
Stop calling it autonomous. Start calling it unaccountable. An informed consent for the 2am incident that may save or cripple your mission critical database isn’t a feature. It’s a necessity.
The dominant narrative in AIOps and AI SRE nowadays seems to go alone the lines of “fully autonomous = more advanced.” Everyone is racing toward “the AI that just magically fixes everything for you.”
I have a somewhat counter-argument and it isn’t anti-AI. Instead, it’s about a higher standard. My argument is simple: an autonomy without consent isn’t progress. It’s liability without accountability.
A surgeon who operates without explaining the procedure isn’t more efficient. They’re unethical. My observation is that some AI vendors are building exactly that for your production infrastructure. And calling it a feature.
Easy doesn’t mean Right
A surgeon walks in. No introduction. Doesn’t explain what’s wrong or what they’re about to do. Just starts operating. You find out when you wake up. If you wake up.
That’s an absurd scenario in medicine. But it seems like an apropos metaphor, because looking at the trend in AI vendor offerings, that feels like where AI SRE is heading.
Many “autonomous” AI SRE tools today that go beyond just advising and offer an execution arm as well, work exactly like this: detect a problem, decide on a fix and apply it. A customer only finds out in the postmortem… if there’s one. And we’re told that this is not a bug. It’s a feature. Because humans are slow and indecisive, while AI only gets better and smarter and so the goal is effectively to remove humans from the loop and get faster resolutions. But speed without accountability isn’t reliability. It’s just faster failure.
And, yes, if you are lucky, your AI SRE buddy may actually have solved the original 2am incident, only to introduce more problems down the road that remain hidden until they turn into a barrage of the other 2am incidents. That’s not progress. That’s how your operational awareness of what’s going on in your production databases erodes until it completely spirals out of control.
That’s not the path.
Informed Consent
Medicine defined this carefully for a reason. Informed consent has three parts:
- Informed, as in: you understand the diagnosis, the proposed treatment and the confidence level behind both
- Consent, as in: you consciously agree before anything happens
- The right to refuse, as in: you can say “no” and that “no” is recorded
That record matters. Not just for the patient’s protection, but also for the doctor’s accountability too. If something goes wrong, there is a formal, documented moment where a human with full information made a decision. That’s not bureaucracy. That’s the architecture of trust.
As an aside: I first heard of informed consent applied to a database space from the seminal work of Cary Millsap where he used it in the context of Oracle performance and it resonated strongly with me because that’s exactly how I believe customer service should be approached in general and in the database field in particular. When I started sketching the design of aiHelpDesk, there was no doubt in my mind that informed consent has to be the cornerstone of the review and approval process.
Your database is the patient
Everything is global nowadays. At 2am, your mission critical production database is likely a very much living system under stress. To avoid a page, an AI decides to terminate a connection, restart a service or modify a configuration parameter. All of these are interventions. They have consequences. The wrong intervention at the wrong moment can cascade. Can spiral. Can take the whole database down.
The question isn’t whether AI should be involved. Of course it should. An AI that can identify a root-blocker PID holding a lock chain across four sessions in 8 seconds is objectively better than a DBA woken from sleep at 2am and scrambling to do the same thing in 20 minutes. I’ve been that DBA, I know. But more importantly, you should be expecting a lot of these 2am incidents because the avalanche is coming and as result, these 2am adventures are bound to happen more and more often. And so fast emerging AI SRE practice is likely inevitable.
That’s not the question. The question is this: what happens between “AI forms a diagnosis” and “AI takes an action”?
In many AI SRE tools I see offered today: nothing. The diagnosis leads directly to action.
How it should work
At aiHelpDesk we beg to differ. This is how we believe AI SRE / DBA systems should work for triage/remediation handoff, the protocol:
- First off, there should be a clear, formal separation between the two. Triage is one thing. Remediation is another. With the option to offer customers a formal handoff between the two.
- The results of a triage should be (optionally, but also by default) presented to a customer for review. We call it informed gate
- If a customer decides to review the triage and finds the diagnosis reasonable, they should also be presented with the plan on how to fix it. Right then and there. On the same page
- An operator may agree with the diagnosis, but disagree with the remediation. That’s normal
- Only if both, the diagnosis and the remediation plan looks reasonable, a customer lets the remediation proceed
- While optional, a customer is also offered and is encouraged to provide a gate-level feedback as to why they agree or disagree with the above
- Irrespective of the LGTM, a customer is free to chose on how to approve the remediation: step-by-step, only for the write/destructive parts (e.g. terminate connection) or let it run unattended
- A customer is highly encouraged to provide a post-incident feedback on the whole process to improve triage and remediation accuracy over time. aiHelpDesk provides a formal tracking mechanism and its effectiveness (or what we call “accuracy”) hinges on the customer’s feedback
That’s aiHelpDesk informed consent.
We strongly encourage our customers to incorporate the step of providing feedback (both at-gate and post-incident) in their SoP to improve playbook’s accuracy over time. Here’s our proposal. And yes, this feedback is part of what enhances our Operational SRE/DBA Flywheel (see here and here).
Two sides of the Informed Consent coin
The results of a triage that are optionally (and by default) presented for a customer to review, is not a safety feature. It’s the first part of the informed consent:
The diagnosis:
HYPOTHESIS_1: Root blocker PID 867 holding ACCESS EXCLUSIVE lock | CONFIDENCE: 0.98
HYPOTHESIS_2: Idle-in-transaction session | CONFIDENCE: 0.02 | REJECTED
ROOT_CAUSE: HYPOTHESIS_1
At the gate, this is the first thing that a customer sees before approving. Next, the open gate presents the preview of the proposed remediation action. On the same review page. How does aiHelpDesk plan to go about actually fixing the problem it just diagnosed:
Diagnosis: Root blocker PID 867 [98% confidence]
Holding: _faulttest_lock_chain (4 locks)
Downstream: 3 sessions blocked
Proposed action: pbs_lock_chain_remediate
Step 1: inspect_connection(867)
Step 2: terminate_connection(867)
Approval mode: manual
Approve? [y/n]:
This is what informed consent looks like for AI SRE. A customer sees exactly what the agent concluded and how exactly it plans to fix it. Nothing less. A human gets the full picture of what about to transpire if they agree to it. If they give consent.
And yes, the critical point is the awareness of not just problem diagnosis, but how it was arrived at. Every step of what artifacts were reviewed, what parts of them caught the AI’s attention, how it influenced AI’s analysis and how it formed its hypotheses. And yes, the proposal of how it can be rectified too.
All of that, before any drastic, remedial action is taken.
And that’s the other part of aiHelpDesk informed consent.

The at-the-gate approval, if given, with a timestamp, operator identity and optional free-text feedback reason, is stored permanently and is used for improving aiHelpDesk triage process.
Hypotheses :
[PRIMARY 95%] Severely undersized shared_buffers
(4096 × 8kB = 32 MB, set via command line) causing large
sequential scans on test_large_table (54 MB) to flush
the buffer pool and evict hot pages to disk
[REJECTED 80%] Large sequential scan activity on undersized buffer pool —
Secondary contributing factor, not primary cause —
the configuration itself is the root issue that
must be addressed first
────────────────────────────────────────────────────────────────
⚠ CONFIDENCE WARNING: Primary hypothesis confidence 95% —
Competing hypothesis at 80%.
Uncertain diagnosis: consider step-by-step approval.
────────────────────────────────────────────────────────────────
Approve remediation? [y/N]: y
Approval mode [manual/review/auto] (default: manual): review
Reason (optional, press Enter to skip): LGTM because while there's another
hypothesis, from experience of
knowing the workload on this DB,
I agree with the primary one
The diagnosis confidence at the gate is the key detail here: if the AI’s primary hypothesis confidence drops below 50%, the gate opens automatically, regardless of the playbook’s approval mode. Similarly, if there’s more than a clear explanations, with a few competing hypotheses with comparable confidence level and so the diagnosis is uncertain… that’s the reason for escalation (although not immediately to a human operator perhaps, but to another agent to continue investigation first — we refer to this feature as automatic playbook chaining), which may also result in automatically opening the gate.
The point is this: The system knows its own limits. A confident AI that’s wrong is more dangerous than no AI. On the other hand, an AI that flags its own uncertainty and asks for a second opinion is on the way to become trustworthy. And that’s the non-negotiable bar we set for aiHelpDesk.
Triage accuracy
This is my experience, so I expect this to be a contentious point, but here’s the uncomfortable truth I see about autonomous AI SRE: the more confident the model, the less humans trust it. And that’s backwards. High-confidence wrong answers are the most dangerous failure mode, precisely because no one is looking.
The industry talks about “AI confidence scores” as if they’re already solved. They’re not. Confidence calibration is an open problem. Does 95% confidence actually mean 95% accuracy? Most tools don’t measure it at all. Let alone record it. They express certainty, operators disengage oversight and when the 5% failure happens on a Friday night, there’s no record of who decided what.
Compare that to what aiHelpDesk ships:
Was the diagnosis correct? [y/n/skip]: y
Actual root cause (Enter to confirm: "Severely undersized shared_buffers
(4096 × 8kB = 32 MB, set via command
line) causing large sequential scans on
test_large_table (54 MB) to flush
the buffer pool and evict hot pages
to disk"):
Feedback submitted (run_id=plr_5090eed8)
Remediation: RECOVERED in 17.4s (score: 100%)
Incident plr_5090eed8 — resolved in 0.1s
Diagnosis : Severely undersized shared_buffers
(4096 × 8kB = 32 MB, set via command line) causing large
sequential scans on test_large_table (54 MB) to flush
the buffer pool and evict hot pages to disk
Remediation: pbs_cache_miss_remediate
Narrative : GET http://gateway:8080/api/v1/incidents/plr_5090eed8
Vault: draft saved → pb_82f54c1c (activate with 'faulttest vault list')
time=2026-06-09T17:41:41.571-04:00 level=INFO msg="tearing down failure" id=db-high-cache-miss type=sql
Diagnostic Result: [PASS] score=100% (keywords=100% tools=100% judge=100%)
Remediation Result: [PASS] score=100% (0.1s, playbook)
Overall Result: [PASS] score=100%
Yes, aiHelpDesk ships the feedback loop that starts closing this gap: every operator decision (“was the diagnosis correct?”) flows back into a per-playbook accuracy rate. Over time, the system surfaces whether its confidence scores match its track record. That’s the difference between a tool that says “I’m 95% sure” and a tool that can prove it.
$ go run ./testing/cmd/faulttest vault list --gateway $GATEWAY --api-key $API_KEY
FAULT PLATFORM DIAG PLAYBOOK REMED PLAYBOOK FAULT TEST INCIDENTS
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
db-max-connections any pbs_connection_triage pbs_connection_remediate 2026-06-08 PASS 3 runs 33% resolved 100% accurate last: 2026-06-08 (system)
db-long-running-query any pbs_slow_query_triage pbs_slow_query_remediate 2026-06-09 PASS 2 runs 50% resolved – last: 2026-06-09 (system)
db-lock-contention any pbs_lock_contention_triage pbs_slow_query_remediate 2026-04-22 PASS 2 runs 50% resolved – last: 2026-06-09 (system)
db-table-bloat any pbs_vacuum_triage pbs_vacuum_remediate 2026-06-09 PASS 1 runs 100% resolved – last: 2026-06-09 (system)
db-high-cache-miss any pbs_cache_miss_triage pbs_cache_miss_remediate 2026-06-09 PASS 6 runs 83% resolved 100% accurate last: 2026-06-09 (imported)
...
$ go run ./testing/cmd/faulttest vault accuracy --gateway $GATEWAY --api-key $API_KEY
FAULT SERIES FEEDBACK CORRECT ACCURACY
──────────────────────────────────── ──────────────────────────────────── ──────── ─────── ────────
db-tx-lock-chain-blocker pbs_lock_chain_triage 2 2 100%
As an aside: What does it mean to have 83% resolutions of a specific failure scenario that boasts 100% accuracy? (from the above sample listing for “db-high-cache-miss failure)
83% resolved ≠ accuracy. These two metrics measure different things:
– Resolved refers to an outcome of the remediation runs. In this particular case that would the outcome of the pbs_cache_miss_remediate playbook. The main question it answers is this: Did it actually fix the problem? That’s what Resolved measures. 5/6 resolved means that one run was abandoned/failed, while the rest succeeded.
– Accurate measures the operator feedback on the triage runs . The playbook in question here is pbs_cache_miss_triage. And the question that this metric is designed to answer is this: Was the root cause diagnosed correctly? There were only two submitted feedbacks (not good!) and both claimed “yes”, hence accuracy=100%.
These two are independent per-failure-scenario signals. One is about triage, while the other is about remediation.
Autonomy is not the goal
What happens when the model is “mostly right”… except at that 2am incident when it wreaked a complete havoc in your mission critical database.
Ask yourself what your current AI SRE platform records at the moment of that intervention. Who approved the action? What evidence and chain of thought they were presented with? Was the info shown sufficient for them to make a decision? On both, the diagnosis and proposed fix? What was the confidence level? Any alternative, but comparable hypotheses, which were reviewed, but rejected? Was the diagnosis later confirmed as correct?
Or, to make it short: was the informed consent rendered?
If the answer is “we don’t track that,” you don’t have an autonomous system. You have an unaccountable one.
Autonomy is not the goal. Trustworthy autonomy is the goal. And trust needs to be earned. Trust is built from records, from consent, from feedback loops that prove the system earns the deference operators give it.
The gate isn’t a limitation on AI capability. It’s the infrastructure that makes AI capability usable in production. In production where the stakes are real, the blast radius is must-have and “the model was mostly right” is just plain not acceptable to the business.
In a nutshell
And this this is the blog post in a nutshell: I believe that the medical metaphor that I opened with is visceral. Nobody in the right mind thinks that surgeons operating without consent is acceptable. And the parallel to production systems is discomfiting precisely because, in my perception of the industry, most AI vendors haven’t thought about it this way. The concrete technical detail I listed in this post (the gate output, the confidence scores, the feedback loop) proves this isn’t philosophy. It ships.
aiHelpDesk is open source. Everything mentioned in this post is part of the 0.16 release. Take it for a spin, give us a feedback or open a PR!
Why aiHelpDesk Playbooks are trustworthy?
Because we give you, the customer, an ability to vet, verify and improve them through the methodology that we refer to as Operational SRE/DBA Flywheel, see here and here for details.
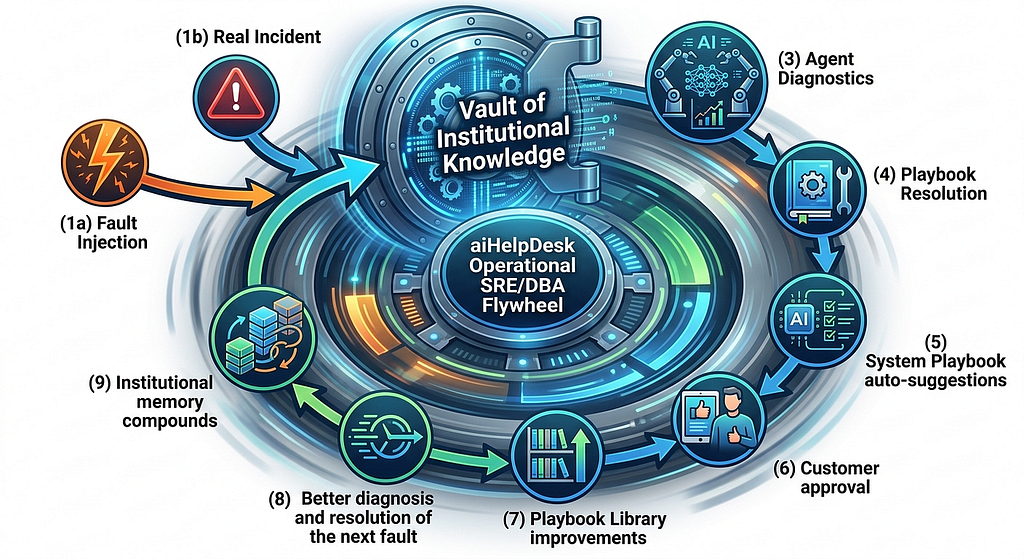
And yes, as a customer, you can not only confirm that the playbooks that you get with aiHelpDesk out of the box work for your environment, but you can easily bring your own. Both: BYO playbooks (by either importing your existing runbooks or cloning and customizing one of our’s or by creating one from scratch) + BYO faults as well.
Because nobody knows your specific databases, your environment and your workload with your upstream/downstream apps better than you do. You know how your database fails. Vendors don’t. At aiHelpDesk, we give you an option to create your own faults and add your own playbooks to triage and rectify them (in addition to the system playbooks we ship, of course).
And yes, we don’t depend on a particular model or a model provider. aiHelpDesk is model agnostic. From our standpoint, the LLMs are a disposable commodity. Flip from Gemini to Anthropic and aiHelpDesk should continue to give you exactly the same diagnosis and remediation. Anything shorter than that is a P0 bug.
Related Reading
- aiHelpDesk Flywheel official documentation
- Your SRE On-Call Runbook Is Already Obsolete. Here’s Why That’s Not Your Fault: Introducing aiHelpDesk Operational SRE/DBA Flywheel
- The Missing Test Suite for AI Database Operations: You’re about to bet your SRE/DBA on-call rotation on an AI agent. Want to know if it’s any good before the 2am page goes off?
- Runbooks Rot. Playbooks Learn: Operational SRE/DBA Flywheel: Ops Knowledge That Compounds. Automatically. Improving with every incident
- We Wanted a Dramatic AI Agent Failure. We Got Something Better:
When the Flywheel works: The K8s WAL fault that made us rethink what playbooks are for - AI Database Troubleshooting: the PostgreSQL Stat That Looks Like Good News (But Ain’t): What a bgwriter incident taught us about the difference between reading data and understanding it
- AI troubleshooted DB pileup and reported success. The locks didn’t care: It’s the story that shows that the model wasn’t bad at reasoning. But it reasoned without the right knowledge.
- Your AI Just Diagnosed the Outage. Should It Fix It Too? How Decision Hub puts a human at every boundary between knowing and doing. And how we tried to override our own governance model and it said no. Twice.
As of this writing, aiHelpDesk is available in Beta. If you’re running PostgreSQL in production and would like to get help in preparing for the avalanche, consider aiHelpDesk. Reach out to us at info@aiHelpDesk.biz and we’ll be happy to show you what it looks like in practice.
You let AI Operate on Production Database Without Your Consent? was originally published in Google Cloud – Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source Credit: https://medium.com/google-cloud/you-let-ai-operate-on-production-database-without-your-consent-bd4ffb954266?source=rss—-e52cf94d98af—4





