
The landscape of software engineering is undergoing a massive shift. We are moving away from rigid pipelines and into the era of autonomous systems. In this deep dive, we will explore the paradigm shift from traditional automation to AI agency, unpack the anatomy of an agent, and examine how cloud-native technologies provide the perfect serverless runtime for these state-heavy, probabilistic workloads.
Automation vs. Agency: A Paradigm Shift
To understand the infrastructure needed for agents, we first need to define how they differ from the systems we build today.
Automation is fundamentally deterministic.
- It executes strictly defined step-by-step instructions (If X, then Y).
- Consequently, it is fragile and fails predictably, requiring developers to write extensive exception handlers.
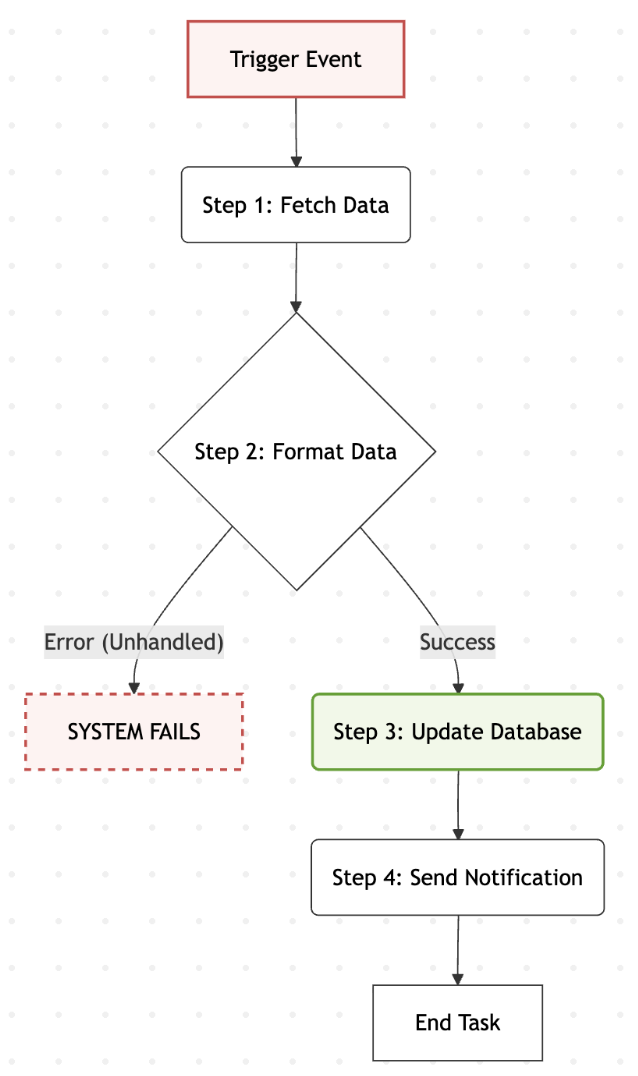
Agency, on the other hand, is non-linear and probabilistic.
- An agent navigates its environment dynamically, as it self-corrects and iterates to reach a goal.
Here is a breakdown of the physiological differences between these two approaches:

The Anatomy and Physiology of an Agent
What exactly makes up the anatomy of an AI agent? Every agent framework generally relies on four core concepts:

- The Brain (LLM): The reasoning core.
- The Nervous System (Orchestrator): The agent orchestrator frameworks (e.g., Google ADK, LangGraph, n8n, Dify).
- The Hands (Tools/Skills): This is where the agent interacts with the real world, such as through MCP, browser automation, or code execution.
- The Memory: Frameworks maintain a “state object” utilizing vector stores or embedded databases.
The physiological “heartbeat” of an agent is the ReAct loop where it will reason, act, and observe.
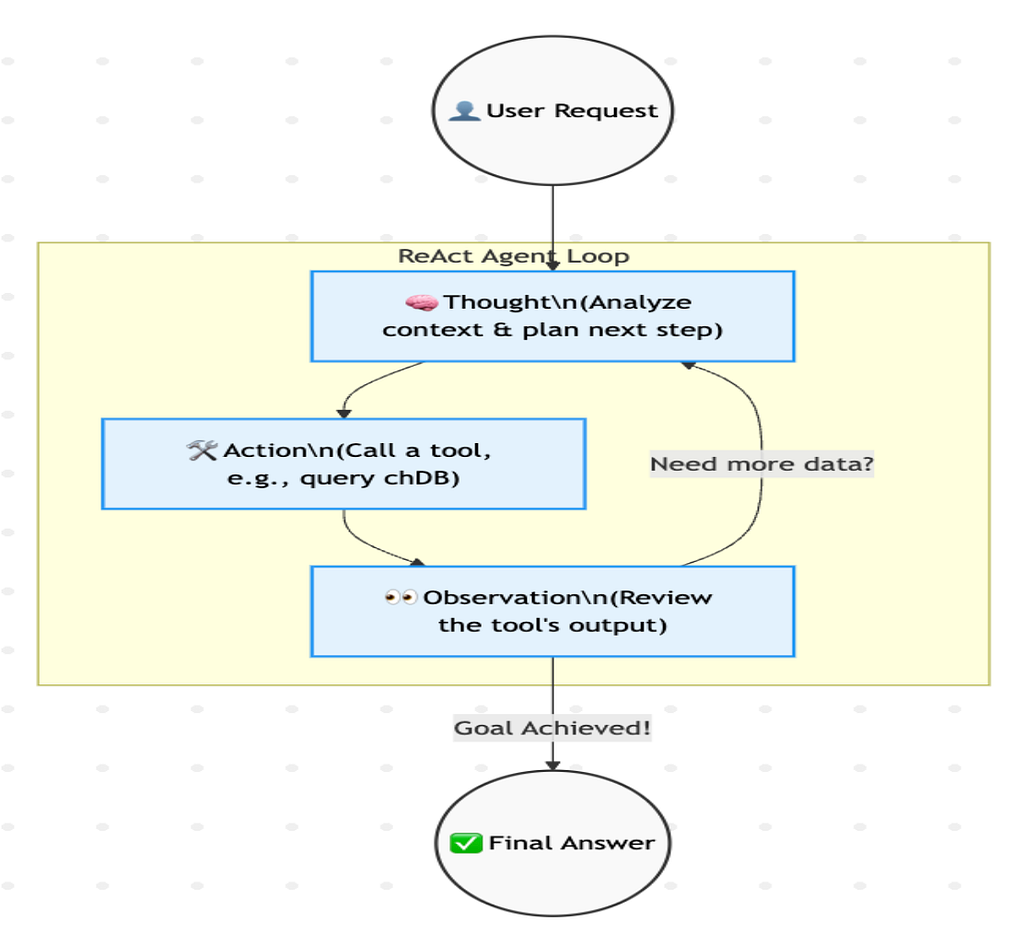
Why Move Beyond RAG?
You might be wondering why we need agents. The reality is that static RAG has its own set of limitation. While it is excellent for retrieving data and using them to analyze/display trends, it lacks the ability to execute actions based on them. For eg. we can find out what the sales figure of a particular component in a given time of the year, but we cannot figure out why it was low or high, or are there any geo-political factors affecting it.
Agents introduce dynamic reasoning, much similar to humans involving multi-step execution, feedback and self-correction.
The Infrastructure Challenge
Running these agents introduces severe infrastructure challenges. AI workloads are characterized by bursty traffic and state dependency. Agents frequently enter the “waiting pattern” or a sync wait, and they require expensive “warm” loading.
While Kubernetes is the industry-standard platform for service based deployments, it falls short here.
Standard Kubernetes is fundamentally declarative but static. You deploy a pod, it consumes resources, and it sits there waiting for traffic. It doesn’t natively understand HTTP request concurrency , nor can it gracefully scale down to zero when idle. For state-heavy, bursty AI agent workloads, this leads to unacceptable resource waste and scaling bottlenecks.
Deep Dive: The Knative Architecture Under the Hood
Enter Knative — a platform purposefully built for managing modern, request-driven serverless workloads on top of Kubernetes. To truly architect autonomous systems, we must understand its two primary control planes: Serving and Eventing.

Knative Serving: The Request-Driven Engine
Knative Serving abstracts away the complex boilerplate of Kubernetes Deployments, Services, and Ingresses, replacing them with four core Custom Resource Definitions (CRDs):
- Service: The top-level overarching resource. It automatically manages the lifecycle of the other three CRDs.
- Configuration: Maintains the desired state of your deployment. Every time you update the configuration (e.g., pushing a new version of your agent), it creates a new, immutable…
- Revision: A point-in-time snapshot of your code and configuration. This immutability is crucial for safe rollbacks and traffic splitting (e.g., routing 10% of traffic to a new experimental agent).
- Route: Maps a network endpoint to one or more Revisions. It manages the ingress rules and traffic splitting logic.
The Magic of Zero Traffic Loss (with Scale-to-Zero)
From an infrastructure perspective, scaling to zero is easy; waking back up without dropping client requests is the hard part. Knative solves this elegantly through the interplay of the Activator and the Autoscaler (KPA — Knative Pod Autoscaler).
Here is the exact data path when your agent is scaled to zero (no pods running):
- The Interception: An incoming HTTP request hits the Ingress gateway (like Istio or Envoy). Because there are no pods, the Route directs this traffic to the Activator component.
- The Buffer & Signal: The Activator holds the HTTP request in a memory buffer. Simultaneously, it pings the KPA to spin up a new agent pod.
- The Proxy: Once the pod is healthy and ready to serve traffic, the Activator proxies the buffered request to the pod. The client never sees a dropped packet, only a slight latency spike for the cold start.
- Stepping Out of the Data Path: Once the system is warm (Pods > 0), the Route is dynamically updated. The Activator steps entirely out of the data path, and traffic flows directly from the Ingress to the agent pods to ensure minimal latency.
Unlike standard Kubernetes, which scales based on CPU or Memory usage (via the HPA), the KPA scales based on Concurrency. It counts the exact number of requests hitting your pods. Because AI agents often enter a “waiting pattern” (synchronous wait) while calling external LLMs or APIs, CPU scaling is useless. Concurrency-based scaling ensures your system scales exactly according to the active workload. Furthermore, Knative accommodates the long reasoning loops of agents by supporting extended execution timeouts (up to 60 minutes).
Knative Eventing: The Asynchronous Nervous System
While Serving handles synchronous HTTP traffic, agents often need to operate asynchronously (e.g., reacting to a database change, a slack message, or a scheduled security scan). This is where Knative Eventing comes in.
Knative Eventing is built entirely around the CNCF CloudEvents specification, providing a standardized wrapper for all incoming signals. The architecture revolves around four primitives:
- Source: The origin of the event (e.g., a Kafka stream, a firewall alert, or a webhook).
- Broker: The central event mesh. It acts as an HTTP endpoint that receives events and reliably routes them.
- Trigger: A routing rule. It funnels specific events from the Broker based on CloudEvent attributes (like event type or source).
- Sink: The ultimate destination of the event , which is typically your Knative Serving agent pod.
Because the Sink is usually a Knative Service, this entire asynchronous pipeline inherits the scale-to-zero capabilities. If no events are firing, your background agent workers consume zero compute. When a burst of events hits the Broker, the Triggers forward them as HTTP POST requests to your Service, seamlessly waking up the Activator and KPA to process the queue. Note that scale-to-zero implementation can depend heavily on the specific protocol and tooling used in the eventing chain
Why Knative Wins for Agents
1. Concurrency is King
Unlike standard Kubernetes, which traditionally scales based on CPU or memory usage, Knative scales based on concurrency. Because an agent spends so much time waiting for third-party outputs (meaning its CPU usage is low but the request is still active), scaling on CPU leads to bottlenecks. Knative natively allows and monitors multiple concurrent requests per container, scaling up precisely when the active request volume demands it.
2. True Scale-to-Zero (Without Traffic Loss)
Agents shouldn’t cost money when they aren’t reasoning. Knative allows your infrastructure to scale down entirely, meaning when no agents are running, there are zero compute costs.
However, waking up from zero usually causes dropped requests. Knative solves this elegantly :
- When pods are at zero, an incoming request is routed to the Knative Activator.
- The Activator acts as a memory buffer, holding the HTTP request while simultaneously pinging the Autoscaler (KPA) to spin up a new pod.
- Once the agent pod is ready, the Activator proxies the buffered request directly to it.
- The client never sees a dropped packet, ensuring seamless interactions even after periods of total inactivity.
3. Extended Execution Windows
Agentic workflows (like the ReAct loop) are non-linear and probabilistic, meaning they often require multiple iterations to achieve a goal. This takes time. Knative accommodates these long-running reasoning loops by supporting extended execution windows with up to 60-minute request timeouts.
4. Seamless Asynchronous Eventing
Agents don’t just respond to synchronous UI prompts; they must react to background alerts and triggers (like a message queue or a security event). Knative Eventing uses a standard CloudEvents mesh (Broker and Triggers) to capture these asynchronous signals and translate them into HTTP POST requests. This means your async background agents inherit the exact same scale-to-zero and concurrency benefits as your synchronous web-facing agents.
Securing the Agentic Enterprise: The MCP Sidecar Pattern
The fundamental risk of deploying autonomous systems is the non-deterministic nature of the LLM itself. Giving an agent the “keys” to directly execute enterprise APIs introduces an unacceptable vulnerability. If an agent falls victim to prompt injection or simply hallucinates a destructive command, the blast radius must be contained.
To secure the agentic enterprise, we must abandon monolithic agent designs and adopt a strict decoupled tool execution pattern. In a cloud-native architecture, this is achieved by pairing Knative’s granular scaling with the Model Context Protocol (MCP).
Decoupling the Brain from the Hands
Instead of baking API credentials and execution logic directly into the agent’s reasoning core, we split the architecture within the Knative Pod:
- The Reasoning Container: This is the agent’s brain (the LLM client, orchestration framework, and state store connection like chDB or ClickHouse). It decides what action to take, but it possesses zero credentials to interact with the outside world.
- The MCP Security Sidecar: Deployed as a sidecar container within the exact same Knative Service, this acts as the agent’s “hands”. It is a dedicated MCP server that actually holds the execution logic and the keys to the External Enterprise APIs.
When the agent decides to query a customer database or trigger a build pipeline, it cannot do so directly. It must formulate a standardized request via MCP over localhost to the sidecar. The sidecar then enforces input validation, schema checking, and strict RBAC before securely making the API call.
Defense in Depth on Knative
This sidecar pattern perfectly complements Knative’s infrastructure capabilities:
- Granular Service Identity: Every agent deployed on Knative is assigned a dedicated, tightly scoped Service Account. The cloud-native environment can be configured so that only the MCP sidecar’s specific service identity has the IAM permissions to execute the downstream APIs, rendering the reasoning container functionally impotent on its own.
- Network Isolation: By locking down the entire Knative environment using VPC Service Controls, we prevent unauthorized egress. If the reasoning core attempts to exfiltrate data to an unauthorized endpoint, the VPC perimeter blocks it.
- Synchronized Lifecycle: Because the MCP server runs as a sidecar within the Knative Revision, it inherits the abracadabra scale-to-zero capabilities. When the Activator wakes the pod up, the sidecar spins up alongside the reasoning core. There is no need to manage a separate fleet of tool-execution servers.
By isolating the execution environment through standard protocols like MCP, we protect the enterprise from the unpredictability of generative models while maintaining the agility and cost-efficiency of a true serverless architecture.
Conclusion: Tying It All Together
We are rapidly moving past the era of fragile, deterministic pipelines. By tying together advanced serverless control planes with robust protocol standards, we can finally build autonomous systems that belong in the enterprise.
This architecture proves that we do not have to compromise. We can achieve the “Scale-to-Zero” async trigger for cost efficiency, leverage the concurrency sweet spot to handle bursty AI workloads without dropping packets, maintain stateful memory in a stateless pod for deep reasoning, and enforce a hardened security boundary using MCP sidecars.
As we continue to push the boundaries of agentic design, the focus must remain on these foundational infrastructure patterns. The future is autonomous, but it is built on reliable, cloud-native engineering.
To see this architecture in action, check out the demo architecting a Cloud-Native Security Agent Swarm from my session at CloudxAI on March14, 2026 , 1130 Hrs onwards!
Opinions expressed are my own in my personal capacities and do not represent the views, policies or positions of my current / ex , or any employers ,or their subsidiaries or affiliates
Architecting Autonomous Systems in Cloud-Native Environments was originally published in Google Cloud – Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source Credit: https://medium.com/google-cloud/architecting-autonomous-systems-in-knative-9e2e29ca4741?source=rss—-e52cf94d98af—4

")


