
why stateless RAG architectures fail in production, and how to build autonomous systems that survive the physics of distributed data
In the evolution of data systems, we often see a recurring pattern: we begin by building systems that allow us to look at data (Analytics), then systems that allow us to search for data (Retrieval), and finally, systems that allow us to act on data (Agency).
We are currently at the precipice of that third stage. However, the industry is approaching “Agentic AI” with a stateless mindset that is fundamentally incompatible with the realities of distributed systems. We are attempting to build autonomous agents on top of static, request-response architectures — essentially trying to build a self-driving car by taking a series of polaroid photos of the road and sending them to a remote server for instructions.
To build truly autonomous intelligence, we must move away from “Retrieval-Augmented Generation” (RAG) and toward stateful serverless Agentic Loops. We must stop thinking in snapshots and start thinking in streams.
The Impedance Mismatch: Why Stateless AI Fails at Scale
- The Latency of Stale Data: In a traditional RAG setup, an LLM queries a vector database. By the time the vector is indexed, the embedding generated, and the query returned, the state of the world has already changed. In high-frequency environments like fraud detection or supply chain logistics, a 500ms-2s delay isn’t just a performance metric — it’s a window for failure. As per the latest statistics , the latency between rom initial infiltration to data exfiltration has plummeted to just 39s and 90% of attacks are resulting in data exfiltration.
- The “Ghost Action” Problem: In distributed systems, retries are inevitable. Kafka guarantees at-least-once delivery. If an autonomous agent has a “write socket” — the ability to execute a trade, ban a user, or move a shipping container — and it lacks stateful memory of its own past actions, it will inevitably execute the same command twice. These are “Ghost Actions,” the catastrophic side-effect of stateless agency.
- The Token Tax: LLMs are computationally expensive and economically punishing. Running complex “chain of thought” reasoning for every event in an unbounded stream is a path to financial ruin.
The Architectural Imperative: Elevating State to a First-Class Citizen
To solve this impedance mismatch, we need a system that treats state as a first-class citizen. We must separate execution into a dual-layered architecture: a synchronous fast-path (System 1) and an asynchronous slow-path (System 2). This satisfies both the economic constraints of the C-Suite (latency and token cost) and the physical requirements of engineering (determinism and concurrency).
Component Topology: The Nervous System and the Dual-Layered Brain
A resilient Agentic Loop requires three distinct architectural pillars.
1. The Nervous System: Apache Kafka
Kafka serves as the durable, append-only log. By piping the agent’s outputs back into a Kafka topic, we create a recursive feedback loop, allowing the AI to observe the results of its own decisions.
2. The Stateful Reflexive Brain: Apache Flink
Flink is the System 1 to the LLM’s System 2. Flink manages “Short-Term Memory” using a distributed state backend like RocksDB, provisioned on local NVMe SSDs to survive the I/O saturation of 50K-1M events per second. It handles:
- Ordered Async I/O: Flink fires thousands of concurrent requests to the Agent without blocking the stream via RichAsyncFunction using orderedWait to maintain cryptographic causal ordering.
- Idempotency Ledger: Flink synchronously queries RocksDB to drop duplicates at the edge before they hit the LLM.
3. The Analytical Brain: Google Cloud Run & Embedded OLAP
For deep reasoning, we utilize a serverless, horizontally scalable environment. However, placing an LLM in isolation creates a blind spot. We co-locate an embedded OLAP database (ClickHouse) alongside the Agent. This architectural proximity allows the LLM to execute sub-millisecond aggregations to establish historical baselines before reasoning.
Inference Memoization (Redis / Google Memorystore): Before the Cloud Run Agent invokes the expensive LLM, it checks a fast, external memory cache keyed by the Flink-generated Request_ID. For enterprise deployments on GCP, utilizing Google Memorystore for Redis ensures sub-millisecond, VPC-native latency. If the decision is cached, the Agent instantly returns the historical mitigation, bypassing the LLM entirely and preserving the token budget.
System Dynamics: Orchestrating the Reflexive Fast-Path and Analytical Slow-Path
When we synthesize these components, the data flow evolves from a linear path into a self-reinforcing, stateful circle. To satisfy both the economic constraints of the C-Suite (token cost) and the physical requirements of the engineering team (determinism and concurrency), the pipeline explicitly separates execution into the synchronous Fast-Path and asynchronous Slow-Path.
To truly grasp the impact of this architecture — especially the “Token Tax” and the mathematical necessity of the Semantic Cache — we can visualize the system dynamics interactively.
The above blueprint visualizes the physical separation of our architecture into two distinct operational planes to survive enterprise-scale throughput. The left side represents System 1 (The Reflexive Fast-Path), powered by Apache Flink and bounded by strict hardware realities — specifically, local NVMe SSDs running RocksDB to prevent I/O saturation during 50,000 TPS volumetric attacks. This layer handles deterministic stream ingestion, idempotency checks, and instant mitigations via the BroadcastState cache without ever invoking the AI. When a novel anomaly forces a cache miss, the system escalates to the right side: System 2 (The Analytical Slow-Path). Here, the Flink TaskManager fires a masked gRPC payload to a serverless Cloud Run Agent. The LLM leverages a Model Context Protocol (MCP) Server to query an embedded ClickHouse instance for historical baselines, generates a deterministic new rule, and passes it back to Flink via an asynchronous callback to actuate the defense and update the globally distributed cache.
The Blueprint: From Protocol to Protection
When we synthesize these components, the data flow evolves from a linear path to a self-reinforcing circle.
- Ingestion: Unbounded event data (telemetry, logs, transactions) enters the Kafka ingress topic.
- Stateful Interception: Flink intercepts the event. It checks the Idempotency Ledger (Is this a duplicate?) and the Semantic Cache (Do I already know how to handle this?).
- Non-Blocking Inference: If the event is novel, Flink pushes a compact context package to the Agent on Cloud Run.
- Action & Feedback: The Agent returns a command. Flink executes the command, updates its internal state, and pipes the result back into Kafka.
- Closing the Loop: The Agent observes the command’s impact on the stream, refining its future reasoning.
Production Data Planes: Executing Agency at Enterprise Scale
Fraud Mitigation in Fintech
In a stateless world, an LLM might identify a fraudulent transaction, but it cannot “see” the 500 similar transactions happening in the same millisecond. With a Stateful Agentic Loop, Flink identifies the pattern, the Agent authorizes a quarantine, and Flink instantly applies that “quarantine” signature to every other transaction in the buffer — stopping the bleeding before the second dollar is lost.
Global financial networks experience out-of-order data. By configuring allowedLateness on the Windowed Stream, Flink keeps the RocksDB state alive just long enough to evaluate straggler events against the historical cache. Furthermore, because network attacks heavily skew Kafka partitions (leaving some idle), the architecture strictly requires WatermarkStrategy.withIdleness() to ensure temporal state eviction continues uninterrupted, preventing OOM collapses during volumetric botnet attacks.
Autonomous Supply Chain
A streaming agentic loop observes an entire shipping “fleet” as a unified stream. It recognizes that rerouting Vessel A will cause a bottleneck for Vessel B and calculates a globally optimized flow. Because this implies massive state sizes, operators rely on Flink Savepoints to upgrade topologies. To survive evolving reasoning logic without losing the “memory” of where every shipping container is located, the system utilizes State Schema Evolution via Apache Avro or Protobuf, guaranteeing forward and backward compatibility.
Day 2 Operations: Surviving Split-Brains, I/O Saturation, and Semantic Drift
Architecture goes from theory to production when you solve for “Day 2” failure modes.
- The Split-Brain Replay (LLM Determinism): If Flink crashes and replays a stream, the LLM might hallucinate a different mitigation for the exact same historical event. We combat this by embedding a strictly Monotonic Sequence Number alongside the Request_ID. ClickHouse’s ReplacingMergeTree uses this to overwrite stale payloads, preventing the split-brain physics of GPUs from corrupting state. We mandate FINAL modifier queries to force read-time deduplication.
- The Payload Explosion: To maintain Read-After-Write consistency against database lag, Flink cannot send raw event arrays over gRPC — it would saturate network bandwidth. Instead, Flink maintains a rolling Count-Min Sketch (CMS) of recent actions. Sized to a strict 0.01% error bound, this kilobyte-sized structure allows the LLM to process probabilistic uncertainty without triggering a network collapse.
- The Wall-Clock Fallacy: If Flink replays 2-hour-old data and the Agent queries the database using its local NOW() clock, it compares historical anomalies against the wrong baseline. To guarantee Event-Time Determinism, Flink embeds the original Kafka timestamp into the gRPC payload, acting as the absolute anchor for Model Context Protocol (MCP) queries.
- The IAM/gRPC Boundary: To prevent IAM token exhaustion during a Thundering Herd, Flink operates a Persistent Connection Pool with an Asynchronous Token Refresher, while acting as a Data Masking Gateway to ensure raw PII never crosses the serverless boundary.
- The Replay Token Tax & Single-Threaded Bottlenecks: When Flink inevitably scales or recovers from a crash, it rewinds Kafka offsets and replays the stream. While downstream idempotency protects the databases, re-triggering the RichAsyncFunction means paying the LLM provider a second time for identical reasoning — the Replay Token Tax. We prevent this via Inference Memoization. However, a 50,000 TPS stream replay will instantly saturate standard Redis due to its single-threaded architecture. For Tier-0 workloads, the architecture swaps Redis for Dragonfly — a multi-threaded, shared-nothing, drop-in replacement. Dragonfly easily absorbs the massive concurrent read spikes on a single node without the network latency overhead of cluster sharding.
- Legacy Downstream APIs (The Outbox Pattern): Enterprise networks feature legacy firewalls that do not support idempotency keys. To prevent state corruption via blind retries, the Agentic Loop falls back to the Outbox Pattern or a Compensation Transaction, writing intent to a transactional topic first.
- The 2PC Checkpoint Latency Trap: Flink native exactly-once output introduces a 10-second checkpoint delay. The architecture bypasses this by configuring the Kafka Sink for AT_LEAST_ONCE delivery, relying entirely on the downstream Firewall API and ClickHouse for deduplication.
- LLM Provider Outages (Circuit Breakers): A Dead Letter Queue cannot prevent a system collapse during a total regional outage of the LLM provider. We utilize the Circuit Breaker Pattern inside the Slow-Path: if the failure rate exceeds a threshold, Flink stops calling Cloud Run entirely and routes anomalies to a static ‘Fail-Safe Ruleset’.
- Global State Externalization: To survive a total cloud region failure, Flink bootstraps its local RocksDB state from a globally distributed, strongly consistent store (like Cloud Spanner) where critical idempotency markers and high-value Semantic Cache rules are asynchronously replicated.
- Semantic Drift & Shadow Agency: Upgrading an AI reasoning model introduces Semantic Drift. A v2 model might generate hyper-aggressive rules that shut down legitimate traffic. We utilize Shadow Agency: Flink mirrors traffic to a Shadow Agent running the v2 model. It records mitigations without actuating them, allowing engineers to mathematically verify the delta before critical-path promotion.
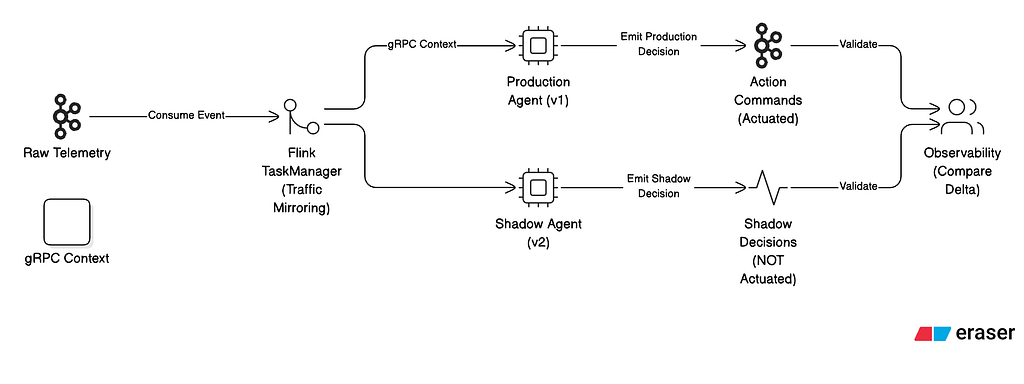
The figure details our critical “Day 2” operational safety mechanism for deploying non-deterministic reasoning models to a live production environment. Upgrading an LLM introduces the severe risk of “Semantic Drift,” where a new model version might interpret historical baselines differently and generate hyper-aggressive rules that inadvertently shut down legitimate global traffic. To mathematically eliminate this risk, the diagram shows a Flink TaskManager acting as a Git-like dispatcher, utilizing traffic mirroring to duplicate the RichAsyncFunction payload. The live Production Agent (v1) actuates real mitigations on the critical path, while the Shadow Agent (v2) evaluates the exact same live telemetry but writes its decisions to an isolated observability topic. This "Shadow Loop" allows data science and engineering teams to continuously validate the delta between the two models in real-time, proving the v2 model's safety and efficacy before it is promoted to control the actual data plane.
The Endgame: Deprecating the “Database as a Crutch”
For years, the industry has treated databases as the place where data goes to rest, and AI as the tool we use to wake it up. But the future of engineering does not belong to the static query; it belongs to the continuous flow.
To deploy autonomous systems at scale, we must recognize an undeniable engineering truth: Large Language Models are inherently non-deterministic, stateless functions, and Kafka is a deterministic, stateless pipe. Attempting to bind them directly guarantees systemic collapse through race conditions, distributed dual-writes, and unmanageable token costs.
Apache Flink serves as the mathematically rigorous, stateful bridge that binds them safely. By moving state to local NVMe SSDs, enforcing strict Event-Time determinism, bounding payloads with probabilistic sketches, and isolating the Control Plane from the Data Plane, we physically force the stochastic LLM to respect the causal ordering of distributed systems.
By integrating stateful stream processing with serverless agency, we move beyond simple automation. We build systems that are not just “smart,” but mathematically reliable, idempotent, and economically viable. We are no longer just building models; we are building the autonomous nervous systems for the modern enterprise. The Streaming Agentic Loop is more than a design pattern — it is the blueprint for the next decade of data-intensive applications.
Designing stateful serverless Agentic Loop: Real-Time Reasoning at Scale was originally published in Google Cloud – Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source Credit: https://medium.com/google-cloud/designing-stateful-serverless-agentic-loop-bb73a63562b4?source=rss—-e52cf94d98af—4

 in Cisco Catalyst SD-WAN Manager")

