
I’ve given variations of this article as a conference talk several times, at Google Cloud Next ’26 in a breakout with about 200 developers and again at Wiz’s booth, then a couple days before publishing this article at Zenity’s excellent AI Agent Security Summit. I’ve wanted to go a bit deeper on certain examples and tie together more sources, so writing it down was the natural next step. This is long, longer than the recommended “750 words,” but the good news is I wrote it quickly so you can read it quickly too. I did not use AI to write it so kindly don’t use AI to read it either.
Wander into any of the big security conferences over the past few months, and you’ll see every third row has a screen with a demo showing some tool catching a vulnerability and surfacing the finding under a GitHub PR. It’s easy to show, it lets people know the tool is stopping something bad before the code gets merged, and it meets most bars for having “shifted left,” which are still fairly low. But we really need to escape the idea that this is efficient or scalable beyond a single demo, or that we can’t go a bit further left and do better. We can and should eliminate many issues before the code ever even gets pushed.
Catching bugs in the local editor reduces costs compared to handling a fire drill in the pipeline. This post explains how to integrate security into the local PRGR (plan, red, green, refactor) loop with an agent specifically following TDD. Whether you are writing secure code from scratch or fixing legacy applications, I want to show how establishing consistent (and often not terribly new) software engineering practices is helpful when working with agents writing code.
Vibe Coding Conundrums and the 70% Problem
Ask anyone who spends time generating comments on LinkedIn under posts about vibe coding and they’ll use an LLM to remind you that vibe coding introduces stability and security risks if left without any sort of standards or guidance. And their LLM would not be entirely wrong. While a coding agent can quickly get a prototype 70% of the way to a functional application, completing the remaining 30% requires deep engineering rigor to avoid loops where fixing one bug introduces other functional regressions. This is what Addy Osmani terms the 70% Problem. Developers fall into a “two steps back pattern,” where fixing one bug introduces other functional regressions. More dangerously, vibe-coded applications are highly susceptible to security vulnerabilities; as he notes, “vibe coding is fun until you start leaking database credentials.”
Recent findings from DORA (that is, dora.dev, not the EU regulation nor the musical adventurer) show that unconstrained AI adoption for writing code can pose a few common issues. All of the findings I list below are from the 2025 report, which you can grab for free.
Coding agents tend to make massive, sweeping changes that can quickly overwhelm developers, making it difficult for even experienced engineers to track quality and security issues unless they establish clear boundaries.
Letting an agent run without constraints can result in hundreds of lines of code being generated in a single batch, which might make for fun demos of “one-shotting” or a faux pas LinkedIn post about how you made sooo many lines of code, but actually, it increases review effort (turning into fatigue for developers or context collapse for review agents), and elevates the risk of introducing vulnerabilities that are hard for static tools to catch.
Interestingly though, DORA research also demonstrates that the assumed trade-off between speed and stability is a myth. High-performing teams excel at both delivery speed and system stability simultaneously. So not only does speed not require sacrificing quality, it usually goes hand-in-hand with quality.
Integrating security objectives directly into daily activities (from design to coding to testing) enables teams to spend 50% less time remediating security issues.
Providing the AI agent with clear team conventions, APIs, and requirements guides its scope and boosts individual effectiveness.
Enforcing small, iterative improvements minimizes human review effort and reduces the risk of introducing vulnerabilities. DORA research supports that working in small batches improves product performance and decreases friction for AI-assisted teams.
Enforcing the PRGR (Plan, Red, Green, Refactor) Cycle
To prevent agents from making massive, unguided changes that overwhelm developers, teams can write a persistent context file, such as GEMINI.md or ANTIGRAVITY.md. This configuration guides the agent through a structured four-stage workflow:
Minimize image
Edit image
Delete image
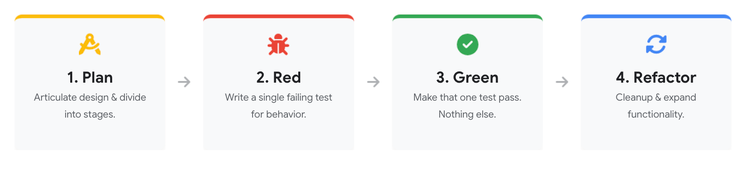
Plan: The agent needs to articulate the architecture and design before writing code. This is pretty common now without configuration [159].
Red: The agent to write a single failing test ideally from the user’s perspective [159]. The test must fail first to prove it covers a new behavior [160].
Green: Limit the agent’s focus exclusively to making that single test pass [160]. Separate this step from writing the test in order to preserve the codebase’s “fitness function,” preventing the AI from modifying the test to match a flawed implementation [160, 161].
Refactor: Clean up the code to maintain quality and expand the persistent context file to prevent recurring issues. This is where you run a security scan, even a basic one, to catch easy issues to fix that you can immediately retest, all before you even commit.
This local structure ensures that we are defining outcomes and reviewing results, which replaces direct, line-by-line developer interaction.
Encounters in the wild
In Spinoza’s philosophy, a “bad encounter” happens when two forces meet and drain each other’s power instead of building it up. He offers that view to explain why there is so much conflict in nature, but moreso to indicate that conflict between reasonable people can be transformed with more self-awareness and a more accurate model of the each person’s motivations. As Travis McPeak points out, when security is treated as a late-stage gate, developers are forced to choose between shipping on time or shipping securely, then 81% of developers admit to knowingly shipping vulnerable code due to competing business priorities. The issue isn’t security or developers per se, it’s the timing and framing of each team’s goals.
To resolve this tension, modern engineering teams deploy the paved road concept. Originating from Netflix’s response to the Heartbleed situation, a paved road takes the security team’s expertise and bakes it directly into self-service tooling, making secure configurations the easiest and most natural path for developers. Shift down instead of left. Instead of playing a reactive game of “whack-a-mole” against vulnerability findings, the team systematically eradicates these vulnerability classes by providing pre-configured, secure-by-default modules.
Under this model, security scanning shifts from detecting vulnerabilities to verifying whether developers are using the paved patterns. To be clear, THAT’s what delivers the real promise of shifting left, not (just) plugging in a ton of CI/CD tools. And guess what? Agents can inherit that ability to using skills and rules.
This shift to proactive security is urgent because we are facing what Gadi Evron terms the AI Vulnerability Storm. It is not (purely) hype, and typically calm, sober security minds that don’t bat an eye at the typical marketing FUD are now genuinely concerned. Anton Chuvakin identifies this barrier as the “Patch Sound Barrier” or the constraint where an organization’s maximum remediation velocity is permanently exceeded by AI-driven vulnerability discovery. In this storm, the median time from vulnerability disclosure to active exploitation has shrunk, with many exploits active in seconds, long before the CVE is published. We cannot patch our way out of this crisis manually.
As a developer who has seen the, shall we say, less glamorous side of security teams trying to do auto-remediation (or convince an unprepared development and operations team to adopt it), that is not comforting. There’s another side to this as well: when a vendor releases a security patch, AI can now reverse-engineer that patch, identify the vulnerability it fixes, and generate a working weaponized exploit in minutes, while enterprise testing and deployment pipelines require an average of 20 days to deploy that same patch.
TDD as a security and stability gate
Someone once told me the more times you add “and” to a claim, the more you set yourself up, because in logic, each “and” is a single point of failure.
I’m going to stick with the “and” in TDD for both security and stability, insofar as they both involve (1) being able to change code with confidence if needed, and (2) narrowing the code you write to what you need.
When an agent optimizes to pass a test, it finds the shortest path to do so. Writing tests after implementation causes the agent to write tests that validate what the code happens to do, which fails to check the intended behavior and masks underlying flaws. To prevent this, TDD must be treated as a non-negotiable software practice if you’re going to use it at all. I’m sorry! It’s extreme, I know. And I see an analogy (and the same pushback) to infrastructure-as-code-or-bust in that if only part of the team or project is using IaC, you’re still running the risk of drift and missing the control gates that IaC-directed scans and policies provide.
At Google, we have the Beyonce Rule: “If you liked it, then you should have put a test on it.” When there are deep debates online about “percentage of test coverage” it seems as misleading a metric as “lines of code.” My thought experiment is, “How unimportant is this code that you wouldn’t put a test on it?” This helps to avoid overly narrow tests of implementation details, and helps you define your unit by behavior rather than lines or blocks. If you set the boundary at behavior, at what the user is getting out of your application, you will not have coverage gaps, and you will quickly identify what can be deleted.
When adding code (and in this case that is, adding value), by forcing the agent to write a failing test (RED) before generating the minimum code to make it pass (GREEN), we establish concrete requirements that restrict the agent’s occasionally erstwhile activity and prevent logic drift. They do sometimes write entire mock libraries for APIs that don’t exist, but that’s on my system and process, not them.
Paul Hammond , whose thoughtful comments on TDD (often responding to less thoughtful posts about TDD) have shown me more about it than just about any source. I think he summed it up best when he wrote, “TDD is the reason I’m never stressed.”
Up Next
- Example of security skills, rules, plugins, and hooks in Antigravity 2.0 and CLI
- Reliability practices for deploying agent-written security remediations
- The ever changing state of models and static tools in the SSDLC
Recommended Technical Readings
- Getting Started with Antigravity 2.0
- Antigravity CLI Tutorial Series
- Wiz Research: State of SDLC Security 2026
- SRE Handbook
- DORA 2025 Report
- Beyond Vibe Coding: A Guide to AI-Assisted Development
- The Factory Model: How Coding Agents Changed Software Engineering
Why is test-driven development with agents so helpful for security? was originally published in Google Cloud – Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source Credit: https://medium.com/google-cloud/why-is-test-driven-development-with-agents-so-helpful-for-security-841710b90430?source=rss—-e52cf94d98af—4



