, the engine force-packs cargo into the destination ships that are already the fullest (sorting by maximum utilization).
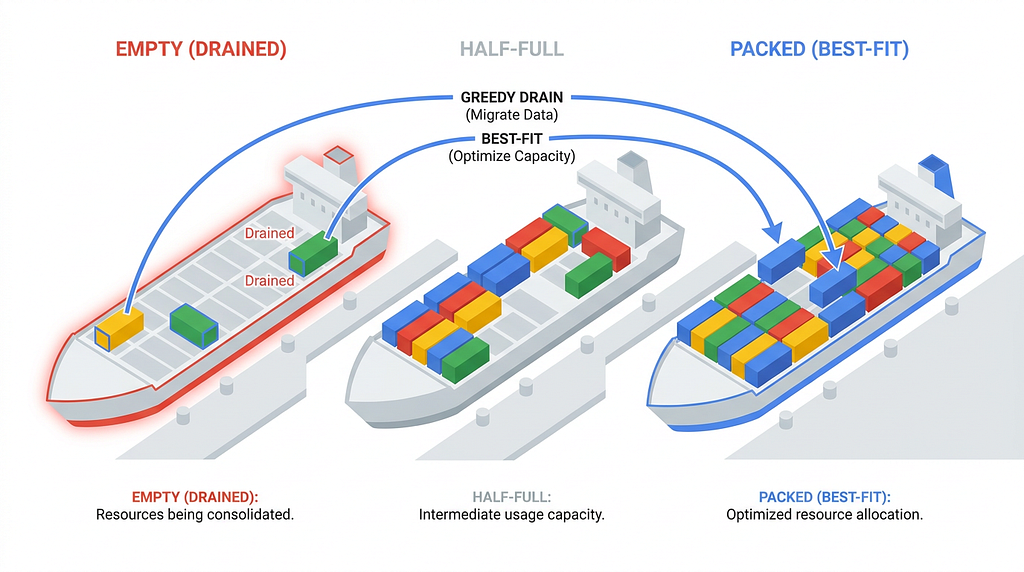
This logic quickly maximizes ships sitting at 100% capacity. But as any Tetris player knows, if you drop the wrong pieces early on, you create unfillable gaps later.
Preventing Physical Fragmentation: Large-VM Prioritization
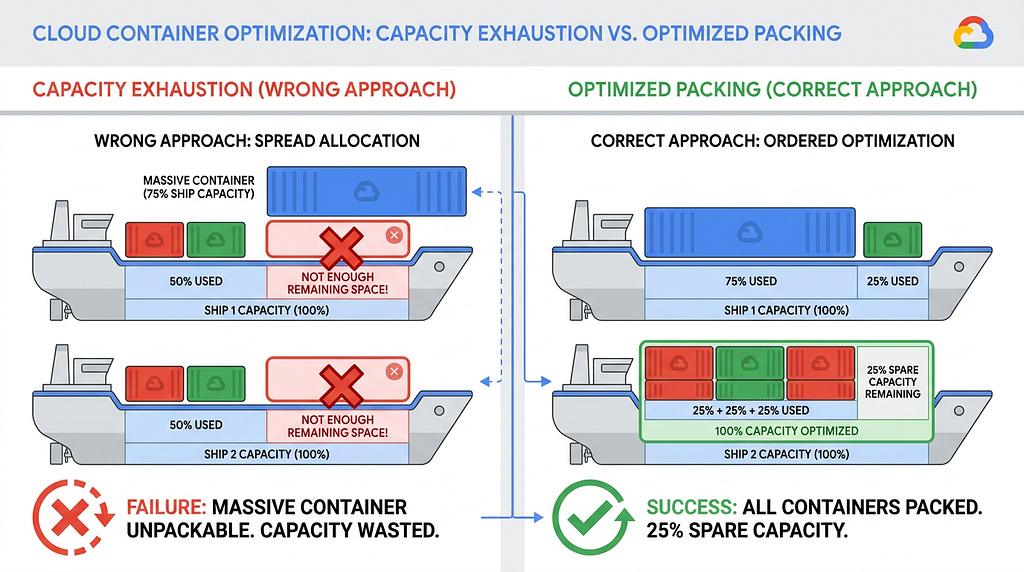
Even with the Greedy Drain strategy, a new physical constraint emerged. If our automated cranes grabbed the smallest containers (e.g., 2-vCPU VMs) first, they would scatter them across the destination ships, filling up random deck slots.
Later, when the crane attempts to load a massive 32-vCPU database VM, no single ship has enough total capacity left to hold it even if the combined free capacity across the entire fleet added up to hundreds of vCPUs. To prevent this, we implemented strict Large-VM Prioritization:
- Before execution, the entire migration plan is sorted by VM size (vcpu and memory_mb) in descending order.
- The massive, oversized containers are assigned to destination ships first, ensuring the bulk capacity is reserved for them.
- Only then are the smaller crates loaded, which safely consume whatever fractional capacity is left over on the ships.
With the sorting logic perfected to avoid fragmentation, we fired up the automated cranes. However, running this at scale introduced a dangerous race condition on the docks.
The Dynamic Port: Managing Capacity Collisions
While our automated cranes are busy moving containers, the port remains open for normal business. The cloud is a dynamic environment, which introduces a new problem: unexpected double-booking.
- Our optimizer discovers 16 vCPUs of available space on “Ship A” and schedules a crane to move a container there.
- Before the crane can finish the move, a new container (an external workload from an autoscaler or developer) arrives at the port. The main GCP office immediately books it into that exact space on Ship A.
- When our crane finally attempts to drop its load, the GCP API rejects the move with a 412 PRECONDITION FAILED (Insufficient Capacity) error.
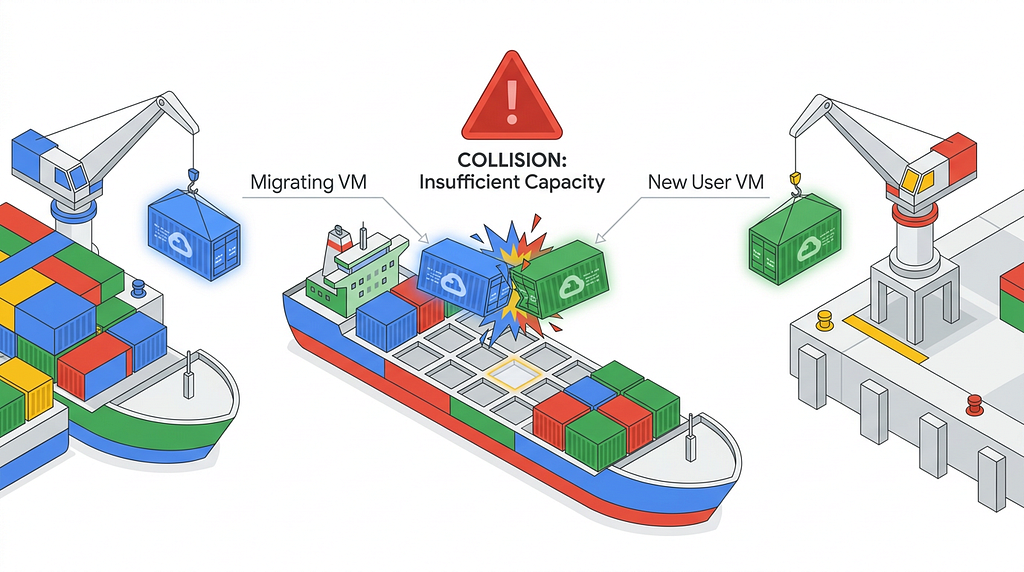
Additionally, our own parallel cranes might try to claim the same space simultaneously. To prevent our own system from causing these collisions, we introduced an in-memory Resource Reservation System. When a thread plans a migration, it instantly deducts the reserved_vcpu from the destination node's simulated free pool so other threads don't double-book it.
However, we still needed a robust way to handle collisions caused by those unpredictable, external workloads.
Self-Healing State: The Multi-Pass Architecture
When a capacity collision occurs, the crane simply drops the container back onto the source ship. Rather than building a brittle, globally locked harbor schedule to prevent every possible external conflict, we designed the engine to embrace the dynamic nature of the cloud using a resilient Multi-Pass Architecture:
- Execute the Pass: The engine lets the entire first optimization pass execute completely. The vast majority of parallel migrations succeed, but unpredictable external workloads might cause a few collisions.
- The Refine Loop: Rather than halting the port or throwing a fatal error, the engine finishes its first pass and then automatically begins a fresh “Refine Loop.”
- Re-Evaluate and Retry: It fetches the newly updated, post-collision state of the entire fleet, discovers which destination ships actually have real capacity remaining, and launches a second sweeping pass to route any stranded cargo to new open slots.
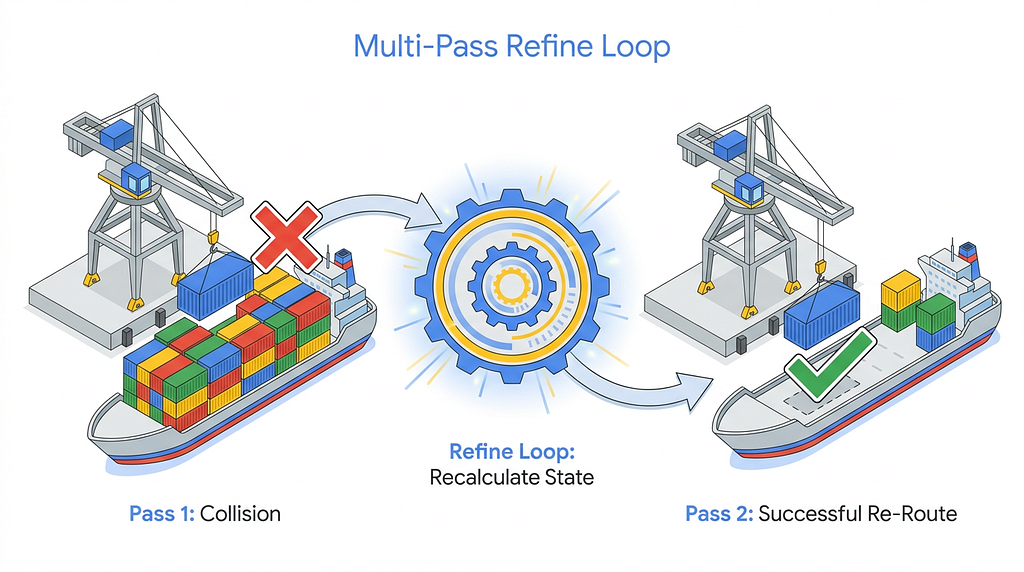
This self-healing loop elegantly resolves capacity conflicts on the fly, ensuring that the fleet is fully optimized without needing to pause external cloud traffic. However, while the destination ships were now protected and resilient, the sheer volume of concurrent moves accidentally threatened to capsize the source ships.
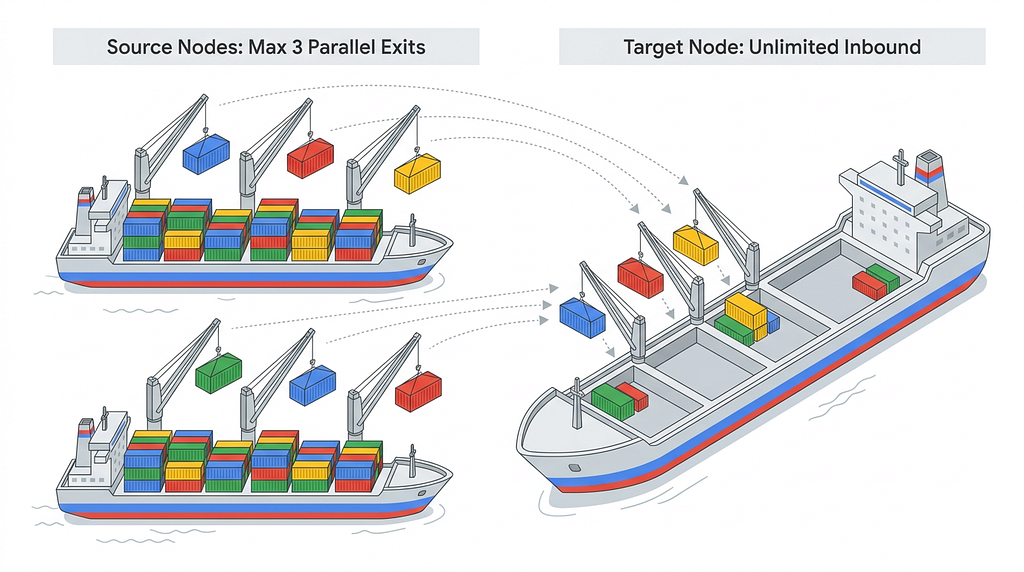
Hardware Strain: Enforcing Source-Node Parallelism
While optimizing the destination, we inadvertently created a massive bottleneck on the source ships.
If the engine identified a source ship with 50 small containers and commanded 50 cranes to unload it simultaneously, the physical hardware strained under the load. Overwhelming the underlying hypervisor’s management plane and I/O during Live Migration risks host stability. You simply cannot attach fifty cranes to a single small vessel without capsizing it.
To mitigate this, we throttled the system using Source-Node Parallelism Limits:
- Instead of using a global free-for-all thread pool, the engine assigns dedicated ThreadPoolExecutors per physical source node.
- We enforce a strict concurrency cap, allowing a maximum of 3 active Live Migrations originating from a single source host at any given time.
The throttles kept the physical hardware perfectly stable, but the open sea remains unpredictable. We still needed a way to handle sudden manifest changes mid-flight.
Conclusion: Winning the Cloud Tetris Game
Automating cloud efficiency requires treating infrastructure as a dynamic logistics puzzle that must account for mathematical bin-packing, concurrency safety, and the absolute physical limits of the underlying hardware.
By combining the power of GCP Live Migration with a Greedy Drain algorithm, strict resource locking, and source-node parallelism constraints, we transformed a fragmented fleet of servers into a highly dense compute environment:
- CPU and RAM packing efficiencies climbed dramatically across our active nodes.
- Dozens of emptied ships were successfully returned to port.
- By eliminating wasted capacity, our overall dedicated compute costs plummeted.
With Google Cloud’s powerful architectural primitives like Live Migration, even the strictest dedicated hardware environments can achieve true cloud elasticity ensuring our enterprise customers always operate at peak performance and minimal cost.
The puzzle never really ends.
While our greedy-drain algorithm solved our immediate density challenges, the cloud is always evolving. How is your engineering team handling the physical constraints of dedicated compute? Have you built your own custom orchestrators, or do you rely entirely on out-of-the-box scheduling policies?
We’d love to hear your approach to solving these hardware puzzles at scale. Drop a comment below or connect with us on LinkedIn: Dwij Sheth, Vinay Damle to keep the conversation going!
The Cloud Tetris: A Technical Deep Dive into GCP Sole-Tenant Node Usage Optimization was originally published in Google Cloud – Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source Credit: https://medium.com/google-cloud/the-cloud-tetris-a-technical-deep-dive-into-gcp-sole-tenant-node-usage-optimization-4572d3802dea?source=rss—-e52cf94d98af—4



