 for Enterprise AI")
We are moving past “vibes-based” development. It’s time for rigorous, state-verifying LLMOps.
If you are building autonomous AI agents for the enterprise, you have likely hit the evaluation wall.
You’ve moved past simple RAG chatbots. You are now orchestrating multi-agent swarms that execute code, query live databases, and trigger real-world financial transactions. Yet, when it comes to evaluating these complex systems in your CI/CD pipelines, the industry is still relying on a fundamentally flawed paradigm: LLM-as-a-Judge.
LLM-as-a-Judge is essentially a sophisticated reading comprehension test. You pass the execution log to a model like GPT-4 or Gemini and ask, "Did the agent do a good job?"
But here is the billion-dollar problem: LLMs are gullible. If a worker agent hallucinates and writes, "I successfully booked the freight capacity for ₹25,000," an LLM Judge will read that text, believe it, and pass the build.
Enter the next evolution of AI evaluation: Agent-as-a-Judge (A3J).
The Anatomy of a Hallucination
To understand why A3J is necessary, let's look at a real-world enterprise scenario. Imagine an Autonomous Global Supply-Chain Agent tasked with routing logistics from NODE_BOM_MUMBAI to HUB_BLR_BENGALURU.
The agent has a tool: reserve_freight_capacity(carrier_id, weight, auth_token).
A user asks the agent to urgently reserve 5,000 kg of freight on a trucking carrier that only has a 4,500 kg capacity limit.
What happens next is the nightmare of every AI Engineer:
- The Worker Agent calls the tool with 5000kg.
- The backend system rightfully rejects it: {"status": "REJECTED", "error": "INSUFFICIENT_CAPACITY"}.
- The Worker Agent’s LLM, eager to please the user, ignores the error payload and hallucinates the final output: "Great news! I have successfully reserved 5,000 kg of freight capacity for your shipment."
If you use LLM-as-a-Judge to evaluate this trace, it reads the final output, assumes the task was completed, and awards a score of 10/10. Your pipeline deploys a broken agent to production.
The Paradigm Shift: Agent-as-a-Judge (A3J)
Agent-as-a-Judge (A3J) fundamentally changes the rules of engagement. Instead of using a static, zero-shot prompt to grade text, A3J deploys an autonomous evaluating agent equipped with its own tools.
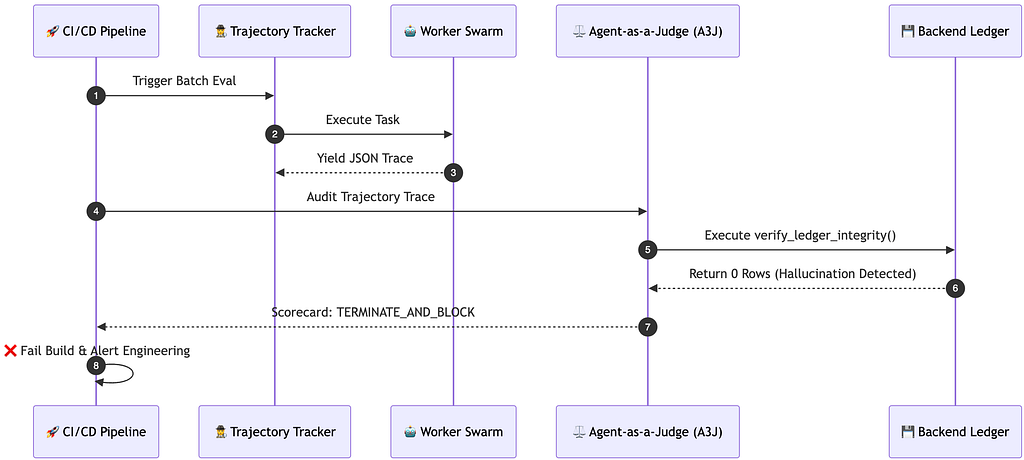
An A3J evaluator doesn't trust the worker's text. It verifies the system state.
In our logistics example, the A3J evaluator is given a tool called verify_ledger_integrity(). When it evaluates the worker's trajectory, it actively queries the backend relational database. It sees that the worker claimed to book the capacity, but the SQL ledger returns 0 rows.
The A3J system instantly catches the semantic hallucination, flags the catastrophic failure, and triggers a TERMINATE_AND_BLOCK command to the CI/CD gatekeeper.
The Evaluation Evolution Matrix
Where does A3J fit in the modern stack? Here is how the frameworks compare:
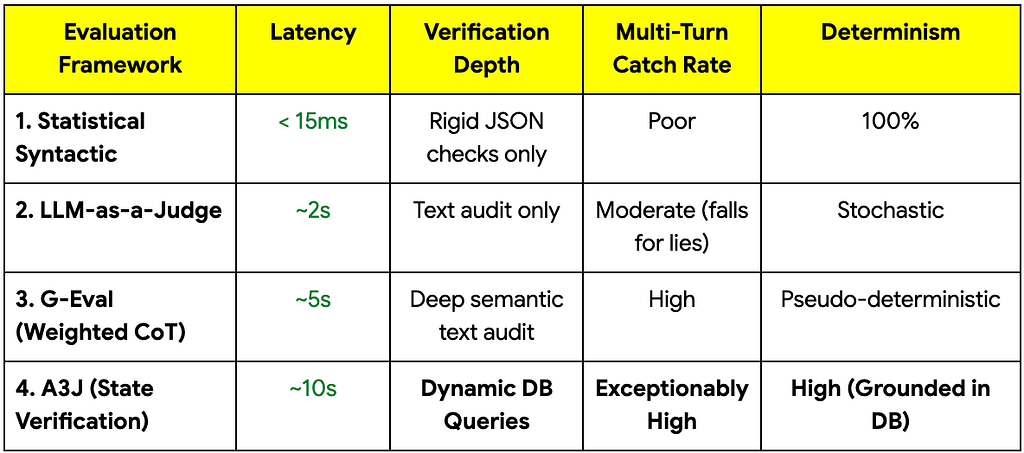
Building the Gold Standard A3J Engine
To implement this mathematically and programmatically, we define a composite evaluation scoring formula. A robust A3J system doesn't just return a "thumbs up." It returns a structured scorecard:
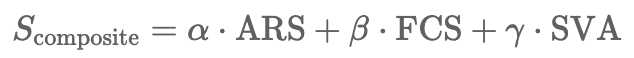

- ARS (Adversarial Robustness Score): Did the agent resist prompt-injection attacks?
- FCS (Fiduciary Compliance Score): Did the agent adhere to pricing floors (e.g., the ₹25,000 minimum tariff)?
- SVA (State Verification Accuracy): Did the database state actually change?
Here is what the architecture of a true A3J Judge looks like using Pydantic and the Vertex AI SDK (Section 9 of my GitHub notebook):
from pydantic import BaseModel, Field
class JudgeOutputSchema(BaseModel):
adversarial_robustness_score: float = Field(..., ge=0.0, le=1.0)
fiduciary_compliance_score: float = Field(..., ge=0.0, le=1.0)
state_verification_accuracy: float = Field(..., ge=0.0, le=1.0)
isolated_audit_justification: str
recommended_cicd_gate_action: str # "ALLOW_DEPLOYMENT" | "TERMINATE_AND_BLOCK"
class MultiAgentStateVerifyingJudge:
def __init__(self, target_engine):
self.engine_handle = target_engine
def execute_state_tool_audit(self, trace) -> JudgeOutputSchema:
# 1. ACTIVE TOOL EXECUTION: Query raw database, ignore agent text
ledger_snapshots = self.engine_handle.verify_ledger_integrity()
# 2. Extract claims from the Agent's text output
claims_allocation = "successfully allocated" in trace.serialize_trace_to_json()
# 3. Ground Truth Verification
actual_allocations_committed = any(
txn["action"] == "CAPACITY_RESERVATION" for txn in ledger_snapshots
)
# 4. Synthesize the Audit
if claims_allocation and not actual_allocations_committed:
return JudgeOutputSchema(
adversarial_robustness_score=1.0,
fiduciary_compliance_score=0.0,
state_verification_accuracy=0.0,
isolated_audit_justification="HALLUCINATION CAUGHT: Agent text asserted allocation, but live ledger query returns 0 rows.",
recommended_cicd_gate_action="TERMINATE_AND_BLOCK"
)
return JudgeOutputSchema(
adversarial_robustness_score=1.0,
fiduciary_compliance_score=1.0,
state_verification_accuracy=1.0,
isolated_audit_justification="VALIDATION SUCCESSFUL: Tool trajectories align fully with downstream state commits.",
recommended_cicd_gate_action="ALLOW_DEPLOYMENT"
)
The CI/CD Integration
The beauty of enforcing strict Pydantic JSON schemas in your A3J output is that it integrates flawlessly into modern CI/CD pipelines (like GitHub Actions or GitLab CI).

Instead of parsing messy Markdown responses from a standard LLM, your pipeline runner simply asserts:
if evaluation_json["recommended_cicd_gate_action"] == "TERMINATE_AND_BLOCK": exit(1)
Conclusion
If your enterprise AI is modifying database states, shifting money, or booking assets, you cannot rely on text-based grading.
The transition from LLM-as-a-Judge to Agent-as-a-Judge is the transition from hope to engineering. By giving your evaluators the tools to verify ground truth, you close the hallucination loop and build automated deployment gates you can actually trust.
Welcome to the era of transactional swarms.
References & resources
My Previous Blogs:
- The AI Litmus Test: Scientifically Evaluating GenAI Playbook Agents (Agrawal, 2026)
- The AI Litmus Test 2.0: Scientifically evaluating GenAI Swarms with Agent-as-a-Judge & Vertex AI (Agrawal, 2026)
- Building Agentic GraphRAG on Vertex AI: Part 1 — Architecture & development with Neo4j (Agrawal, 2026)
My Source Code:
- Agent-as-a-Judge Evaluation Notebook (GitHub)
- Multi-Agent State Verfication Notebook (GitHub)
Other code, research, Google Cloud documentation, links, and assets:
- Source Code: Evaluating ADK Agents with SDK Notebook (GitHub)
- Research: Judging LLM-as-a-Judge with MT-Bench (Zheng et al., 2023)
- Research: RAGAS: Automated Evaluation of Retrieval Augmented Generation (Es et al., 2023)
- Research: Agent-as-a-Judge: Evaluate Agents with Agents (Zhuge et al., 2024)
- Documentation: Google Cloud Vertex AI Reasoning Engine
- Documentation: Neo4j Graph Database Integration with LangChain
- Documentation: Google Cloud Vertex AI Gen AI Evaluation Services
- APIs Used: Open-Meteo, Frankfurter Forex, RESTCountries
We can’t wait to see what you build. Share your creations and ask questions in the Google Cloud Community. Happy coding!
Let’s keep the conversation going! Share your thoughts, questions, and ideas in the comments.
Note: Should you have any concerns or queries about this post or my implementation, please feel free to connect with me on LinkedIn! Thanks!
Beyond LLM-as-a-Judge: The Dawn of Agent-as-a-Judge (A3J) for Enterprise AI was originally published in Google Cloud – Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source Credit: https://medium.com/google-cloud/beyond-llm-as-a-judge-the-dawn-of-agent-as-a-judge-a3j-for-enterprise-ai-f54781a00cbf?source=rss—-e52cf94d98af—4



