
This is Part 5, the hands-on finale of a five-part series on building an AI agent with reflective memory on Google Cloud.
Parts 1–4 covered the idea, the Google Cloud building blocks, the agent / harness boundary, and the two-write-paths architecture.
Now we are going to build the loop in Google Antigravity 2.0. The agent is a simple customer-support agent: it looks up orders, checks return / warranty / damage policies, and opens cases. It will remember customer facts across sessions, then learn a better hxandling procedure from a completed ticket.
Then we will run it and check the part that matters: whether the memory changes what the agent does next, not just what it can repeat.
Two ways to follow along
You can follow this post in two ways:
- Build it yourself in Antigravity 2.0. Install the skill, give Antigravity one prompt, review its plan, and let it build the loop.
- Clone the finished repo and run the proofs. If you would rather read working code and reproduce the numbers first, skip to Run it yourself. Clone the repo, set up GCP, and run three scripts.
Both paths use the same architecture and the same checks. If you want the fastest verification, start with the repo. If you want to see how the build is guided, start with Antigravity.
The architecture
Part 4 has the full diagram. For this build, you only need the shape of the loop:
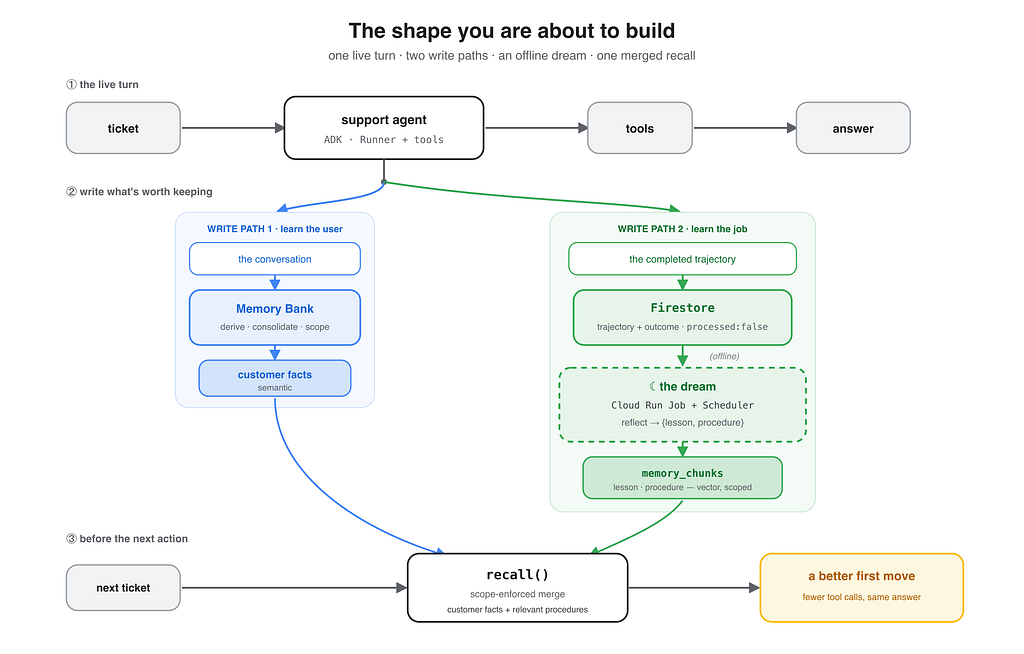
Two things write memory. One path writes user-facing memory online, and the other writes completed task trajectories for offline reflection. One thing reads memory: recall, before the agent acts. That simple shape is what keeps the system understandable when the cloud services start multiplying.
Install the skills
This build starts with a skill called reflective-memory-harness. A skill is just a folder with a SKILL.md, reference files, and rules the coding agent loads when the task matches. Here, the skill keeps the architecture and guardrails close to the implementation, so Antigravity can use them while planning and coding.
In Antigravity, you do not need to wire these skills into the agent code yourself. Ask the AI to install them for the workspace by typing the prompt below:
Please install these skills for this workspace by cloning them into `.agent/skills/`:
- https://github.com/google/skills
- https://github.com/google-gemini/gemini-skills
- https://github.com/cuppibla/reflective-memory-skill
Antigravity will run the clone commands; you just review and approve them. After that, the workspace has two layers of guidance. Google’s official skills cover the platform details: Cloud Run, Firestore, the Gemini APIs. The reflective-memory skill covers the design rules.
Before giving Antigravity the build prompt, it is worth knowing what that skill is going to enforce. You do not need to paste these rules anywhere; they are already part of the installed skill.
- Reflect into Memory Bank synchronously for short-lived runs, instead of starting a fire-and-forget write that may exit before the write lands.
- Use an embedding dimension compatible with Firestore vector indexes.
- Trigger Cloud Run Jobs from Cloud Scheduler with OAuth for Google API targets.
- Record an outcome and, when known, a resolution or root cause for every trajectory.
- Give every derived lesson a scope and a source trajectory.
- Use durable sessions and least-privilege service accounts for production paths.
These are the guardrails that keep the build from looking correct while the learning loop is quietly broken. Part 4 explains the details; here, the skill makes those decisions available to the builder as it works.
Give Antigravity the job, then read the plan
The prompt can stay short:
Build me a reflective-memory customer-support agent on Google Cloud using Python, ADK, and gemini-2.5-flash. It resolves order tickets with tools: look up an order, check the return / warranty / damage policies, and open a case. It should remember customers across sessions with Memory Bank, and learn better-handling procedures from its own past tickets with a Firestore dream job. Include demos that prove both paths, and for the job path, measure the agent's tool-call trajectory, not just whether the final answer is right.
A support agent is just the running example. The same skill works for any agent that talks to users and completes multi-step tasks: a coding agent that learns a repo’s migration procedure, a research assistant that learns which sources to check first, or a data agent that learns the validation step everyone forgets. Swap the domain in that one sentence and the architecture, guardrails, and proof shape stay the same.
One line in that prompt matters more than it looks: “make the agent multi-tool, and measure the trajectory.” A single-shot Q&A agent has no path to optimize; it answers in one step. The job half of reflective memory earns its keep when the agent takes a sequence of actions, because then a distilled procedure can teach a better sequence.
Before Antigravity writes code, it lays out a plan. Read that plan like a PR. In particular, check these five things:
- Does every trajectory record the tool-call sequence, not just the final answer?
- Does each trajectory carry an outcome and a root cause?
- Does the dream produce a scoped {lesson, procedure} and write it back to Firestore?
- Does recall merge Memory Bank facts and Firestore procedures before the agent acts?
- Does the eval measure path length, not only final correctness?
If the plan uses an in-memory production path, skips the root cause, enforces scope only after retrieval, or measures only correctness, ask it to revise the plan before approving. It is much cheaper to fix the shape of the build before code is generated.
Run it yourself (copy-paste)
This is the reproducible core. The finished build is in the demo repo, so you can clone it, point it at your GCP project, and run the three proofs yourself.
Setup (once)
git clone https://github.com/cuppibla/reflective-memory-demo
cd reflective-memory-demo
python3.11 -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
cp .env.example .env # then edit: GOOGLE_CLOUD_PROJECT, region, etc.
set -a; source .env; set +a
# one-time: create the Memory Bank backend, then export the id it prints
python learn-the-user/create_engine.py
export AGENT_ENGINE_ID=... # the id from the line above
You need a GCP project with the Vertex AI API and a Firestore database in Native mode, plus a vector index on memory_chunks.embedding. You also need Python 3.11 and ADC auth with gcloud auth application-default login. You do not need JSON key files.
Proof 1: a new session remembers the customer
python learn-the-user/run_demo.py
The first session gives the agent durable facts about a customer. A separate session then asks a question that needs those facts, without repeating them:
Session 1: "Hi, this is Dana, IT admin at ACME. We're on the Enterprise plan,
and we prefer email for non-urgent updates."
-> reflected into Memory Bank (synchronously)
Session 2: "One of our orders arrived damaged — what are our options?"
-> reply greets Dana, respects the Enterprise relationship, offers email
This proves personalization carries across sessions. It also catches a failure that quietly breaks short demos: a fire-and-forget memory write can return before it lands, which means session 2 starts blank. The skill forces a synchronous write, so the second session can actually use what the first session taught it.
But remembering a user is only the easy half. The more interesting question is whether the agent gets better at the job.
Proof 2: the dream changes the path, not the answer
This proof isolates job memory. The agent’s instruction contains zero domain knowledge about damaged items. It is told only to call recall first, then follow a procedure if one comes back. Any better routing must come from retrieved memory, not from the prompt.
python learn-the-job/demo_trajectory.py
The script seeds one past damaged-item ticket with its root cause, runs the dream to distill a procedure, then runs the same five tickets twice: once without consulting job memory, and once with it. It counts tool calls in both conditions. The distilled procedure looks like this:
When a customer reports a damaged, broken, defective, or cracked item, apply the
damage-exception policy FIRST — bypass the standard-return window and warranty check.
The per-ticket output makes the difference visible:
broken_headphones OFF 3 steps · lookup_order -> warranty_policy -> ... -> create_case
ON 2 steps · damage_exception_policy -> create_case
defective_charger OFF 3 steps · lookup_order -> warranty_policy -> standard_return_policy
ON 2 steps · damage_exception_policy -> create_case
wrong_size_shirt OFF 3 steps · lookup_order -> standard_return_policy -> create_case (control)
ON 3 steps · lookup_order -> standard_return_policy -> create_case (unchanged)
--- RESULT --- avg tool calls: OFF ~2.8 -> ON ~2.4 · wrong route 0/5 -> 0/5 (one run — noisy)
One run is intentionally not the whole story. With a capable model, the gain bounces from run to run, so the repo includes a 20-sample benchmark:
python learn-the-job/bench_trajectory.py
It runs the same A/B four times and prints the aggregate. A representative run:

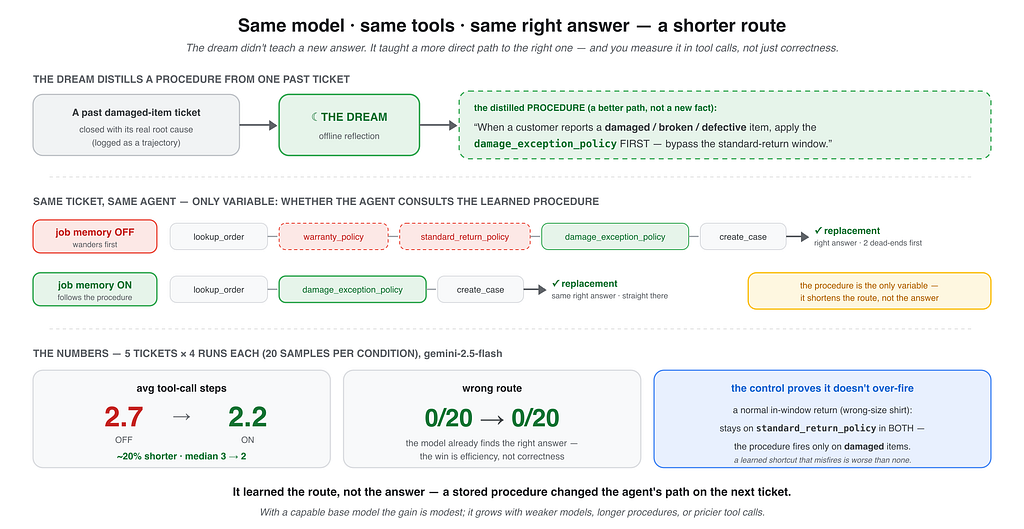
Both columns are correct: 0 wrong out of 20, either way. gemini-2.5-flash is strong enough to reach the exception policy without help. What the learned procedure changes is the route: about 20% fewer tool calls, with a stable median of 3 -> 2. The mean is noisy run to run, roughly 15-26% across benchmark runs, which is why the script prints the exact aggregate for your run. The median holds.
That is the key distinction: not wrong -> right, but wandering -> direct. The procedure is the only variable, and the behavior change is visible in the path:
experience -> recorded outcome + root cause -> distilled procedure
-> scoped retrieval -> shorter trajectory -> same correct result
This also shows why root cause matters. If the trajectory only recorded that “the answer was generic,” the dream would distill generic advice. The useful learning signal is the resolved cause of the detour. Garbage outcome, garbage lesson.
This also shows why root cause matters. If the trajectory only recorded that “the answer was generic,” the dream would distill generic advice. The useful learning signal is the resolved cause of the detour. Garbage outcome, garbage lesson.
Why use gemini-2.5-flash? The point of this benchmark is not to compare models. Every OFF/ON run uses the same model, with no fine-tuning, so the retrieved procedure is the only thing that changes. I kept gemini-2.5-flash because these were the original runs, and because it is a useful baseline for this demo: capable enough to get the answer right, but not so optimized that the memory effect disappears into a perfect first move. That is why the improvement is visible but still modest. You should expect a bigger gap when the default route is worse: a weaker model, a longer policy, a less obvious exception, or tools with real latency and cost.
Proof 3: a second agent inherits the procedure
This is the Part 3 boundary made real. If memory lives in the harness, not in one agent’s prompt, another agent should be able to inherit a shared procedure without copying code from the first agent.
python learn-the-job/demo_trajectory_inherit.py
A different agent, chat_support, has never seen the original ticket. Because the procedure was approved as harness_shared, it retrieves it on first contact:
chat_support -> recall -> shared procedure -> damage_exception_policy -> create_case (2 steps)
SHARE (a new agent inherits the procedure & routes by it): PASS
support_agent sees its PRIVATE lesson : True (the owner can use it)
chat_support sees the PRIVATE lesson : False (scope blocks it — no leak)
ISOLATE (private stays invisible to the other agent): PASS
The new agent inherited the route with zero memory code of its own. The private lesson was seeded on the same topic, so nearest-neighbor search would have surfaced it if scope were loose. It stays walled off because scope is enforced before the model sees retrieved memory. Sharing without isolation is a leak, not a feature; this checks both halves.
Why it works
Strip away the services and the loop is simple. It is the same thread from Part 1: persistence is not memory. Storing the transcript of the first ticket would not have changed the next run. What changed behavior was reflection: the system looked at the completed trajectory, distilled a reusable procedure, and retrieved that procedure before the next decision.
Two ideas are worth keeping.
First, measure the trajectory, not only the answer. A pure correctness A/B here would read “pass vs pass” and conclude nothing happened. The agent was improving the whole time, but you only see it if you measure path length. For tool-using agents, the path is part of the behavior.
Second, the size of the win tracks the gap between the model’s default path and the optimal procedure. A strong model on an easy task leaves a small gap, so the gain is modest. The gain gets larger when the base model is weaker, the procedure is longer or more counter-intuitive, or tool calls cost real money and latency. Reflective memory is not free improvement sprinkled on top. It closes a specific behavioral gap.
That is also why the pattern generalizes. A research agent can learn which sources to check first. A data agent can learn which validation catches bad rows. A coding agent can learn a repo’s migration traps. Same loop, different domain.
Ship the dream as its own workload
In the demos, the dream runs in-process so you can watch it. In production, it should be batch work. Deploy it as a Cloud Run Job and trigger it with Cloud Scheduler:
gcloud run jobs deploy dream-job --source . --region us-central1 \
--service-account dream-sa@$GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.com
gcloud scheduler jobs create http dream-nightly \
--location us-central1 --schedule "0 3 * * *" \
--uri "https://us-central1-run.googleapis.com/apis/run.googleapis.com/v1/namespaces/$GOOGLE_CLOUD_PROJECT/jobs/dream-job:run" \
--http-method POST \
--oauth-service-account-email dream-sa@$GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.com
Keep the identities separate. The Scheduler identity invokes the job; the Cloud Run runtime identity gets only the Firestore and Vertex AI permissions the reflection code needs. Also note –oauth-service-account-email, not –oidc-*. The target is a Google API, and –oidc can look plausible while the scheduled call never actually fires.
Recap
Five parts, one idea. Part 1 said memory is what the agent learned, not what it stored. Part 2 named the Google Cloud tools that make that real. Part 3 put the memory in the harness, not the prompt. Part 4 drew the two-write-paths-one-read architecture. And Part 5 built it in Antigravity and measured the result.
Persistence is not memory. The value is the loop, and you measure the loop by what the agent does next, not just what it stores.
This was Part 5, the finale of a five-part series on building an AI agent with reflective memory on Google Cloud. The skill and runnable demo are open. Clone them and make the loop your own.
Build Your Own Reflective-Memory Agent in Google Antigravity was originally published in Google Cloud – Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source Credit: https://medium.com/google-cloud/build-your-own-reflective-memory-agent-in-google-antigravity-566bb16c56b4?source=rss—-e52cf94d98af—4




