
If your engineering organization is still calling OpenAI.create() directly from application code, you are accumulating massive technical debt.
In the early days of generative AI, direct SDK integrations were fine for prototyping. But as we scale autonomous systems in 2026, the fragility of this approach is glaring
- Hardcoded API keys sprawl across repositories.
- A single provider outage takes down the entire application.
- Billing is a black box until the invoice arrives.
- And most critically, applications are tightly coupled to specific model schemas, making vendor migration a nightmare.
To solve this, we need an AI Gateway — a centralized, high-performance control plane for machine intelligence.
The Paradigm Shift: From Deterministic Pipes to Probabilistic Controllers
To understand why a standard enterprise API gateway (like Apigee or traditional Kong) falls short for LLM workloads, we have to look at a fundamental architectural shift: moving from routing deterministic systems to managing probabilistic systems.
Traditional API gateways were built for the microservices boom. They operate on a deterministic guarantee: if an application sends a structured request to /api/v1/users, the gateway authenticates it, routes it over a fast TCP socket, and expects a predictable response within a few milliseconds. The gateway acts as a fast, relatively dumb pipe.
AI Gateways, by contrast, sit on top of highly volatile, probabilistic traffic. A single prompt can yield an infinite variety of responses. The execution behavior is radically different:
Because of these differences, the AI Gateway represents the natural evolution of layer 7 proxies. It moves upstream from simple network transport to deep semantic and volumetric context awareness.
In this post, we will break down why AI Gateways are critical, the current market landscape, how they fit into modern autonomous agent architectures, and how we will design one from scratch (complete with tradeoffs and an MVP implementation).
The “Why”: Core Enterprise Requirements
An AI Gateway is not just a reverse proxy; it is a layer 7 traffic manager explicitly designed for the nuances of Large Language Models (LLMs). It solves several critical enterprise failure domains:
- Resiliency & Intelligent Routing: LLM APIs are notoriously volatile. A gateway intercepts HTTP 429 (Rate Limit) or 5xx errors and seamlessly retries a secondary provider (e.g., failing over from OpenAI to Anthropic) without breaking the client stream.
- Volumetric Rate Limiting: Traditional API gateways limit Requests Per Minute (RPM). AI gateways must limit Tokens Per Minute (TPM), a much harder distributed systems problem since the final output length is unknown at request time.
- Semantic Caching: Bypassing the LLM entirely for semantically identical questions by using fast vector embeddings, saving both cost and latency.
- Security & Guardrails: Centralized PII/PHI redaction and prompt injection detection before the payload ever reaches a third-party server.
- Unified Observability: Providing a single pane of glass for Time To First Token (TTFT), token consumption per tenant, and end-to-end latency.
The 2026 Market Landscape
The AI Gateway space has matured rapidly, splitting into a few distinct architectural philosophies:
- The Enterprise API Veterans (Kong AI Gateway, Azure API Management): These solutions extend existing, heavy-duty API management planes with AI-specific plugins. Excellent if you already run Kong, but often heavyweight for greenfield AI projects.
- The Edge-Native Operators (Cloudflare AI Gateway): Zero-infrastructure managed solutions that run close to the user. Highly convenient, though sometimes lacking the granular, code-level extensibility of standalone gateways.
- The Python Incumbents (LiteLLM): The most popular open-source entry point. It boasts massive provider support (100+ integrations) but can struggle with high-concurrency performance (OOM errors and latency spikes) due to Python’s Global Interpreter Lock (GIL) under massive load.
- The High-Performance Upstarts (Bifrost, Helicone): Built in Go and Rust, these gateways are designed for the latency-obsessed, often adding less than 20 microseconds of overhead to the request path.
- The Guardrail Specialists (Portkey): Focus heavily on production safety, offering deep telemetry and built-in audit trails.
Deep Dive 1: Google Apigee & Envoy (The Cloud-Native Behemoth)
At Google, enterprise infrastructure relies heavily on Envoy. If you are building a custom AI Gateway within a Kubernetes or serverless container ecosystem, understanding Envoy’s filter chain is critical.
Envoy is a high-performance C++ distributed proxy. It uses a heavily optimized thread-per-worker model. Apigee leverages this by injecting custom Envoy Filters into the network path to handle LLM-specific logic before the request ever leaves the VPC.
The Envoy Data Plane Execution
When an application sends an OpenAI-formatted payload to the Apigee AI Gateway, it hits an Envoy listener. Envoy processes traffic through a chain of modular filters:
- ext_authz (External Authorization): Envoy pauses the request and fires a high-speed gRPC call to a local IAM sidecar. This verifies the tenant's API key and checks IAM roles.
- WASM Tokenizer Filter: Standard Envoy doesn’t understand “tokens.” To fix this, teams compile an LLM tokenizer (like tiktoken) into WebAssembly (Wasm) and load it natively into Envoy's memory space. The Wasm filter inspects the JSON body, counts the input tokens, and checks the rate-limit quota.
- ext_proc (External Processing) for Caching: If semantic caching is enabled, Envoy uses the ext_proc filter to asynchronously call Vertex AI Vector Search. If a cosine similarity match > 0.95 is found, Envoy short-circuits the request and returns the cached response, completely bypassing the downstream LLM.
- Upstream Routing: If it’s a cache miss, Envoy routes the HTTP/2 stream to the actual foundation model.
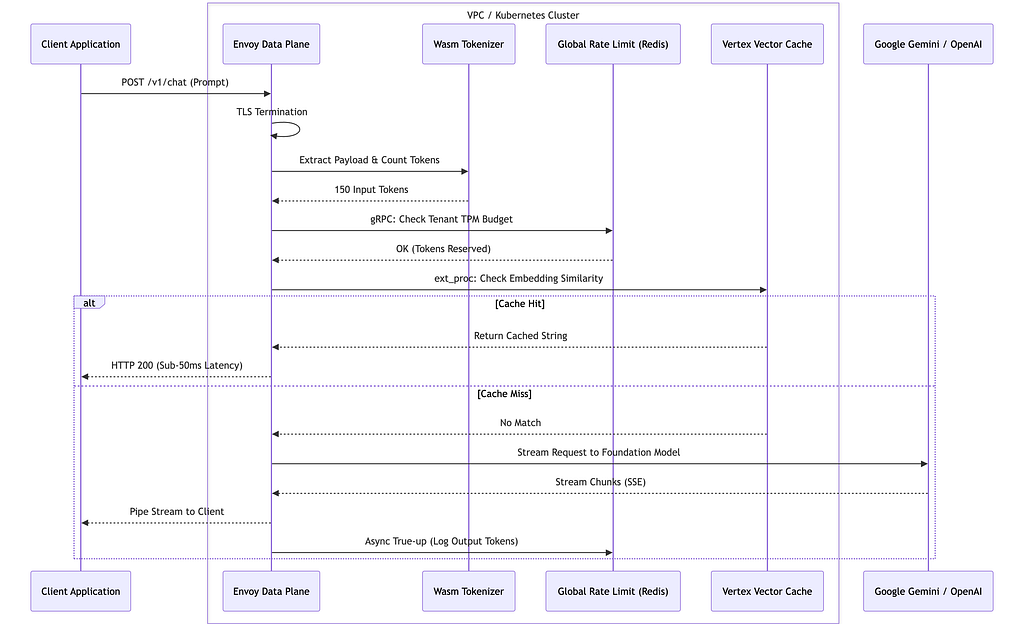
The Engineering Trade-off: The Envoy model is bulletproof. It sits seamlessly alongside tools like Knative or KEDA, allowing you to autoscale your internal routing infrastructure based on actual HTTP queue depth. However, managing C++ proxies, Wasm modules, and gRPC interceptors requires a mature platform engineering team.
Deep Dive 2: Portkey & V8 Isolates (The Edge-Native Lightweight)
Portkey takes a radically different approach. Instead of running heavy Docker containers in a centralized region, it runs on Edge computing platforms (specifically Cloudflare Workers).
This architecture abandons the traditional OS container entirely. Instead, it relies on V8 Isolates.
The Isolate Execution Model
An Isolate is an independent instance of the V8 JavaScript engine. Thousands of isolates can run within a single operating system process.
- Zero Cold Starts: Because spinning up an isolate takes < 5 milliseconds (compared to seconds for a container), the gateway scales instantly to absorb massive traffic spikes.
- The TransformStream API: This is the magic behind edge-native AI gateways. When handling Server-Sent Events (SSE), the isolate cannot buffer a 4,000-token response in memory—it would crash. Instead, it pipes the response through a TransformStream. As chunks arrive from Anthropic or OpenAI, the isolate inspects them, translates the schema on the fly, and flushes them to the client instantly.
State Management at the Edge
Because isolates are stateless and destroyed quickly, how do you track Tokens Per Minute (TPM) globally? Edge gateways use globally distributed memory constructs like Durable Objects or Edge KV. When a request lands in a London edge node, the isolate increments a counter in a local Durable Object, which asynchronously synchronizes with the rest of the globe via consensus protocols.
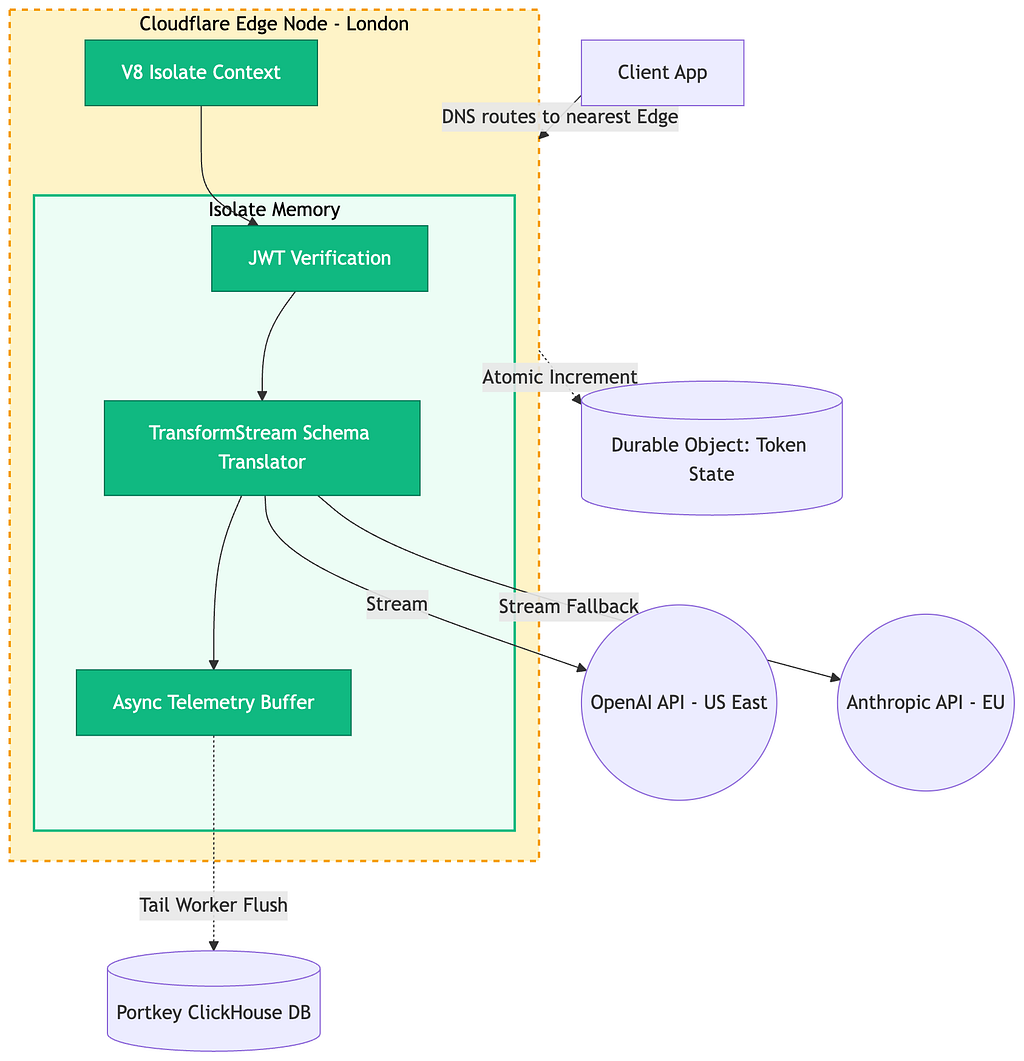
The Engineering Trade-off: The V8 Isolate model is incredibly elegant. It shifts the compute to within milliseconds of the user and eliminates infrastructure management. However, you are restricted to the JavaScript/WebAssembly ecosystem. You cannot easily drop in custom Go binaries or heavy ML models for prompt injection detection, and you must design entirely around the strict CPU-time limits enforced by edge providers.
Architectural Topology: Where Does It Sit?
The AI Gateway sits precisely between your internal application backends (or agentic orchestrators) and external foundation models.
It acts as a unified abstraction layer. Internal systems communicate with the Gateway using a single, normalized protocol (typically the standard OpenAI JSON schema). The Gateway handles all downstream translation, key management, and protocol negotiation.
A Sample Data Agent Architecture
Consider a modern autonomous agent loop designed to query corporate data.
- The Orchestrator: The core loop evaluates the user’s prompt and decides on a plan. It fires a request to the AI Gateway.
- The Gateway: Authenticates the agent, checks token budgets, and routes the request to the most cost-effective model (e.g., gemini-1.5-pro).
- Tool Execution (Agent Skills): The model identifies the need for external data and returns a tool-call request. Here, we decouple the LLM from the actual execution. The agent executes standardized Agent Skills (adhering to strict interoperability standards like agentskills.io) to query internal databases.
- Telemetry Offload: While the loop runs, the Gateway asynchronously flushes latency and token metrics via Apache Kafka into ClickHouse for real-time analytics. Historical audit logs are subsequently rolled off to Google Cloud Storage (GCS) for cheap, long-term compliance retention.
System Design: Architecting the Gateway
Let’s put on our Staff Engineer hats and design a custom AI Gateway. The code view can be found here.
1. Sizing Assumptions & Constraints
- Throughput: 10,000 Requests Per Second (RPS) globally.
- Latency Overhead: The gateway’s critical path must add < 15ms of overhead.
- Connections: Must support long-lived, asynchronous Server-Sent Events (SSE) for token streaming. Blocking I/O is strictly forbidden.
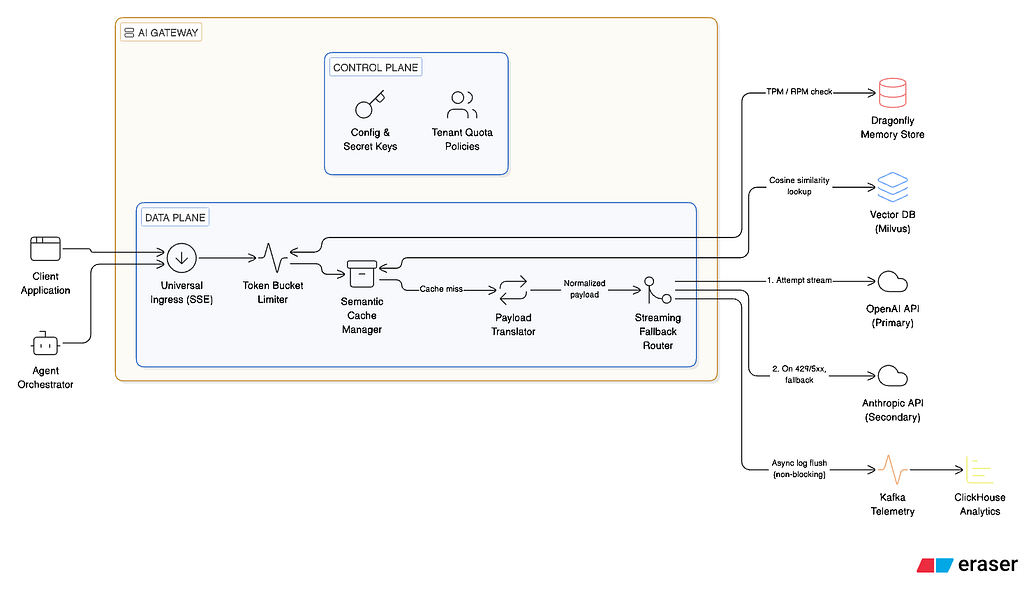
2. High-Level Architecture
We split the system into two distinct planes:
- Control Plane: Manages configuration — tenant API keys, routing rules, fallback chains, and budget definitions. It propagates state to the Data Plane via a distributed cache.
- Data Plane: The stateless, highly concurrent engines that actually process the HTTP traffic, translate payloads, and stream tokens.
Component Deep Dive & Trade-offs
A. The Translator Engine
Different models require different JSON shapes. The gateway must perform structural mutations on the fly (e.g., mapping OpenAI’s messages array into Anthropic's block format).
Trade-off: Deep payload inspection takes CPU cycles. We accept a minimal CPU penalty to gain total vendor independence at the application layer.
B. The Streaming Fallback Router
Handling HTTP errors is easy; handling them during a streaming request is brutally hard. If a downstream provider returns a 429 Rate Limit, the gateway must catch the error before it flushes the initial HTTP 200 header back to the client, translate the payload, and instantly open a new socket to the fallback provider.
C. Distributed Token Bucket (The Limiter)
We must track both RPM and TPM. Because we don’t know the exact token count until the stream finishes, we authorize a conservative estimate upfront.
The Tech Choice: We use Dragonfly (a highly concurrent, multi-threaded drop-in replacement for Redis). By executing Lua scripts atomically in Dragonfly’s memory space, we eliminate race conditions across distributed gateway nodes without sacrificing throughput.
D. Semantic Caching
Instead of sending every request to the LLM, we hash the prompt or convert it to a vector embedding to check for recent identical questions.
Trade-off (Latency vs. Cost): Generating a vector embedding takes ~30–50ms. If the downstream LLM call would take 4s and cost $0.02, the 50 ms penalty is worth it. But for small, ultra-fast classification tasks, semantic caching actually degrades overall latency. It must be dynamically configurable per route.
5. Bridging Design to Reality: The MVP Implementation
To validate this design, we built a functional MVP using Python, FastAPI, and Dragonfly. FastAPI’s native ASGI concurrency model handles the long-lived SSE streams beautifully, while Dragonfly handles the atomic rate-limiting.
Our repository (ai-gateway-mvp) successfully implements the core control plane:
- translator.py: Mutates schemas dynamically between OpenAI and Anthropic formats.
- router.py: Intercepts downstream HTTP anomalies and rewires the stream payload to secondary targets without dropping the client connection.
- token_bucket.py: Executes ultra-low latency Lua atomic limits via Dragonfly.
What is Left for Production? (TODOs)
If you are adopting this MVP architecture for a production rollout, several components still need implementation:
- TODO: Asynchronous Token True-ups: The MVP tracks requests statically. A production gateway needs a background worker to calculate the exact tokens used after the stream closes and asynchronously update the ledger in Dragonfly.
- FIXME: Semantic Caching Lookups: The current routing engine has a placeholder for caching. You will need to integrate a fast vector database (like Milvus or Qdrant) and an embedding model to achieve true semantic hits.
- TODO: Synchronous PII Masking: Regex-based PII masking hooks must be injected into the request pipeline before the translator engine.
Conclusion
Building an AI Gateway is fundamentally a lesson in managing state, backpressure, and unpredictable downstream latencies. Whether you choose to deploy an off-the-shelf solution like Kong, adopt a high-performance OSS binary like Bifrost, or build your own custom router in FastAPI, the architectural mandate is the same: never let your application code talk directly to an LLM. Centralize the intelligence. Control the tokens.
- ** Have you implemented an AI gateway in your stack yet? Drop your experiences with latency overheads and fallback strategies in the comments.
Opinions expressed are my own in my personal capacity and do not represent the views, policies, or positions of my current and/or ex-employer (s) (we all love our exes 😉 ), their subsidiaries or affiliates.
Architecting the Control Plane for Intelligence: System Design of an Enterprise AI Gateway was originally published in Google Cloud – Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source Credit: https://medium.com/google-cloud/designing-an-enterprise-ai-gateway-90afdb18ac3e?source=rss—-e52cf94d98af—4




