
Red-Crested Cardinal, Hawaii
Agents with Gemma 4
In my last blog, Creating ADK Agent using locally running Gemma 4 , I wrote about how Gemma 4 can be used with ADK to create an ADK agent. I wanted to see if I could create a local Gemma 4-powered bird knowledge base that allows me to look up information about any bird just using my local environment. In my previous experiments, I found that while the Gemma 4 31B model was able to answer many of my questions, the Gemma 4 26B parameter model was not. Since Gemma 4 31B needs much larger compute power, I want to create a system that can reliably give me answers using authoritative sources.
About the Data
For this project, I will leverage Wikipedia as the primary data source. While Wikipedia offers comprehensive information and accessible bulk downloads, it contains a significant amount of data irrelevant to our specific use case. Processing the entire dataset would unnecessarily strain local compute resources. Consequently, the initial phase involves downloading the complete dataset (approximately 30GB) and designing a custom pipeline to isolate and extract only the relevant ornithological data.
The primary objective is to locate Wikipedia pages for every bird species globally. Given that there are approximately 10,000 species, an efficient strategy is required to identify these pages within the vast Wikipedia dataset. Wikipedia organizes content into multiple, often overlapping categories. Upon investigation, I discovered that bird-related pages consistently include their taxonomic genus in the category metadata. By identifying all bird genus category IDs, I can effectively track and extract all bird-specific pages from the dataset.
Data Analytics Environment
The following tools were utilized to analyze and filter the dataset. Given the substantial volume of information local execution was deemed impractical due to the significant processing time required.
- Cloud Workstations
- Antigravity CLI built in Cloud Workstations
- BigQuery
Cloud Workstations offers an exceptional development environment, serving as a fully serverless workbench with scalable compute and storage. It features a built-in, VS Code-inspired text editor and a terminal equipped with the Antigravity CLI. Because it resides within Google Cloud, it integrates seamlessly with other services like BigQuery, which is essential for our data analytics workflow.
Figure 1: Google Cloud Workstations
Some of the data from Wikipedia comes in SQL format so we can use BigQuery to store that data and query it later. As mentioned above Cloud Workstations comes with Antigravity CLI built-in so we will use Antigravity to orchestrate the Data Pipeline.
Orchestrating the Data Pipeline
Data Pipeline was orchestrated in following steps fully using Antigravity CLI.
1. Extract all the genus taxonomy data using Antigravity.
2. Download Wikipedia dataset.
3. Extract and Load the Wikipedia dataset in BigQuery using Antigravity.
4. Loop through all the genus names created in Step 1.
5. Use the genus names to find all the bird pages and save the bird pages as text files locally.
6. Once all the extraction is done write all the extracted bird text files to Google Cloud Storage
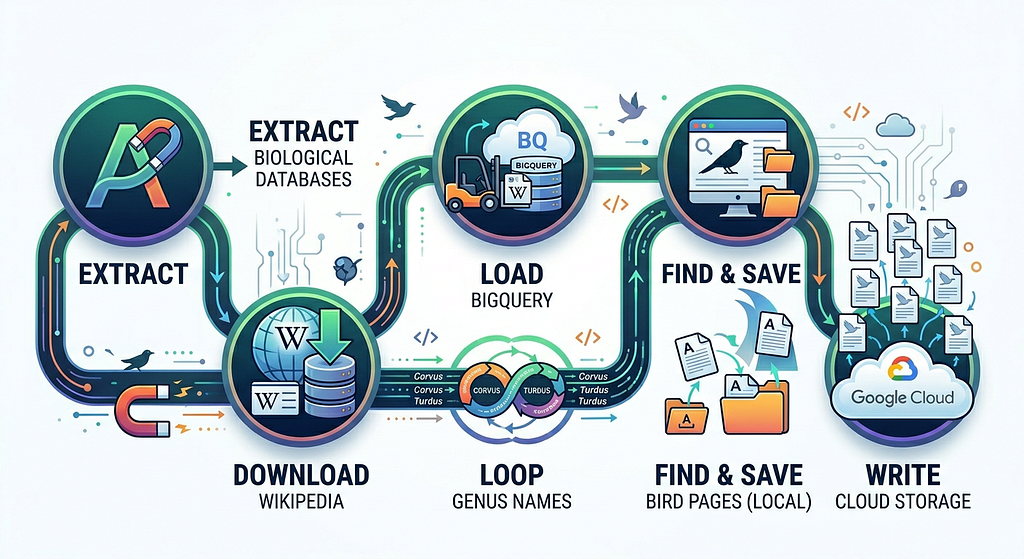
Figure 2: Data Extraction Pipeline.
Once you download the data , you can simply ask Antigravity CLI in Cloud Workstations to take the steps above to get your pipeline running. Once you load the data in the BigQuery you can go to the BigQuery console and confirm if the data is correctly loaded. Within BigQuery you can also chat with the data you added.
Figure 3: Preview of Wikipedia data in BigQuery
Figure 4: You can also chat with the data using BigQuery Chat function
Conclusion
The extraction process successfully identified approximately 2,400 genera and 10,500 bird species. The entire workflow, including data download, was completed in roughly six hours. The combination of Cloud Workstations and the Antigravity CLI provides a robust environment that significantly simplifies complex data processing tasks.
With the dataset prepared, the next phase involves developing a knowledge base. I will then evaluate the performance of a Gemma 4 powered agent in querying this repository.
Originally published at https://bufferof.com.
Building a Local Bird Knowledge Base powered by Gemma 4, Data Preparation was originally published in Google Cloud – Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source Credit: https://medium.com/google-cloud/building-a-local-bird-knowledge-base-powered-by-gemma-4-data-preparation-07def262ebc6?source=rss—-e52cf94d98af—4



")