: Introduction to the series")
This is the introduction to the ADK2.0 101 series — no code today, but do not skip it.
While the full series covers agent architecture, tool use, memory, orchestration, and production deployment using Google’s Agent Developer Kit with Python (2.0), we are starting with the absolute essentials. In this post, we’ll dive into the best practices for architecting AI Agents that actually survive and won’t end up buried in the AI project graveyard.
We will map out the core workflows and discuss how to design subagents, leverage specialized tools, and implement advanced communication patterns like the A2A (Agent-to-Agent) protocol and the MCP (Model Context Protocol).
Let’s introduce Sosta App— the real-world product we will be building together throughout this series to master the ADK in action.
What do LLM, Agents and Agentic AI bring to the table?
AI is everywhere, and when people are asked (and you are asking to the optimistic ones), common answers are “more creativity, impact and possibilities” but in this hype hides a deadly threat: the AI project graveyard.
This fancy term is used to describe the fate of many ambitious artificial intelligence initiatives that start with high excitement but are ultimately abandoned because they fail to deliver real business value.
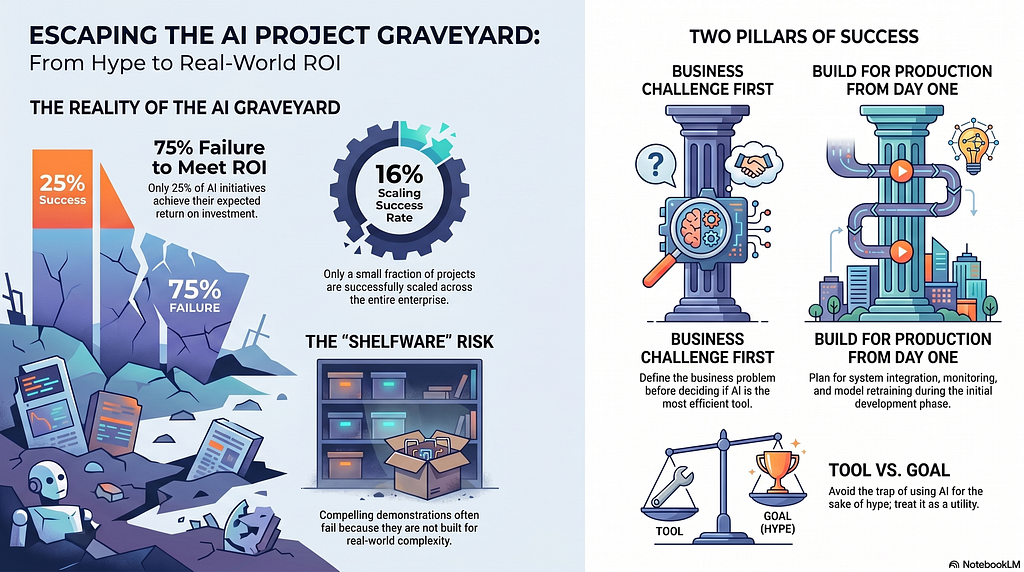
Many of these projects end up stuck in the pilot phase because teams drastically underestimate the complexity of turning a compelling demonstration into real-world impact. For example, Fortune indicated that only 25% of AI initiatives achieve their expected return on investment (ROI), while IBM stated that mere 16% are successfully scaled across an enterprise.
Of course, there are many reasons for these failures, but the main I want to address here are:
- AI is treated as the end goal rather than a tool how many times have you heard “I want to use AI for this” when a simple calculator may be more efficient. To prevent this, organizations must define their business challenge and then decide if AI is really needed.
- Developers must build for production deployment from day one by planning for system integration, monitoring for performance drift, and retraining the model as data changes; failing to do so leaves a working prototype stuck in a notebook as useless “shelfware” rather than a valuable, functioning system.
Therefore, all this hype and range of possibilities make sense only if we take into consideration at least these two points.
Business Challenge, Business Requirements and Functional ones
Before even starting this serie, I believe, it is therefore important to start by addressing a business challenge, aka start with a problem, not the technology.
Let’s present our real-world product. For a passionate foodie and traveler like me, road trips ought to be pure bliss. Instead, navigating Italy in an electric car turns them into a logistical nightmare. Thanks to a sparse charging network and agonizingly slow plug-in times, I’m stuck constantly stressing over two things: where to juice up the car, and where to actually find a decent meal. Therefore, I will take this personal frustration and use it to define the business problem that we will try to solve throughout this series:
“Users of electric and LPG vehicles experience ‘range anxiety’ and frustration because refueling stops rarely align with places where they can find food they like, making the journey stressful and inefficient.”
To solve this, let’s say we want to create a Sosta product (btw. ‘sosta’ in Italian means ‘stop’) with the business requirements (BR), aka define the high-level objectives of the project, which in our case may be formulated as follow:
- BR-01: Intelligent Trip Optimization. The system shall reduce user “range anxiety” and “choice fatigue” by providing integrated routing that synchronizes vehicle refueling needs with personal dining preferences.
- BR-02: Personalized User Experience. The system shall leverage historical user data to offer tailor-made stop suggestions, increasing user loyalty and engagement.
- BR-03: Operational Efficiency. The system shall minimize total travel time by overlapping vehicle charging/refueling durations with meal breaks.
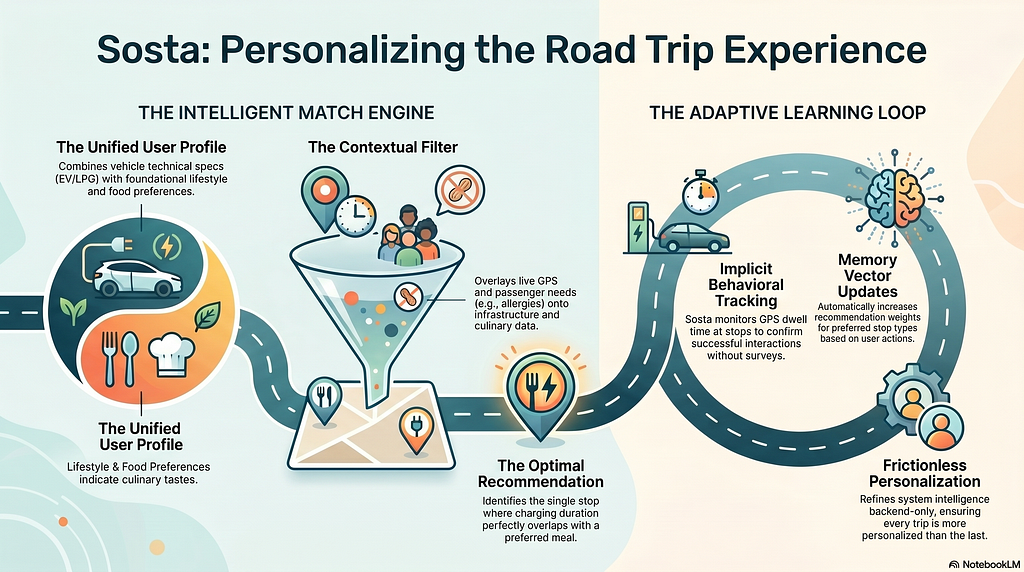
Just as fuel powers a vehicle and food drives a human, data is the lifeblood of an AI agent. Building a robust system requires a comprehensive audit of available data sources and infrastructure to ensure the ‘intelligence’ has the necessary fuel to operate, that for this simple usecase may be listed as follow:
- db_soste lists all stops available in the autogrills with coordinates
- food-kb lists their products and the reviews for each autogrills
In addition, the business is interested in tracking down all the food preferences in an agent-memory that tracks for each user their choices.
Another important category is Functional Requirement (FR), aka a summary of behavior between inputs and outputs, which for now we can list as follow:
- FR-01: Proximity Search. The system must query db_soste to identify all available stops within a specific radius of the user's current GPS location or along a planned route.
- FR-02: Technical Compatibility Filter. The system must filter stops based on the user’s car type (e.g., matching EV plug types, Fast/Ultra-Fast charging availability, or GPL station presence).
- FR-03: Product Catalog Retrieval. For every stop identified in db_soste, the system must retrieve the corresponding product list and menu items from food-kb.
- FR-04: User Authentication. The system must provide a registration and login interface to associate a unique UserID with the agent-memory.
- FR-05: Preference Matching. The system must retrieve the user’s stored food preferences from agent-memory and cross-reference them with the filtered list from food-kb.
- FR-06: Memory Update. The system must update the agent-memory after each trip based on the stops selected or ignored by the user to refine future suggestions.
For now, we will stop here, avoiding to take into consideration any non-functional requirements (such as expected latency, if offline mode is needed, privacy regulation etc.) nor we will speak about the scoring logic to identify the best stop, since this is specific to this exact problem.
User Experience & Flowchart
A user interface [aka User Experience] is like a joke. If you have to explain it, it’s not that good — Martin LeBlanc
Once we have the defined our business problem, the requirements and available data source, it is time to go though the user experience drawing a flowchart to describe the logic behind our Sosta product.
The process begins with the Sosta entry point, immediately transitioning into a security and personalization layer. The system first attempts to Confirm User Identity by checking for an existing account within its memory to create a critical fork in the road: registered users are prompted for their User ID, which triggers the retrieval of their historical data. For those without an account, the flow offers a “warm start” onboarding, inviting them to register and save their Culinary Preferences and Vehicle Type to ensure that every subsequent step is anchored in the user’s specific lifestyle and technical needs, transforming a generic tool into a dedicated assistant. Once identity is established, the workflow moves beyond static profiles to capture the “here and now”.
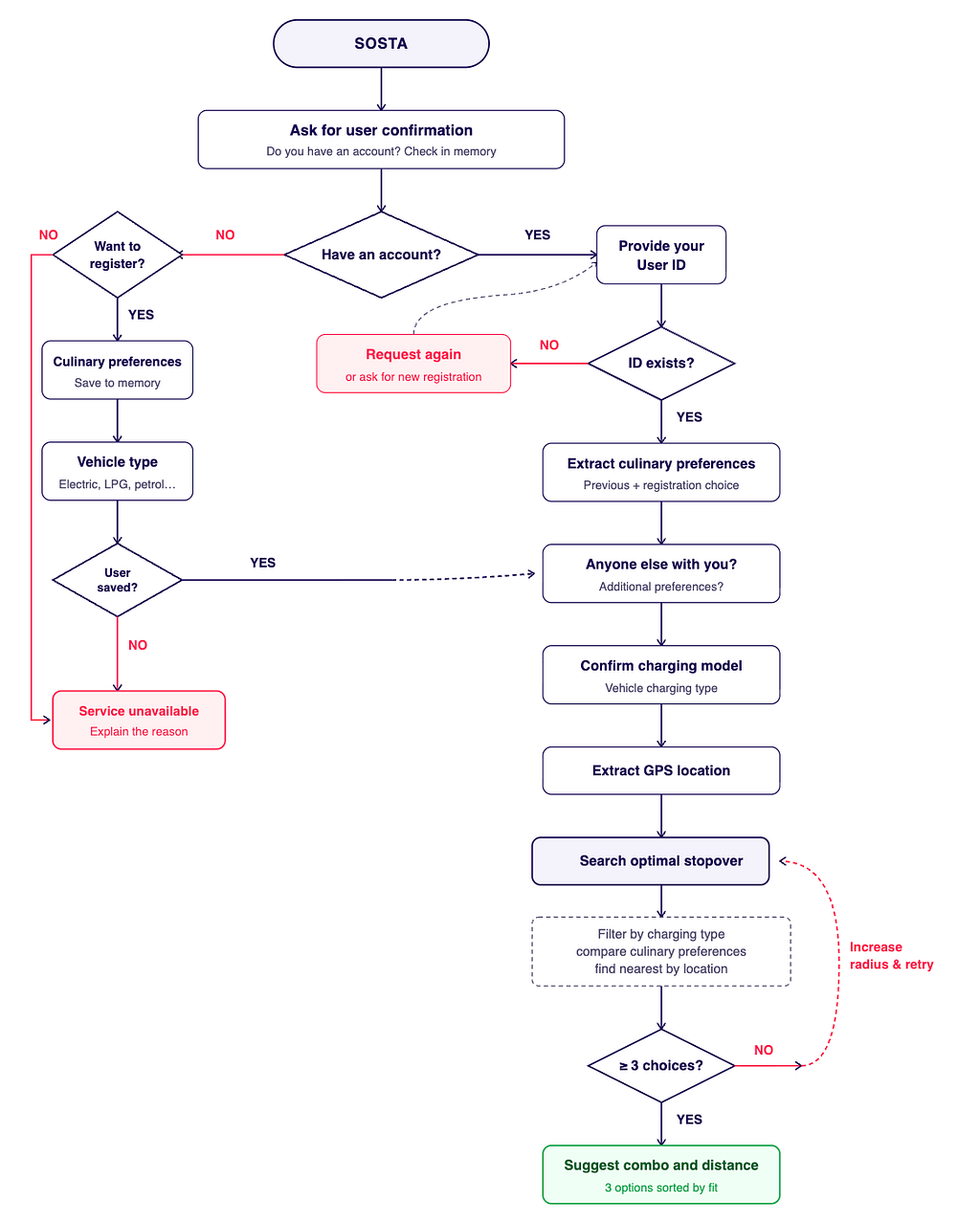
The system asks a vital contextual question: “Anyone Else With You?”, allowing it to adjust its recommendations for group needs or dietary restrictions of passengers. Simultaneously, it validates the Charging Model to ensure technical compatibility with the vehicle’s current energy requirements. By combining these social and technical inputs with the Live GPS Position, the system narrows the infinite field of possibilities down to a hyper-relevant geographic perimeter.
The climax of the workflow is the Optimal Stop Search, where the system acts as a data orchestrator, filtering for charging compatibility, matches the menu offerings against the user’s (and passengers’) preferences, and sorts the results by proximity, ensuring that the final recommendation isn’t just the closest stop, but the most satisfying one.
The Reality Check: Why Do We Actually Need an AI Agent?
As already mentioned, do we really need AI for this Sosta product?
Let’s be completely honest and skeptical for a moment. If you look at our flowchart, a cynical developer might say: “Can’t I just build this with a traditional backend, a Postgres database with vector extensions, and a few smart API joins?”
It’s a fair critique.
We shouldn’t use AI just because it’s trendy. However, while standard deterministic programming excels at fixed rules, it completely falls apart when forced to navigate the unpredictable, chaotic intersection of human cravings and real-world infrastructure.
When you look closely at the operational challenges of a product like Sosta, the architecture requires a level of fluid reasoning that traditional code simply may not replicate. Here is where the AI Agent earns its keep:
- Taming the Chaos of Unstructured Data If our food-kb database consisted of tidy, uniform data fields like has_gluten_free: true, a standard SQL query would win. But real-world data is messy. Food quality and availability live in raw text, evolving menus, and highly subjective user reviews (e.g., "They have a decent gluten-free corner by the register, but the vegan options are sad"). Standard software struggles to contextualize nuance, while an AI agent excels at semantic matching and sentiment analysis, effortlessly translating a user's abstract craving for "something light and healthy" into a logical match within unstructured text data.
- Contextual Synthesis (Beyond Simple Filtering) Traditional recommendation engines can look at a history table and suggest a product you’ve bought before. But they lack the ability to synthesize why and when. Sosta’s agent-memory doesn’t just filter options; it reasons like a human concierge (BR-02). It looks at the driver’s historical patterns, overlays it with the current vehicle telemetry, and synthesizes a solution: “I see you usually buy a Caprese sandwich on morning trips. They have it fresh right now at the Secchia Ovest stop, which also happens to feature the exact Ultra-Fast charger your car needs to stay on schedule.”
- Eliminating Cognitive Load with Conversational UX No one should be tapping through multi-select dropdown menus, checking boxes for EV plug types, and typing out passenger dietary restrictions while driving down the Autostrada at 130 km/h. A traditional user interface demands too much cognitive load in a vehicle. By utilizing an AI agent, we shift the interface to a voice-first experience. The driver can simply hit a button and say: “I’m starving, I need to charge my Tesla soon, and my passenger wants something dairy-free.” The agent acts as an autonomous intent-parser, instantly converting that single, unstructured sentence into precise routing coordinates, technical parameters, and database queries without the driver ever taking their eyes off the road.
Why ADK? The Five Pillars of Agentic Design
Therefore, we will agree that an AI agent would be the best choice. Now, let’s go back to the second founding principle of this series: build for production from day one.
That’s where ADK — the Agent Developer Kit — earns its place. It’s an open-source (Apache 2.0), code-first framework for building, orchestrating, and scaling AI agents, and it imposes structure that keeps you out of trouble before you know you’re in it.
ADK or Agent Developer Kit is not the only one (nor in some cases the best one) to handle Agent AI developement, but in this cases it help us to create an already structured foundation from the beggining and here is why:
- The “Polymorphism” Benefit In the fast-moving AI world, today’s best model is tomorrow’s legacy code. ADK forces interchangeable parts by adhering to a unified interface. You can swap models, providers, or tools without rewriting your entire logic.
- Control vs. Creativity (Determinism) Building for production often requires a balance. ADK allows you to mix deterministic tools with non-deterministic agents and ensure your application stays grounded with up-to-date, accurate data while retaining the “brainpower” of an AI.
- Orchestration & Routing Real-world applications rarely rely on a single “god-agent.” ADK is built for composition, allowing you to link small, specialized agents into complex, hierarchical teams that can route tasks to the right expert at the right time, building modular multi-agent systems.
- State Management Standard LLM APIs are stateless — they forget as soon as the request ends. ADK provides built-in State Management, giving your agents a persistent memory of the conversation and the tasks they’ve completed.
- Observability & Traceability When an autonomous agent fails, it can be a “black box” nightmare. ADK includes integrated traceability tools, allowing you to peek under the hood to see exactly where a reasoning chain went off the rails.
So, now that we may say we have statisfied the two main principles to avoid AI project graveyard it is time to jump to the jump to an old concept.
What’s Next
This article has done one thing: established why we’re building Sosta, what it needs to do, and why a standard backend won’t cut it.
We haven’t written a single line of agent code yet — and that’s intentional. Skipping this foundation is exactly how projects end up in the graveyard.
In the next installment, we’ll move from architecture to implementation — setting up the ADK, dividing the system into agents, and connecting them to Sosta’s data sources. We will discuss subagents and tools, the A2A protocol, and the MCP to decide the best points in the workflow to use them.
Block by block, we’ll turn this blueprint into a system that could actually run on your next road trip.
ADK101 Hub| Next: Part 2 (Coming Soon)»
ADK2.0 101 (#0): Introduction to the series was originally published in Google Cloud – Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source Credit: https://medium.com/google-cloud/adk2-0-101-0-introduction-to-the-series-42a36f19b077?source=rss—-e52cf94d98af—4





