
This is Part 4 of a five-part series on building an AI agent with reflective memory on Google Cloud, from the core concept to a verified implementation.
TL;DR: Anthropic’s Dreams lets a managed agent sleep on past sessions and wake up with cleaner memory. On Google Cloud, you can build the same pattern yourself: keep the live session as evidence, let Memory Bank remember the user, let a Cloud Run Job reflect on completed task trajectories, store the lessons in Firestore, and retrieve both before the next action.
Anthropic recently gave managed agents a way to sleep on it. With Dreams, Claude reviews past sessions and an agent’s existing memory while the agent is idle, then produces a cleaner memory store for future sessions: duplicates merged, stale facts updated, contradictions resolved, and new patterns added.
That is a catchy product feature, but the architecture lesson is bigger than the product:
The agent works now. The harness reflects later. The next action starts with better memory.
This post builds that pattern on Google Cloud with components you own: Memory Bank, Firestore, embeddings, and a scheduled Cloud Run Job. There is one important difference from Anthropic’s managed Dreams: their feature curates a memory store from past sessions, while this architecture splits memory into two jobs:
- learn the user: derive durable user facts from conversations;
- learn the job: derive reusable lessons from completed task trajectories.
Both are reflective memory. They just run over different evidence.
The architecture
Dana opens a support ticket:
The billing page will not load.
To answer well, the agent needs two different memories. It needs to remember Dana: she is an administrator at ACME, on the Enterprise plan, and prefers concise troubleshooting. It also needs to remember the job: similar “page will not load” tickets often turn out to be missing roles, so permissions should be checked before generic browser advice.
Those memories come from different places, on different timelines:
- the user facts come from conversations;
- the job lesson comes from a completed support trajectory;
- the current ticket lives in the active session.
The architecture is:
Keep the live session as evidence. Write user facts and job lessons through separate reflection paths. Retrieve both into one scoped context before the agent acts.
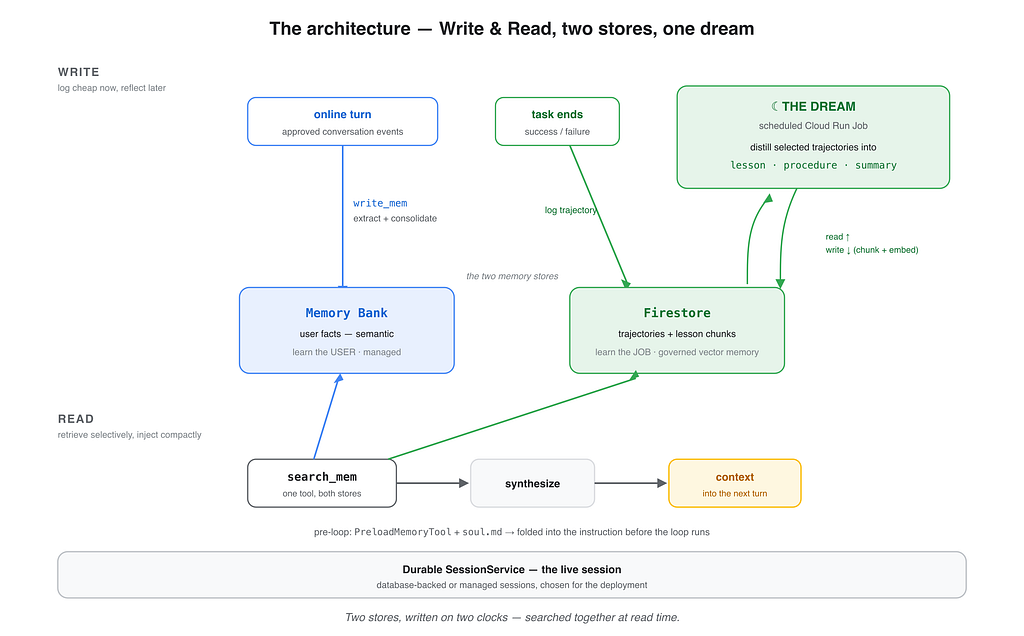
The database choices matter less than the separation of responsibilities:
- Cloud SQL or managed Sessions keeps the active conversation durable.
- Memory Bank manages user-facing long-term memory.
- Firestore stores trajectories and derived job lessons.
- Cloud Run Job runs the offline reflection process.
- A recall tool merges scoped user facts and job lessons at runtime.
That is the harness doing memory.
Start with evidence, not memory
The live session is not long-term memory. It is evidence: messages, tool calls, intermediate state, and outcomes. ADK represents this through a SessionService; in production, that should be durable rather than in-memory.
This distinction prevents the common mistake:
A persisted transcript is not the same thing as useful memory.
A transcript records what happened. Reflective memory records what the system learned from what happened, so the harness keeps the session and derives smaller memory artifacts from it.
Write path one: Memory Bank remembers the user
The first write path is the managed one. At a deliberate lifecycle point, the application sends relevant conversation events to Memory Bank, which can generate and consolidate durable user facts under identity scope.
For Dana, that might become:
Dana is an administrator at ACME.
ACME is on the Enterprise plan.
Dana prefers concise troubleshooting steps.
This path matters because the final recall step needs user context, but it is not the hard part of this post. The harder part is the second write path: teaching the agent from completed work.
Write path two: the agent learns the job
The second reflection path begins after a task finishes. Suppose the support agent first suggests clearing the browser cache. That fails. Later, an account check finds the real cause: Dana is missing the billing role.
The harness records a structured trajectory:
agent_id: support_agent
user_id: dana
task: billing page will not load
actions: [suggest cache clear, check account, check billing role]
outcome: resolved
root_cause: missing billing role
The most important field is the outcome.
Without the outcome, reflection tends to produce vague advice like “diagnose the issue carefully.” With the root cause and resolution, reflection can produce a reusable lesson:
For permission-gated pages, verify account status and resource roles
before generic browser troubleshooting.
This is why the trajectory store should not be a raw transcript dump. It should record enough structure for later reflection to know what actually worked. In this architecture, the trajectory is written to Firestore and marked processed: false, which turns Firestore into the dream job's work queue.
The dream is a scheduled reflection job
The dream is the background process that turns completed trajectories into reusable job memory. Technically, it is a Cloud Run Job triggered by Cloud Scheduler. It does not serve live HTTP traffic; it starts, processes a batch, writes derived memories, and exits.
The job:
- reads unprocessed trajectories;
- selects the ones worth reflecting on;
- asks Gemini to derive a lesson or procedure;
- validates the result and applies scope;
- embeds the approved memory;
- writes it back to Firestore for retrieval;
- marks the source trajectory as processed.
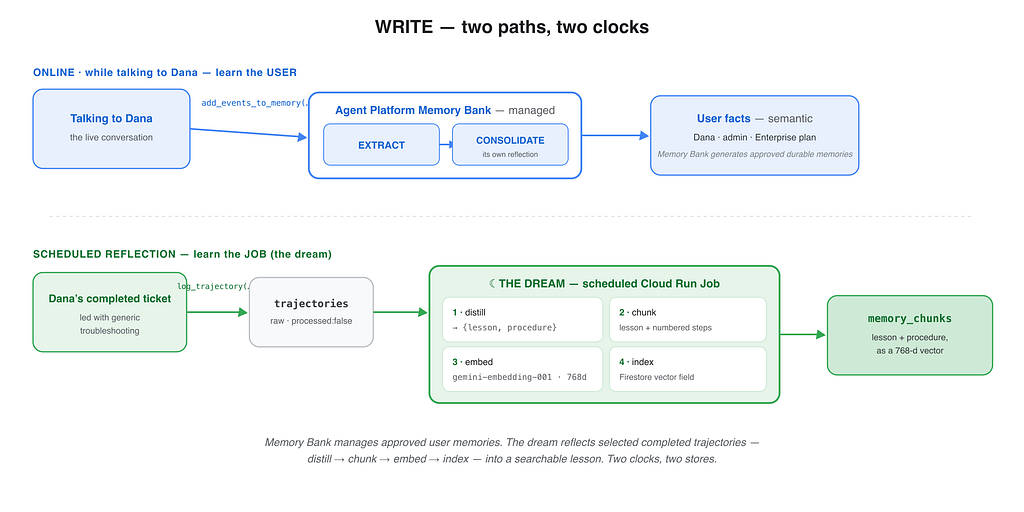
Scheduled reflection is a design choice, not a law. If an agent needs to retry immediately, reflection may happen synchronously between attempts. For many systems, though, batch reflection is better: it keeps expensive reasoning off the live path, supports consolidation, and gives you a place for review, confidence checks, and expiry.
Every derived lesson should keep:
- its source trajectory;
- its scope;
- its confidence or review status;
- its expiry or freshness policy.
That traceability matters because a reflective system can preserve a wrong conclusion as faithfully as a correct one.
Embeddings make lessons usable later
Future tickets will not repeat the exact same words. “Billing page is blank,” “I cannot open invoices,” and “the page will not load” may all need the same permissions-first procedure, so the dream embeds the approved lesson and stores the vector in Firestore. At retrieval time, the harness embeds the current query and uses Firestore vector search to find nearby lessons.
The durable rule is simple:
Store and query with the same embedding model, task convention, and vector dimensions.
The specific model can change. The architectural responsibility does not.
Read path: merge facts and lessons before acting
When Dana opens the next ticket, the agent should not choose between user memory and job memory. It needs both, and a custom recall tool can query both stores:
async def recall(query, tool_context):
user_facts = await tool_context.search_memory(query)
job_lessons = search_job_memory(query, scope=current_scope)
return {
"user_facts": user_facts,
"job_lessons": job_lessons,
}

Memory Bank returns context about Dana. Firestore returns the permissions-first lesson. The tool formats both into one scoped payload:
Customer context:
Dana is an Enterprise administrator at ACME.
Relevant job lesson:
For permission-gated pages, verify account status and resource roles
before generic browser troubleshooting.
Now the agent can make a better first move:
Let me check your billing role before we try browser troubleshooting.
This does not guarantee success. It changes the starting point, which is what reflective memory is supposed to do.
One implementation note matters: this is a composition pattern, not a special built-in ADK multi-store abstraction. ADK can wire Memory Bank as the memory service, but the Firestore lesson lookup is owned by your custom tool. Filtering, ranking, scoping, and formatting are harness responsibilities.
One guardrail matters here: similar does not mean allowed. A lesson can be relevant and still belong to the wrong user, tenant, or agent, so the recall tool should enforce scope before returning anything. Private memories stay private, agent-domain lessons stay within their domain, and shared lessons require stronger review. Do that filtering in the query and tool layer, not after the model has already seen the memory.
The loop you are building
The whole architecture has one rhythm:
- The live session records what happens.
- Memory Bank derives approved user facts.
- Firestore records completed task trajectories and outcomes.
- The dream derives scoped job lessons.
- Retrieval merges facts and lessons before the next action.
- The next action becomes new evidence.
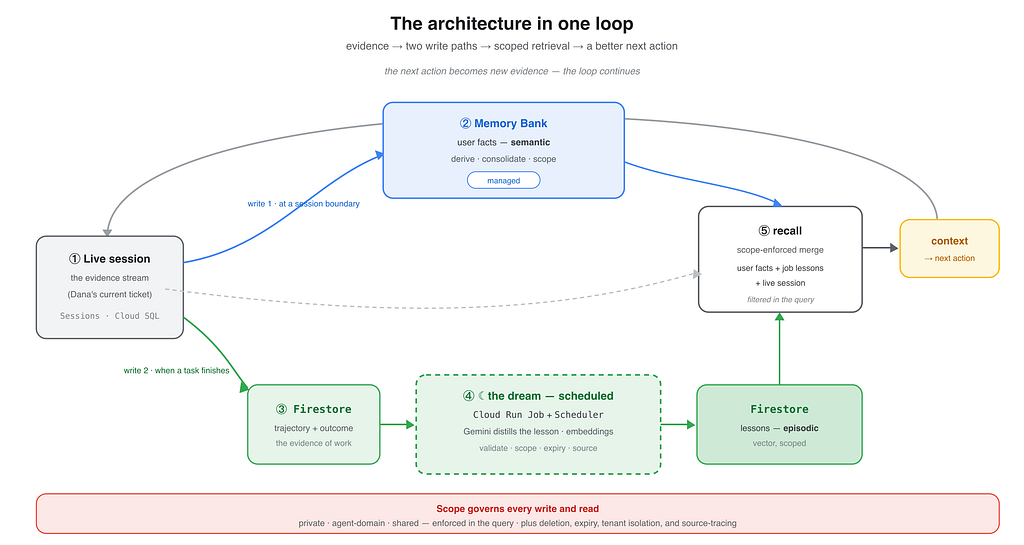
The stack can change, the model can change, and the schedule can change. The durable design is the separation of evidence, derived knowledge, scope, and retrieval.
That is the build-your-own version of agent Dreams: not a hidden product feature, but a harness pattern you can inspect, govern, and verify. The final post turns this architecture into a build and proves that memory actually changes the agent’s next decision.
This is Part 4 of a five-part series on building an AI harness with reflective memory on Google Cloud.
Next: Part 5 — Vibe Code Your Own Agent ‘Dreams’ in Antigravity
Anthropic Just Gave Agents ‘Dreams.’ Here’s How to Build Your Own on Google Cloud was originally published in Google Cloud – Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source Credit: https://medium.com/google-cloud/anthropic-just-gave-agents-dreams-here-s-how-to-build-your-own-on-google-cloud-e509b0e1e6ba?source=rss—-e52cf94d98af—4


")

