
Most AI coding agents work somewhere you don’t actually live: a chat window, a terminal, a console. LinearAgent puts one inside your issue tracker instead. Delegate an issue in Linear and a Gemini-powered Antigravity agent picks it up, fixes the code, and opens a pull request, thinking out loud in the issue the whole time. The hard part is the pause: letting a long-running agent wait for human approval without holding a server open for the full delay. My answer is a non-blocking task queue, where the worker exits at the gate, Cloud Run scales to zero, and a fresh job resumes after the reply.
What to Read the Code?
The full source is open on GitHub: thomas-chong/linearagent.
How do the Antigravity SDK and Linear’s Agent API fit together?
LinearAgent installs as a Linear Actor App and resolves delegated issues with a Gemini-backed Antigravity agent. The design goal is to keep the agent where developers already work, inside the issue tracker, rather than in a separate console that nobody keeps open.
There are exactly two integration seams, and naming them clearly is half the design. The first seam is the Antigravity SDK (import google.antigravity), the agent brain that reads an issue, edits a repo, and opens a pull request. The second seam is Linear's Agent Interaction API, which delivers @mentioned or delegated issues as AgentSessionEvent webhooks and accepts streamed Agent Activities back. Between those two seams sits the part this Sprint is about: a non-blocking asynchronous task queue.
Most “AI in your tracker” integrations couple the model loop directly to the webhook handler. That works until the model loop runs for an hour. By splitting the two seams with a queue, I get to treat the Antigravity run as a genuinely long-running operation, free to pause, exit, and resume, without ever breaking Linear’s expectation of a fast webhook ack.
The Antigravity side of that boundary is small and canonical. The SDK hands me an async Agent context manager. I build a config, open the agent, send the issue as a prompt, and stream the result. Here is the core of AntigravityRunner.run from src/linearagent/agent/runner.py:
# src/linearagent/agent/runner.py
from google.antigravity import Agent
config = build_config(workspace, ask_user_handler=ask_user_handler, repo=repo)
async with Agent(config=config) as agent:
# chat() returns a LAZY async stream: the agent's tool calls and file
# edits only execute as the stream is consumed. Drain it fully here,
# inside the context manager - otherwise __aexit__ cancels the in-flight
# run and the agent makes zero changes.
response = await agent.chat(prompt)
response_text = await _stream_response(response, on_event)
That is the whole SDK surface this build leans on: Agent(config=…), chat(prompt), and a stream I consume myself. Everything else, the queue, the checkpoints, the idempotency, is wiring I wrapped around those three calls. The interesting parts live in the two helpers. build_config is where the agent's safety posture is declared, and _stream_response is where its reasoning turns into a Linear timeline. The next two sections open each of those up.
What does the end-to-end architecture look like?
Google’s recommended pattern for mission-critical webhooks is async and event-driven: an ingestion service validates and acks HTTP 200 immediately, then hands off to Cloud Tasks (Google Cloud, 2025). LinearAgent follows that pattern exactly. Cloud Run allows request timeouts up to 60 minutes, but the ingest path aims to ack within five seconds.
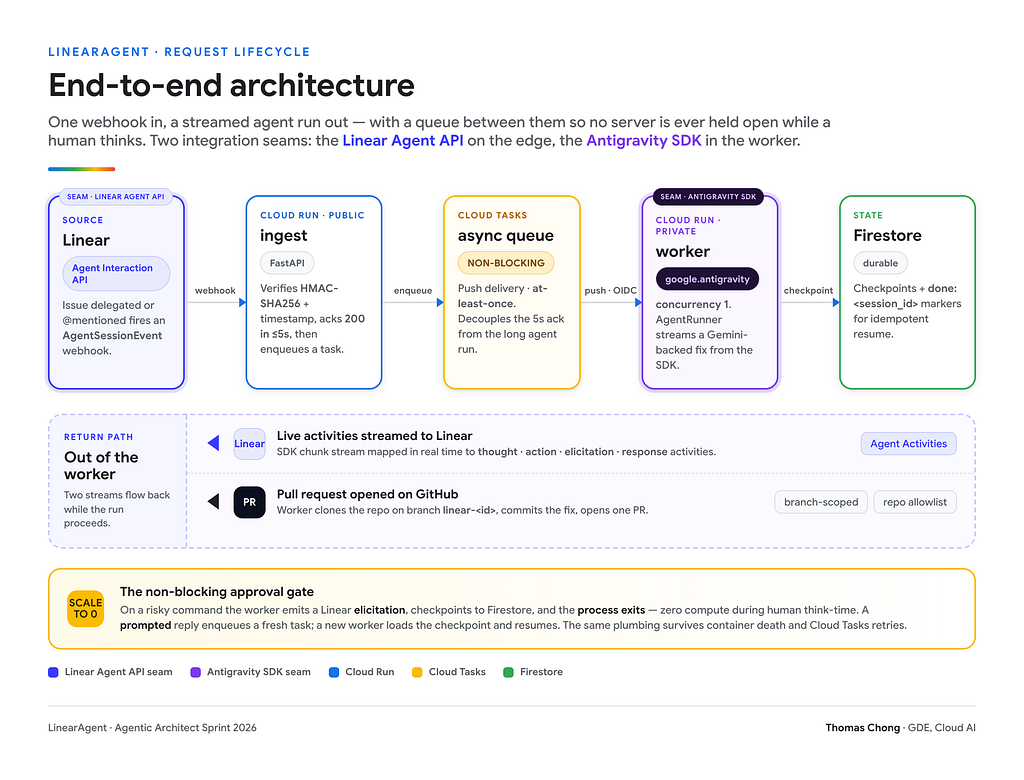
The flow is a forward chain with a return path. Linear fires an AgentSessionEvent webhook into a public Cloud Run "ingest" service built on FastAPI. Ingest verifies an HMAC-SHA256 signature, checks a timestamp window, acks 200, then enqueues a Cloud Tasks job. Cloud Tasks pushes that job to a private Cloud Run "worker" running at concurrency = 1. The worker clones the target repo onto a branch named linear-<id>, runs AgentRunner over google.antigravity, checkpoints to Firestore, and opens a GitHub PR.
The split is deliberate, and the ingest code makes the boundary literal. Ingest verifies an HMAC-SHA256 signature with a constant-time compare, rejects anything outside a replay window, enqueues, and returns. It never imports the agent, never clones a repo, never touches the SDK. That is what lets it ack in milliseconds and keeps the public surface small enough to reason about:
# src/linearagent/webhook/app.py - ingest verifies, then enqueues. It never runs the agent.
def _verify_signature(payload_bytes: bytes, signature: str, secret: str) -> bool:
expected = hmac.new(secret.encode(), payload_bytes, hashlib.sha256).hexdigest()
return hmac.compare_digest(expected, signature) # constant-time compare
def _verify_timestamp(ts, *, window=REPLAY_WINDOW_SECONDS) -> bool:
t = float(ts)
if t > 1e11: # Linear sends ms; normalise to seconds
t /= 1000.0
return abs(time.time() - t) <= window # reject anything outside +/-60s
@app.post("/webhooks/linear")
async def linear_webhook(request, linear_signature=Header(None, alias="Linear-Signature")):
body = await request.body()
if not _verify_signature(body, linear_signature or "", _webhook_secret):
raise HTTPException(401, "Invalid signature")
payload = json.loads(body)
if not _verify_timestamp(payload.get("webhookTimestamp")):
raise HTTPException(401, "Timestamp out of replay window")
if action == "created":
await _queue.enqueue("run", {...}, dedup_key=f"run-{session_id}")
return {"status": "queued"} # acked in milliseconds; zero agent work here
Two details earn their keep. The timestamp normalisation handles Linear sending milliseconds where the comparison wants seconds, so a real webhook is not rejected as a stale one. The dedup_key is the first of three idempotency layers, covered later. Cloud Tasks then gives durable, at-least-once delivery and decoupling: if a worker dies mid-run, the task is redelivered. One honest caveat I'll state plainly. In my build the worker runs at concurrency = 1 and a single max instance, so the queue serializes issues rather than running them in parallel. The queue's value here is durability and the non-blocking gate, not horizontal throughput.
Why is the non-blocking approval gate the centerpiece?
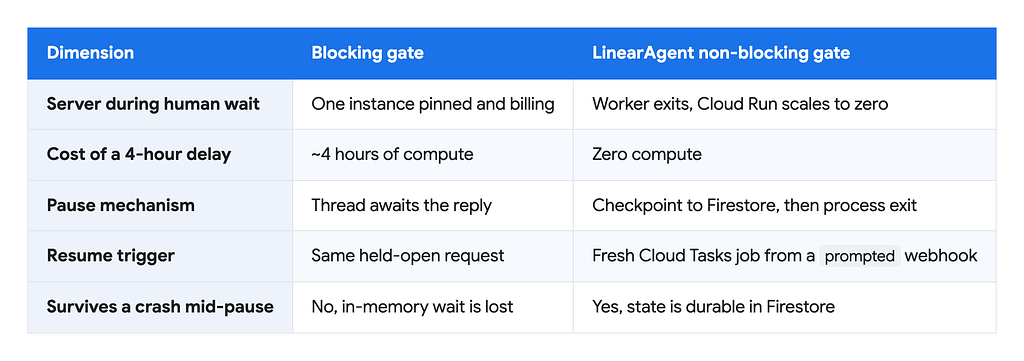
The gate is the whole point of the Sprint topic. Most published human-in-the-loop patterns treat approval as a synchronous pause: the request thread waits while a person decides. That ties up a server for the full human latency. Picture the worst case. An agent wants to run a destructive shell command, and a reviewer takes four hours to respond. A blocking agent holds a server for four hours doing nothing.

The contrast between the two gate styles is stark once you put them side by side:
LinearAgent does the opposite of blocking: it exits. But before the exit, there is a more interesting design choice, and it sits right on a Sprint topic. The gate starts life as a declarative safety policy, not as bespoke plumbing inside the run loop. In build_config I attach a one-line policy.ask_user to the run_command tool, scoped by a when predicate so it fires only on genuinely risky commands. Here is the policy from src/linearagent/agent/config.py:
# src/linearagent/agent/config.py
from google.antigravity import LocalAgentConfig
from google.antigravity.hooks import policy
def build_config(workspace, *, ask_user_handler=None, repo=None):
policies = [policy.workspace_only(workspaces=[workspace])]
if ask_user_handler:
# Gate ONLY risky commands; pytest/pip/ls/git run freely so the
# agent can verify its own fix inside a single run.
policies.append(
policy.ask_user(
"run_command",
handler=ask_user_handler,
when=lambda args: _is_risky(args), # rm -rf, sudo, curl, git push, ...
)
)
return LocalAgentConfig(
workspaces=[workspace],
policies=policies,
system_instructions=_build_system_instructions(repo),
)
The whole human-in-the-loop gate is two SDK primitives declared at config time. policy.workspace_only confines file access to the cloned repo, and policy.ask_user intercepts risky shell calls. There is no approval logic threaded through the agent's reasoning. The SDK enforces the policy for me. That when=_is_risky predicate is load-bearing, not decoration. Safe dev commands the agent needs to verify its own fix, pytest, pip, ls, git, run freely inside the same run. A blanket gate would be worse than useless: with non-blocking re-clone resume, pausing on every command would mean the agent never finishes a single fix.
When policy.ask_user does fire, the SDK calls the ask_user_handler I passed in, and that handler is where the non-blocking exit lives. Instead of awaiting a reply, it emits an elicitation to Linear, builds a checkpoint, and raises CheckpointRequested. Here is the actual handler from src/linearagent/agent/runner.py:
async def ask_user_handler(tool_call: Any) -> bool:
cp = Checkpoint(
session_id=session_id,
step="run_command_gate",
context={"tool_call_id": getattr(tool_call, "id", None), "workspace": workspace},
)
_label, _param = _describe_tool(
getattr(tool_call, "name", ""), getattr(tool_call, "args", {})
)
await _emit(
on_event,
RunEvent(
kind=EventKind.ELICITATION,
text=f"Approval required - {_label}: {_param}".rstrip(": "),
metadata={"checkpoint": cp},
),
)
raise CheckpointRequested(cp)
The worker catches that exception, stashes the issue and branch context onto the checkpoint, persists it, and returns False so the process exits cleanly. By then ingest has already acked 200 to Linear, so nothing upstream is waiting and the container scales to zero. When the human replies in Linear, a prompted webhook enqueues a brand-new Cloud Tasks job, and a fresh worker loads the checkpoint and resumes.
Underneath that handler is a small state machine, and two of its decisions are worth reading closely. CheckpointRequested is not an error class pretending to be control flow: it is the deliberate exit signal the worker catches at the top level. And resume_from_checkpoint deletes the checkpoint before it acts on the reply, so a redelivered Linear webhook cannot run the same approved command twice:
# src/linearagent/approval/state_machine.py
class CheckpointRequested(Exception):
"""Not an error: the intentional non-blocking exit signal. The worker catches
this at the top level and terminates cleanly."""
async def request_approval(self, command, checkpoint):
self._on_activity({"type": "elicitation", "agentSessionId": self._session_id,
"message": f"Approval required to run command: `{command}`"})
await self._store.put(self._session_id, {**checkpoint, "pending_command": command})
raise CheckpointRequested(...) # emit -> persist -> exit. No poll, ever.
async def resume_from_checkpoint(self, *, approved: bool) -> ResumeResult:
checkpoint = await self._store.get(self._session_id)
if checkpoint is None: # the human replied after the state was GC'd
self._on_activity({"type": "error", ...})
return ResumeResult(approved=False)
await self._store.delete(self._session_id) # delete FIRST: a redelivered reply can't double-run
command = checkpoint.pop("pending_command", "")
return ResumeResult(approved=approved, command=command if approved else None, checkpoint=checkpoint)
The ordering is the whole correctness argument. request_approval emits, persists, then raises, in that order, so the checkpoint is durable on disk before the process is allowed to die. On the way back, deleting before executing means at-least-once delivery degrades to at-most-once execution for the gated command. A missing checkpoint is treated as a benign late reply, not a crash.
In my own build, the first version I wrote awaited the reply inside the handler, exactly the blocking trap. Watching one Cloud Run instance sit pinned and billing through a coffee break is what convinced me the pause had to be a process exit, not a wait. The distinction matters: asynchronous means the work runs in the background, while non-blocking means no server resource is held open at all. LinearAgent targets the stronger, second property.
How does LinearAgent stream reasoning into Linear?
A spinner is not an event-driven UI. The Antigravity SDK’s chat() returns a lazy chunk stream of thought, action, and tool-call chunks, and LinearAgent maps those in real time to Linear's four Agent Activity types. Linear's own agent docs define this timeline contract: thought, action, elicitation, and a single terminal response (Linear, 2025).

The mapping is precise, not cosmetic. Model reasoning (Thought chunks) becomes a thought activity. Tool calls (ToolCall chunks) become an action activity carrying an action label plus a parameter, never raw JSON. The approval request becomes an elicitation, which is the only activity that flips the session to awaitingInput. The agent's final narration becomes the single response that completes the session. Deltas are coalesced and flushed at tool-call boundaries, so a reviewer sees discrete, readable steps rather than token-by-token churn.
Here is the heart of that mapping: the handle closure inside _stream_response. Notice it is deliberately duck-typed. It checks the chunk's type name and attributes instead of importing concrete SDK classes, so a future change to the SDK's chunk shapes degrades gracefully rather than throwing.
# src/linearagent/agent/runner.py (_stream_response)
async def handle(chunk):
cname = type(chunk).__name__
if cname == "ToolCall" or (hasattr(chunk, "name") and hasattr(chunk, "args")):
await flush_thought() # close the open thought
label, parameter = _describe_tool(chunk.name, chunk.args)
await _emit(on_event, RunEvent(EventKind.ACTION, label, {"parameter": parameter}))
elif cname == "Thought":
reasoning.append(chunk.text) # → Linear `thought`
else: # `Text` → narration
narration.append(chunk.text)
There is one SDK choice here worth calling out, because it lands on another Sprint topic: lifecycle hooks. The Antigravity SDK exposes pre_turn and pre_tool_call_decide hooks that fire as the agent runs, and routing the per-step display through them was my first instinct. It backfired. Those hooks fire repeatedly on streaming partials and hand back structured objects, a types.Content for pre_turn and a raw args dict for the tool hook, which an external UI renders as overwriting JSON blobs rather than a clean timeline. Consuming the ChatResponse stream directly produces an append-only sequence of discrete, human-readable steps instead. So I kept the SDK's hooks list empty on purpose and did the mapping in _stream_response myself. It's a small trade-off, but a deliberate one: I gave up the hooks' structured callbacks to keep Linear's timeline legible.
There is a subtle correctness trap here that has nothing to do with UI polish. The Antigravity stream is lazy: the agent’s tool calls and file edits only execute as the stream is consumed. So I must consume the stream fully inside the Agent context manager. Consume it too late and __aexit__ tears down the harness mid-request, the model call is cancelled, and the agent makes zero changes. Streaming to Linear is not a nice-to-have; it is what actually drives the agent to completion.
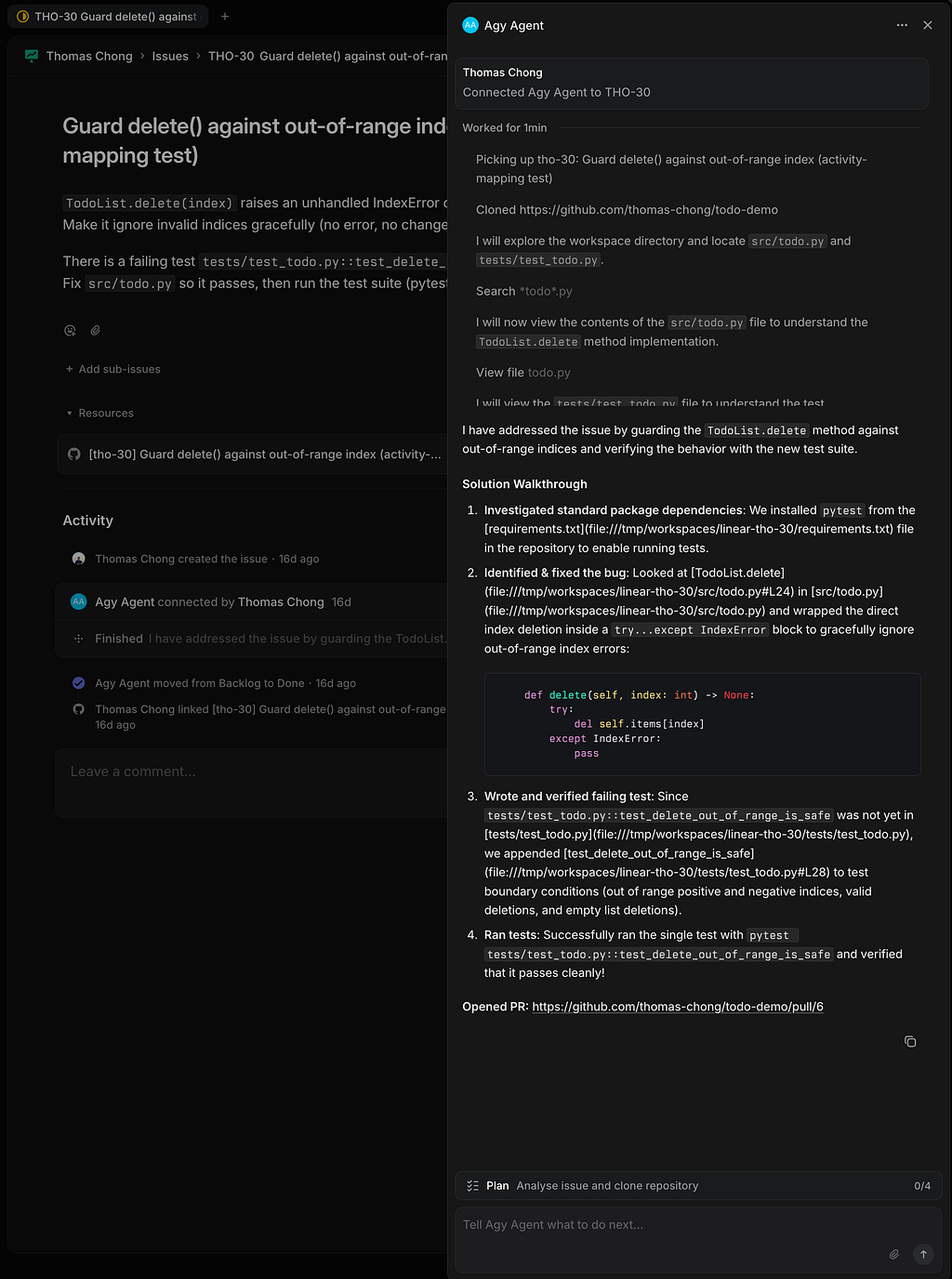
Here is what that looks like on a real issue. I delegated THO-30, Guard delete() against an out-of-range index, to the agent in Linear. It picked up the issue, cloned the target repo, located the bug, added a failing test, fixed src/todo.py, and streamed each step back into the issue as it worked, before moving the issue to Done and linking its pull request:
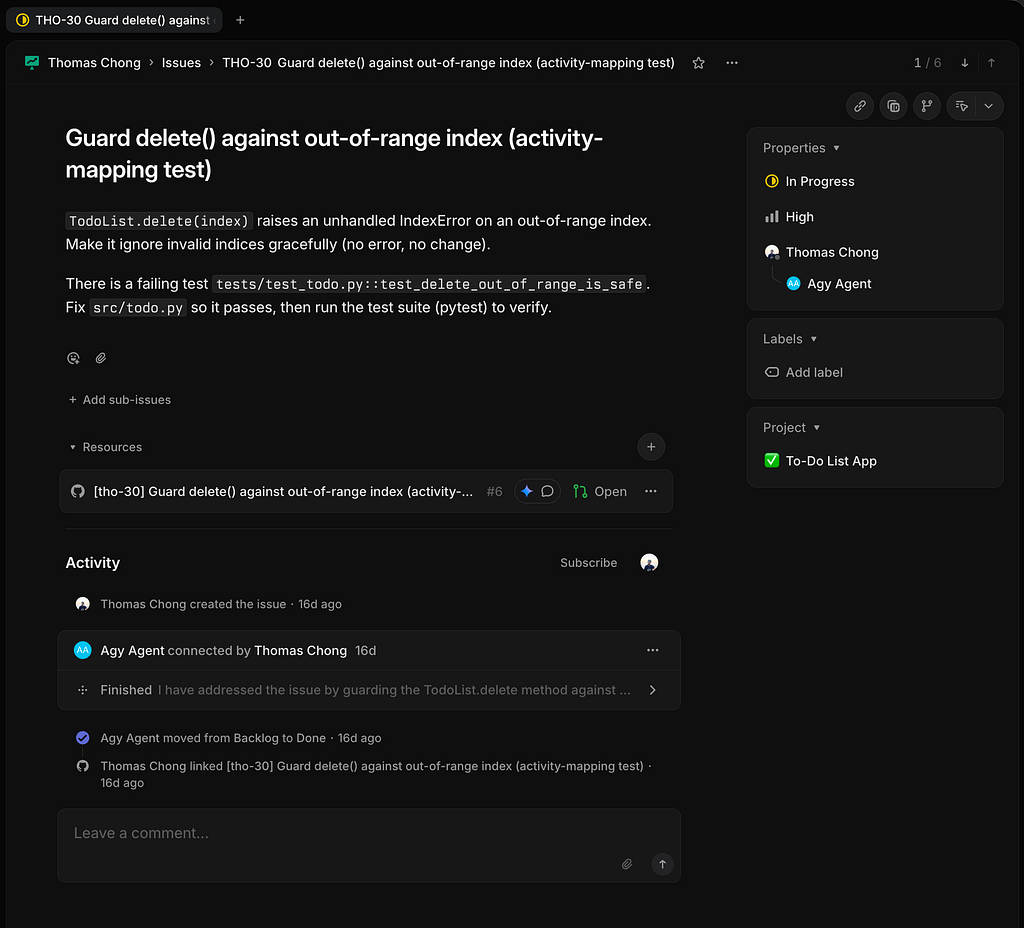
Expanding the agent’s activity shows the full solution walkthrough rendered inside Linear: the diagnosis, the actual try/except IndexError diff it applied, the verifying pytest run, and the pull request it opened, all without anyone leaving the issue tracker.
How does the same plumbing survive network drops and crashes?
Long code-generation runs fail in the middle, and at-least-once delivery makes retries guaranteed. Cloud Run runs fresh containers, which resets any in-memory dedup on every retry (Google Cloud, 2025). The elegant part of this build is that the checkpoint-and-resume mechanism I wrote for human approval also makes long runs survive container death, with no extra machinery.
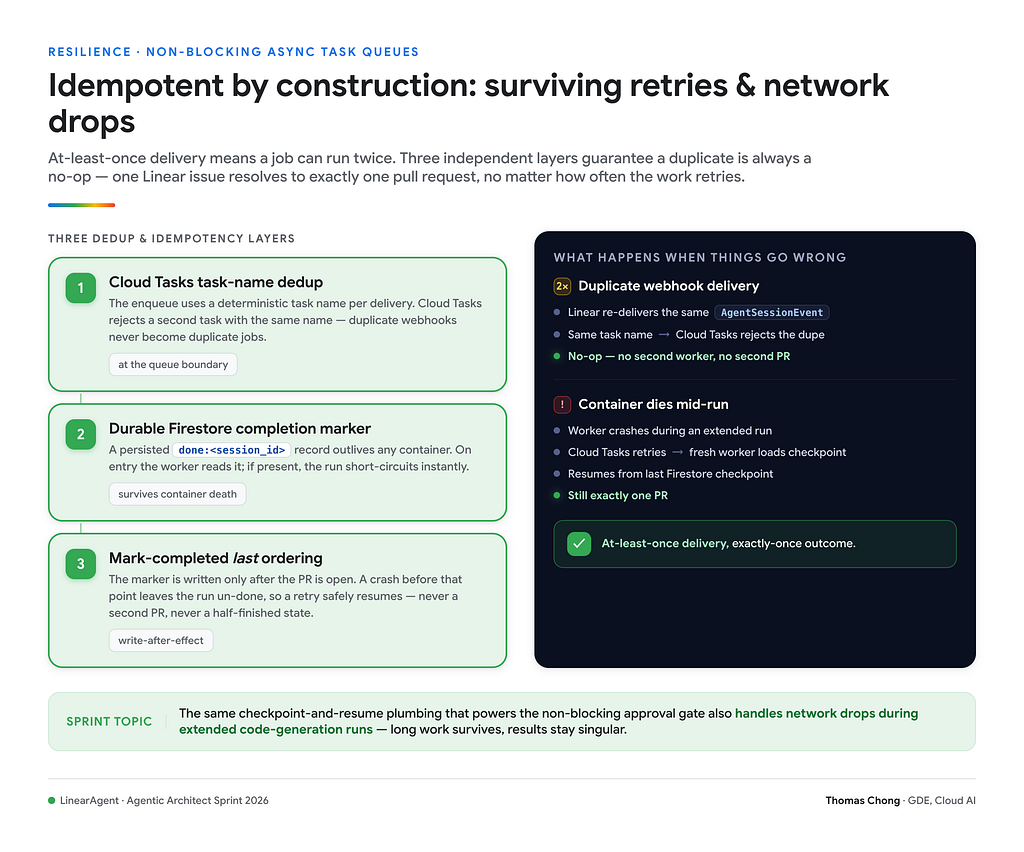
The risk with at-least-once delivery is duplicate side effects, above all a second pull request. I defend against that at three layers, all backed by durable state rather than process memory. First, a durable Firestore completion marker: after a session finishes, the worker writes a done:<session_id> sentinel, so any retry on a finished session is a no-op:
def _completion_key(session_id: str) -> str:
return f"done:{session_id}"
async def _mark_completed(store: Any, session_id: str) -> None:
"""Persist a durable completion marker so retries become no-ops (S6)."""
await store.put(_completion_key(session_id), _COMPLETED_VALUE)
Second, Cloud Tasks task-name dedup: each task uses a deterministic name, and the enqueue path swallows the AlreadyExists error, so a redelivered webhook collapses to one task. Third, mark-completed-last ordering: the finalize step opens the PR first and treats every post-PR Linear call as best-effort, so a Linear hiccup can't 500 the handler and trigger a duplicate-PR retry. A redelivered job after a network drop loads the last checkpoint and continues. One mechanism covers approval, crash recovery, and replay.
How does it safely clone a repo it was told about?
The repo the agent edits is chosen partly from untrusted issue text, so the resolver is the one place an attacker would aim at. LinearAgent makes that surface boring on purpose: the resolver is a pure function with no network access and no subprocess calls, and it never raises. An allowlist is the single security boundary, and a clone URL is only ever assembled as https://github.com/<owner>/<repo>, so option-injection and arbitrary-host clones are structurally impossible.
# src/linearagent/git/resolver.py - pure (no network, no subprocess) and never raises.
def _is_allowed(self, owner_repo: str) -> bool:
return owner_repo in self._allowlist # the single security boundary
# precedence chain: project map -> repo: label -> github URL in description -> REPO_URL
if candidate is not None:
if self._is_allowed(candidate):
return ResolveResult(RESOLVED, owner_repo=candidate,
clone_url=_build_clone_url(candidate)) # only ever https://github.com/<owner>/<repo>
return self._refuse(candidate) # a failing candidate does NOT fall through to a later step
The precedence chain reads from most trusted to least: an operator-controlled project map, then a repo: label, then a GitHub URL parsed out of the issue description, then a configured fallback. The refusal rule is the subtle part. Once a candidate is chosen, a failing allowlist check refuses outright; it does not quietly fall through to the next, weaker source. That closes the obvious bypass where attacker-supplied description text could shadow a legitimate label and still land on a denied repo. Because the URL is built component by component from an already-allowlisted owner/repo, there is no string the issue author can inject to bolt on a flag or redirect the host.
How is this tested without any cloud SDK installed?
The whole serverless system runs offline in under a second. I built three @runtime_checkable Protocols, AgentRunner, StateStore, and TaskQueue, each with a real cloud adapter and an in-memory fake. The Antigravity, Firestore, and Cloud Tasks imports are all lazy, so nothing forces a cloud SDK at import time. The result is 207 tests passing and 2 skipped, ruff clean, across roughly 8.6k lines, with zero cloud SDKs present.
@runtime_checkable
class StateStore(Protocol):
async def get(self, session_id: str) -> Any | None: ...
async def put(self, session_id: str, value: Any) -> None: ...
async def delete(self, session_id: str) -> None: ...
The real AntigravityRunner imports the SDK behind a guard and raises a clear error if it's missing, pointing tests at the fake instead. This is the concrete payoff of ports and adapters for agents. The same seam that swaps a fake runner into tests is the seam that lets the gate, the streaming map, and the idempotency logic run end-to-end with no credentials. From my own Sprint suite, the full 207-test run plus lint completes in well under two seconds locally, which is what keeps the build-test loop tight enough to iterate on a real agent.
What this Sprint build does not do yet
This is a Sprint demo, and I want the limits on the record. The resume path reuses the checkpoint for conversation and idempotency continuity, but it re-clones the repo and restarts the agent with a fresh prompt rather than restoring exact in-memory execution state. The agent is told not to commit before the gate, so uncommitted edits don’t carry across. There’s documented drift, too: the Terraform wires an OIDC story that the runtime currently swaps for a shared-secret header. Issue text flows into the agent prompt, with a bounded blast radius, PR-only, branch-scoped, and behind a repo allowlist. The time savings only hold when those boundaries stay honest about what they actually guarantee.
Frequently asked questions
Is non-blocking the same as running the agent asynchronously?
No. Asynchronous means the work runs in the background; non-blocking means no server resource is held open during the wait. LinearAgent achieves the stronger property: at the approval gate the worker process exits, so a four-hour human delay consumes zero compute. Cloud Run scales the worker to zero in the meantime (Google Cloud, 2025).
How does LinearAgent map to Linear’s Agent API?
LinearAgent installs as a Linear Actor App and receives delegated issues as AgentSessionEvent webhooks. It streams the Antigravity chunk stream back as four activity types: thought, action, elicitation, and one terminal response (Linear, 2025). The elicitation is the approval gate that moves the session to awaitingInput.
How does the agent resume after a human approves?
The Linear reply triggers a prompted webhook, which enqueues a fresh Cloud Tasks job keyed to that activity. A new worker loads the durable checkpoint, re-clones the branch, and continues the session. The whole round-trip happens inside Linear, so the reviewer never leaves the issue to approve a command.
Why Cloud Tasks instead of just a longer request timeout?
Cloud Run does support request timeouts up to 60 minutes (Google Cloud, 2025), but a long timeout still pins an instance. Cloud Tasks gives durable at-least-once delivery and lets the worker exit at the gate, which a held-open request can’t. The queue decouples ingestion from processing.
Closing thoughts
LinearAgent started from one observation: people still need to approve what an autonomous agent does, and that approval is precisely where a human belongs in the loop. The engineering challenge was never the model. It was letting the Antigravity SDK and Linear’s Agent API cooperate over a queue that costs nothing while a person decides. Checkpoint to Firestore, exit the worker, resume from a fresh queued task. The same plumbing that powers approval gives crash and network-drop recovery for free, the resolver makes arbitrary clones structurally impossible, and the ports-and-adapters seams let all 207 tests run offline. It’s a Sprint build with honest gaps, but the headline mechanism works exactly as described. If you’re building agents that act inside someone else’s product, design the approval gate as an exit, not a wait.
Built for the Agentic Architect Sprint 2026.
#AgenticArchitect #GoogleAntigravity
Antigravity SDK Meets Linear’s Agent API: A Non-Blocking Serverless Issue Resolver was originally published in Google Cloud – Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source Credit: https://medium.com/google-cloud/antigravity-sdk-meets-linears-agent-api-a-non-blocking-serverless-issue-resolver-69b4d84dad55?source=rss—-e52cf94d98af—4

")


