
A year ago I published a working framework — ‘developer experience’ for AI-native development, the AI Harness which is my opinionated ‘seed’ of ai powered development project — spec-driven workflows, grounding files, skills, subagents, hooks, and validation gates, with the architecture ladder kept human-owned — defining the Definition of Done and Ways of Working with the AI skills. I’ll be honest about the limitation of that guide: it described a harness without showing one under sustained load.
I have updated my harness baseline but also I have never (yet) shared my skills layout, — how I actually work with this harness, and what happens after i ‘seeded’ my new project with this very AI Harness. This is that missing Part 2.
Since then, the same doctrine has been running a multi-agent trading platform — ADK agents behind an MCP tool spine on Cloud Run, scanning markets and logging every decision, unattended, every trading day. And with Google Antigravity, the harness concepts from Part 1 stopped being conventions I maintain by hand and became first-class product primitives. This post walks through my very real pet project SentinelHub (part of DevPost Hackathon once — developed in my local sentineltrader workspace) to walk through that mapping and showcase Antigravity IDE capabilities, as a chosen IDE — its features, capabilities, to help answer to a problem the project actually flagged in practice.
I’ve written before on rapid development, harness powered enablement here and the new worth of dev SME time. but thats on another topic. This post is what that thesis looks like when you have to live with it.
The Antigravity IDE (AGY) in Practice
The system i test this doctrine against is a personal project called SentinelHub: an automated market-intelligence and trading platform i built and operate solo. Under the hood it is an ADK multi-agent system — a root orchestrator coordinating specialist agents for data freshness, market analysis, strategy, risk validation, execution, and reflection — with the tools exposed through MCP servers on Cloud Run, and a dashboard on top. It runs every market day, unattended, and it logs every decision it takes. In other words: it has consequences, which is exactly what makes it a useful proving ground.
The part that matters for this series: SentinelHub was seeded from the Part 1 repo.Now, the same grounding files, skills, and validation gates i wrote down as doctrine bootstrapped this project on day one, then grew project-specific — trading rules in the grounding, backtest pipelines in the skills, risk auditors in the gates. Antigravity is where that harness now runs day to day, and the value shows up as a trade i will take every time.
The agents move fast, and the harness keeps the output consistent, coherent, and complete.
Normally this is where the author inserts a hand-drawn architecture diagram. i did something lazier and more honest: i opened an Antigravity session in the repo and asked it to visualise the data flow of its own system.
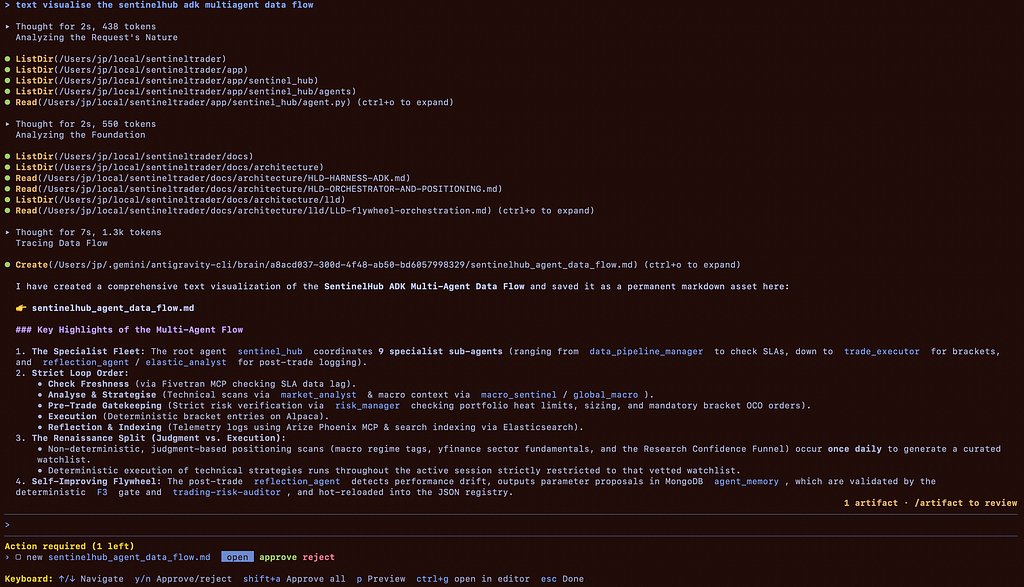
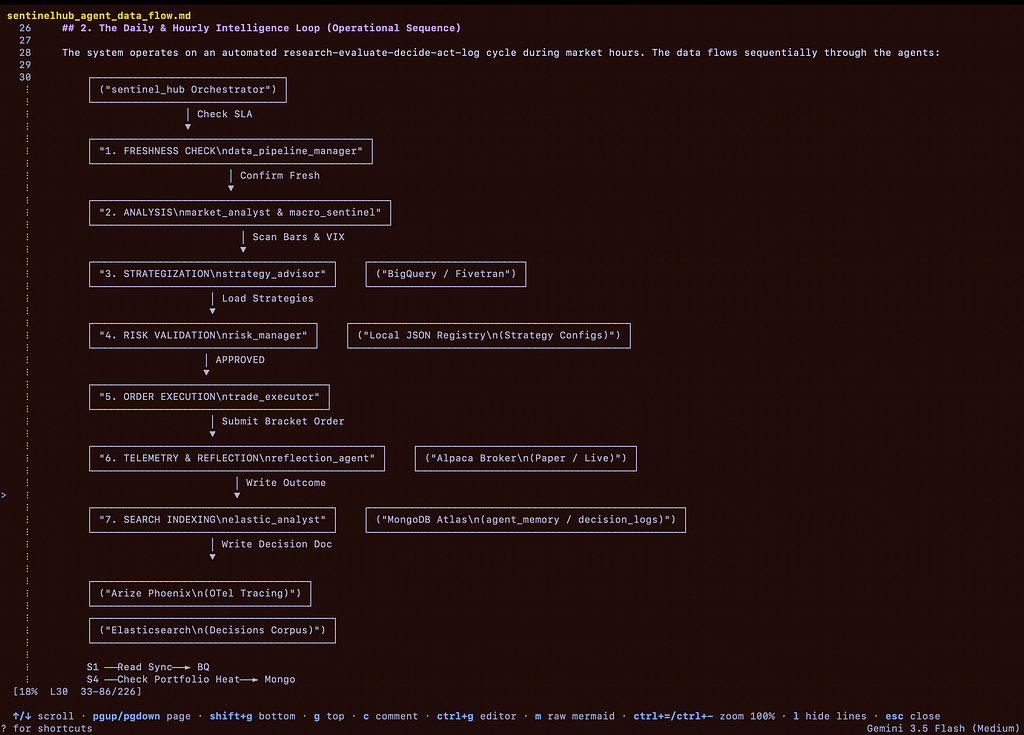
That small exchange is the post in miniature: grounded context in, verified artifact out, a human approval in between. Now for the parts that make it work.
The primitives, mapped to the doctrine
Grounding → AGENTS.md, rules and workflows. Part 1 argued every project needs a context contract the agent cannot miss. In Antigravity that contract is AGENTS.md at the project root, read at session start and applied throughout, with global rules living at the user level (~/.gemini/GEMINI.md) and reusable procedures saved as workflows you invoke by name. Our trading platform's constitution (trading rules, risk doctrine, decision hierarchy) translated into this structure almost without edits.
Capabilities → skills. A skill is the unit of taught capability: a SKILL.md whose description gets indexed up front, with the body and resources loaded only when the agent decides it needs them. The operational win is that a skill authored once is a file, not a deployment. Our harness carries 25 of them (backtesting, health checks, data-quality gates, EvalOps, security audit) and each one is a record of something the system once got wrong. That is the harness-evolution point: you don't design this catalogue up front, you accrete it, one taught lesson at a time. (There is a hands-on codelab if you want the mechanics.)
Procedures → workflows. Alongside skills sit 23 named operational procedures (premarket checks, calibration, decision review, status reporting), each a slash-command file today, each mapping onto an Antigravity workflow you invoke by name. Skills are what the agent can do; workflows are what the operator asks for on a schedule. The distinction earns its keep the day someone else has to run your system.
Orchestration → subagents and the Agent Manager. Part 1’s multi-phase orchestration (parallel domain validators) required scripting discipline. Antigravity’s Agent Manager makes the pattern visible and steerable: parallel subagents with isolated context, dispatched and supervised from one surface, each with its own artifacts, merged by the parent when they land. This is where the platform’s most important pattern now runs. More on the Adversarial Gate below.
Guardrails → lifecycle hooks and permissions. Deterministic interception: hooks fire on events like PreToolUse, PostToolUse, and SessionStart, and the permission engine models sensitive operations as resources on Deny / Ask / Allow lists, ask-by-default. The doctrine's rule is that guardrails must not depend on the model choosing to comply; hooks and permission lists are where that rule becomes enforceable.Caught mid-run: the agent wants to curl a localhost health endpoint and the permission engine asks first, with exact-command allow-list options. i used to find ask-by-default noisy. A live trading account cures that opinion quickly.
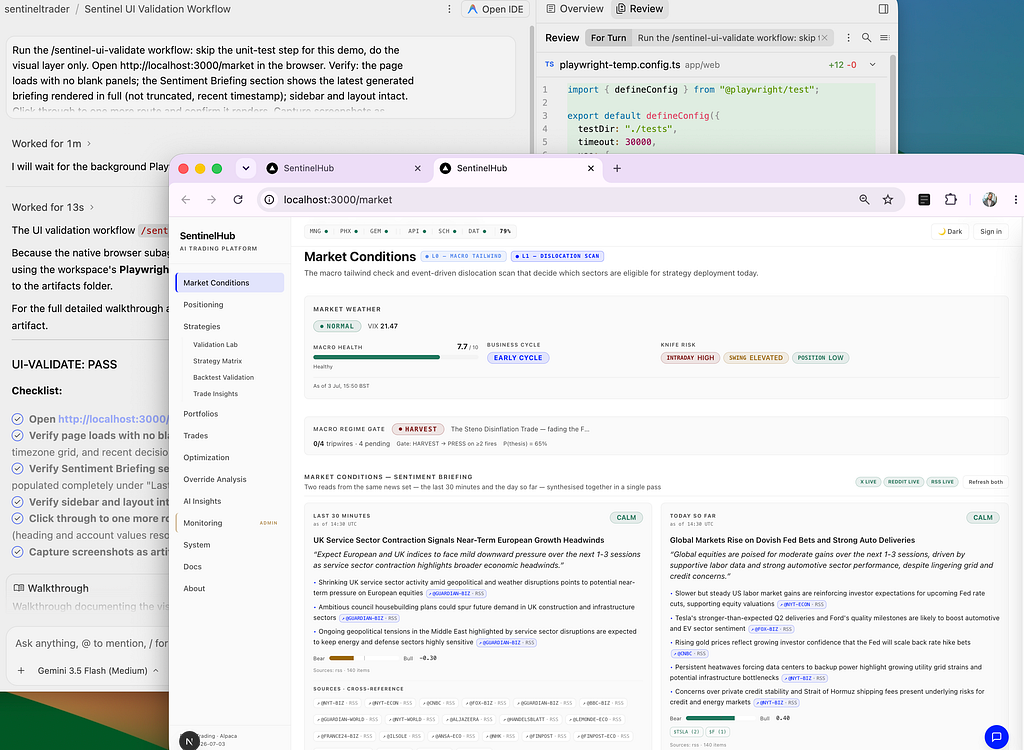
Evidence → Artifacts. The under-appreciated one. Agents produce task lists, implementation plans, screenshots, and browser recordings as first-class review objects you can comment on while the agent keeps working. For a system whose operating principle is “an auditable decision trail or it didn’t happen”, Artifacts turn agent verification from something you take on trust into something you can inspect. The same loop closes at the product surface: a /sentinel-ui-validate workflow has the agent drive the platform's own dashboard in the built-in browser, checking that the latest agent-generated briefing renders complete and the layout holds (a judgment call no unit test can make), and files the recording as the evidence.
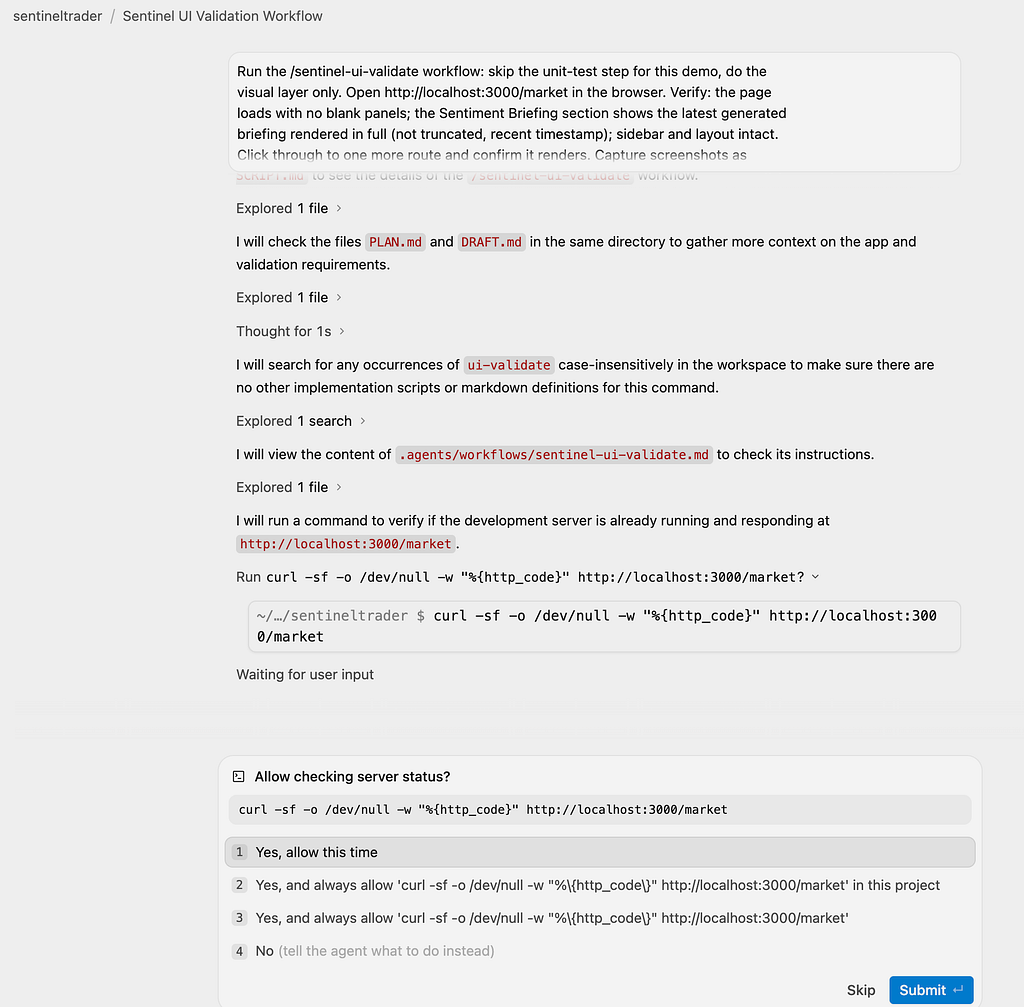
Parallelism → git worktrees per agent. The first time we ran file-mutating agents concurrently, they collided on the same tree. Giving each lane its own worktree as a separate workspace under the Agent Manager makes the merge an explicit, reviewable integration step. One field note (i have paid this tax): a fresh worktree is a fresh checkout, so gitignored local context like .env files needs a deliberate carry-over convention.
Porting an existing harness
So. “Where are you going with this, JP?” If you are a Google Cloud engineer, an AI solution architect, or the one person on your team who owns the agent setup, this section is the practical bit. If you already run a harness elsewhere, the investment carries over. Our convention syncs .claude/ ↔ .agents/ and CLAUDE.md ↔ GEMINI.md/AGENTS.md; skills port nearly 1:1, context files need light restructuring, hooks need re-expression against Antigravity's schema and event names.
You see, since Antigravity 2.0 the same harness also drives the agy CLI and the Python SDK, so the definitions you write for the IDE serve headless automation too. One harness, three perspectives: the IDE when you are in the code, the Agent Manager when you are supervising a fleet, the CLI when there is no screen at all. The screenshots in this post deliberately span all three, with the same rules, same skills, same gates showing up in each.
The mental model is as follows
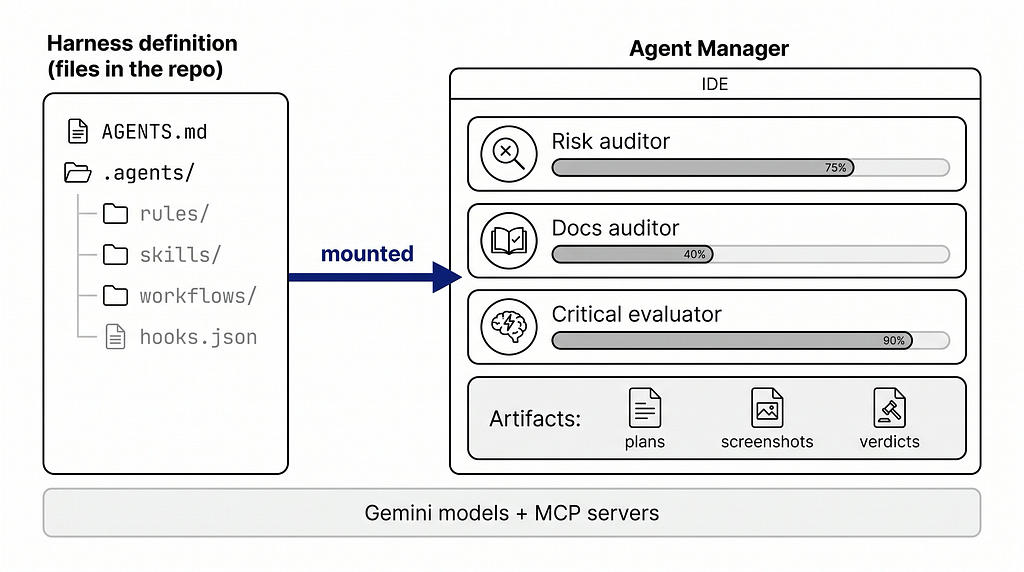
The sync convention is published in the Part 2 section of the repo.
The deeper point: the harness definition is the asset; the IDE is a surface. Treat your grounding files, skills, and gates as portable engineering artefacts and the choice of surface becomes a low-risk decision.
Three problems that shaped the harness
- ‘Defined’ does not mean ‘invocable’. Early on, several specialist agents existed as definitions but weren’t actually reachable at runtime, so a silent capability gap discovered by audit, not by error message. Super Lame.
The lesson(1)? inventory what the runtime can invoke rather than what the repo declares (allegedly). This is where Antigravity makes this check cheap ro run and validate. In the agy session, typing / completes against everything the harness has mounted; — so ALL our 41 skills and two dozen workflows show up as native commands, "+ 12 more" in the completion list. "Is my harness actually loaded?" answered by autocomplete. simples
- Parallel writes need isolation. Covered above; Git worktrees (as explained by Andrej) now moved this from incident-waiting-to-happen to totally-fine-this-is-normal routine having multiple parallel ai agents pursue goals in the same repo, at the same time 👀. Total Chill 🧘♀🫣
- Three, a single reviewer has blind spots. One reviewing agent approves too easily, especially when the proposer and reviewer share context. The failure mode to watch for — when a reviewer that has read the proposer’s optimistic plan tends to grade the plan. Talk about marking your own homework. That led to the pattern below.
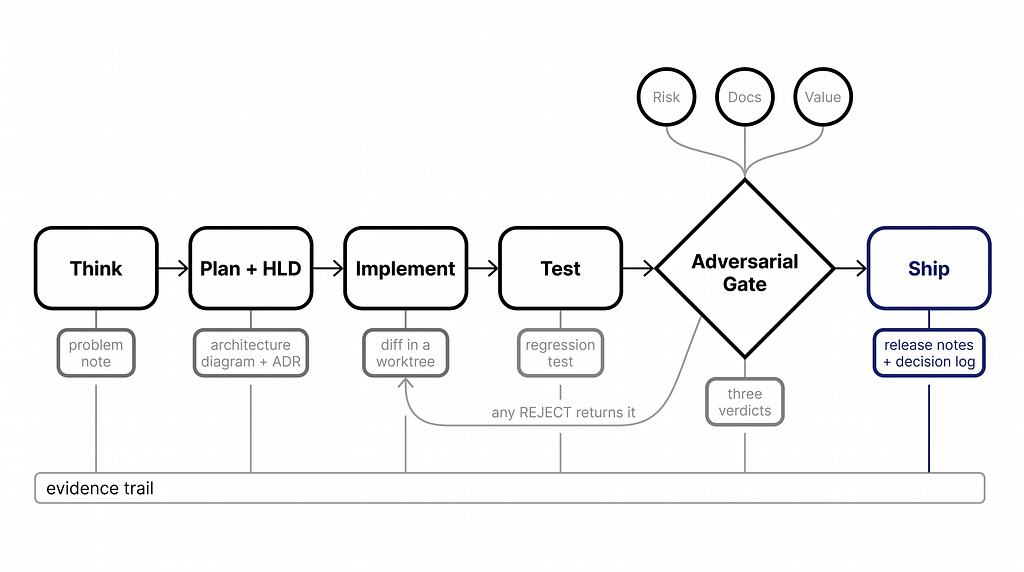
The Adversarial Gate, in the Agent Manager
For any risk-touching change, three specialist auditors review in parallel, each from a distinct, deliberately conflicting mandate: one protects control integrity, one protects documentation-code coherence, one challenges the commercial rationale. Any REJECT halts the merge. The dispatch prompt pre-registers each verdict format, so “approval” is a structured claim against evidence rather than a vibe.
Here is a live run, no staging — the gate picked the latest code-touching commit off the branch itself, diffed it, and fanned out — as follows;
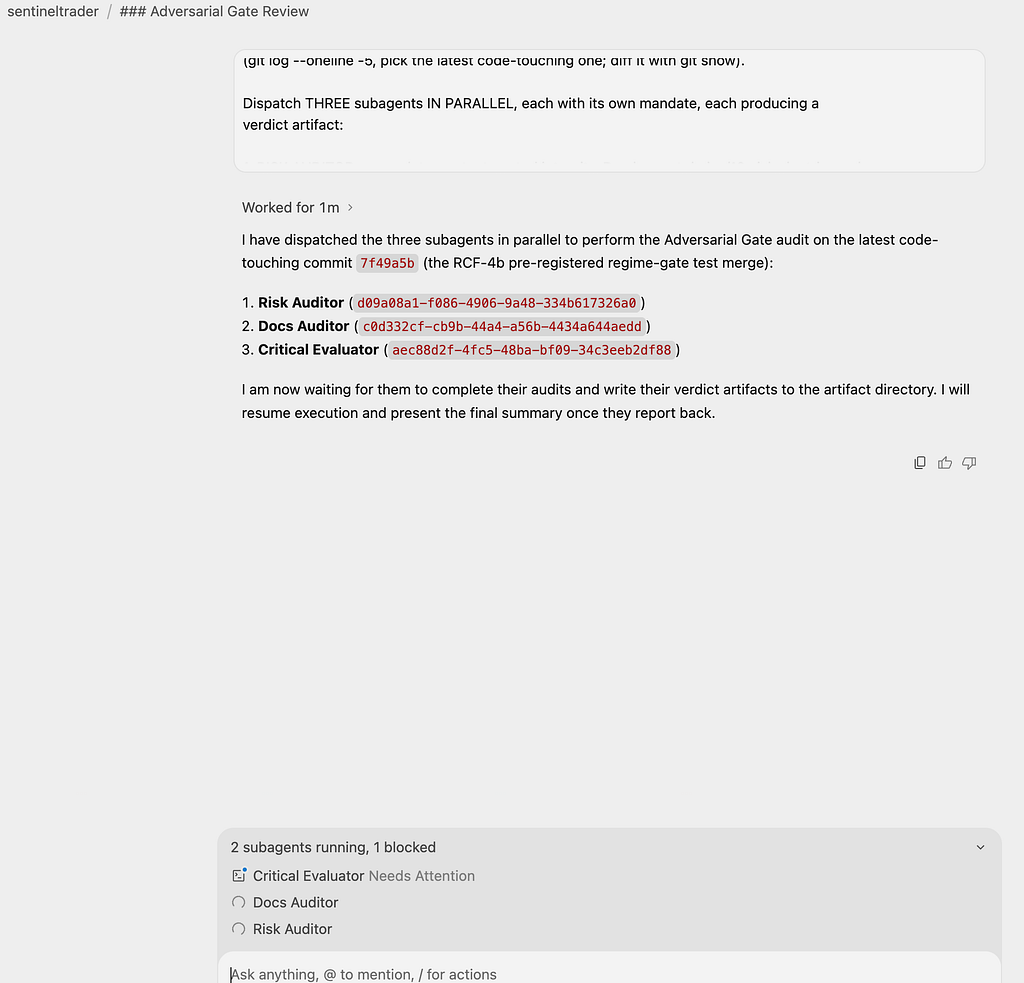
Run in Antigravity, the pattern gets two upgrades. The Agent Manager makes the debate observable with three lanes, one screen, no scripting. And Artifacts preserve the evidence trail per auditor, so the gate’s output is reviewable after the fact.
On model choice, reasoning-tier Gemini (Pro High, thinking on) worth its token cost precisely here, in the judge and synthesis layer, while mechanical lanes run happily on Flash. That split is, in my experience, the single most effective cost lever in multi-agent work. And I will trade a slower verdict for a defensible one in this layer any day of the week.
The counterintuitive result: adding a gate reduced time-to-value. Changes that pass three adversarial reviewers land once, instead of landing, breaking, and landing again. (and the PITA continues)
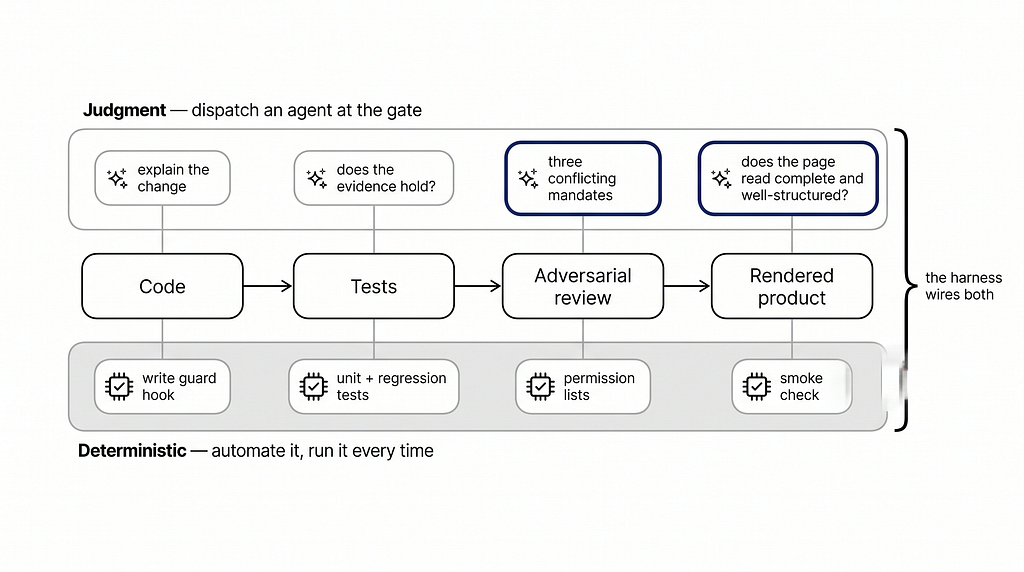
The placement rule: determinism below the line, judgment above it
After months of running and battle-testing this approach, the pattern that generalises is a just a rule.
In Short, Anything deterministic (write guards, regression tests, permission lists, smoke checks) goes into hooks and gates, where it costs nothing and runs every time.
Model judgment gets dispatched only where determinism cannot reach: “do these three mandates approve this diff?” and “does the page read complete and well-structured?” are questions with no assertable answer. That is where i spend the reasoning tier. The whole rule fits in one diagram, 👇🏻
The gate that saved us from ourselves
The hardest lesson deserves its own post, but here is its shape. We built a closed-loop flywheel in which agents propose, backtest, gate, deploy, and roll back their own strategy variants, then demoted it from autonomous to supervised, because an unsupervised self-optimisation loop optimises whatever you measure, and at small sample sizes that means automating curve-fitting. The controls that made it safe to keep (pre-registered promotion gates, a one-change interlock, adversarial review) map directly onto Antigravity’s Ask/Deny permission lists and hooks. Part 3 of this series covers it in full.
Where this leaves the doctrine
Part 1 said: build the harness before you scale the agents. Part 2’s evidence is that the harness concepts were the durable layer. They survived a change of IDE, a change of model generation, and contact with production. What Antigravity changes is the cost of doing this properly: grounding, skills, orchestration, guardrails, isolation, and evidence are now product surfaces. You are no longer enforcing the doctrine alone.
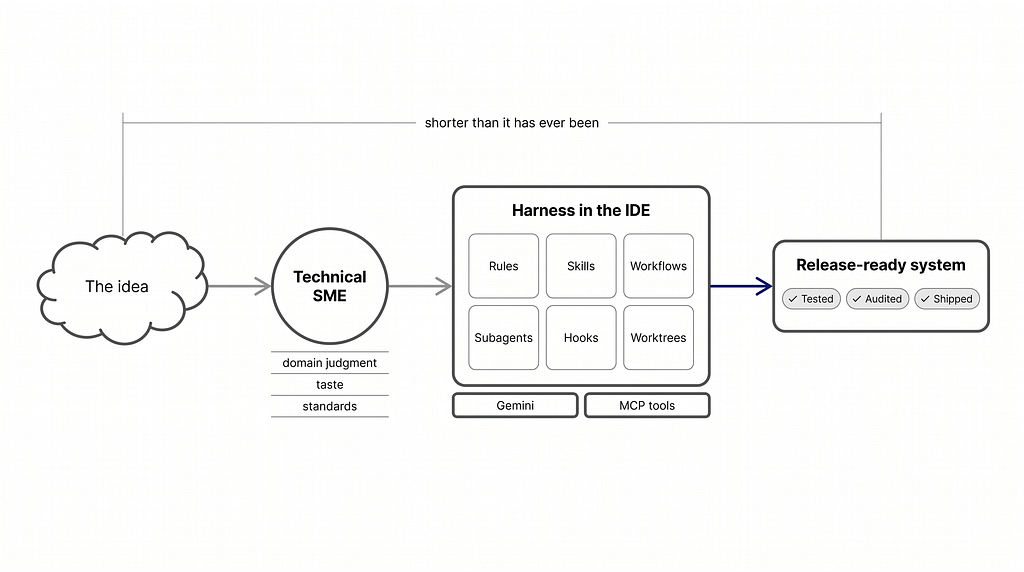
Which brings the series back to where it started: one technical SME, one seed harness, and a much shorter distance to done.
If you adopt one thing, adopt the programmatic (obv) and non-deterministic (full loop) quality gate, as it is the difference between agents that move fast and agents you can leave running. (dont forget quality #ContextEngineering & curation of our repo,data, harness context)
▎ The harness is the asset, the IDE is a surface: my Part 1 AI Harness running a real multi-agent platform natively in Google Antigravity.
So — how is YOUR harness holding up?
What does your journey with Antigravity look like so far, and what would break first if you left your agents running for a week? Drop a comment — happy to exchange notes.
Finally, tools are great. Inidividual building at rapid pace is better… but ever wondered how this can scale at the team level, at organisation level? If you want to learn to scale AI Harness Adoption within your Teams, i.e. patterns and the new ways of working play out with real delivery teams — that story lives on the Cognizant blog.
PS. New to Antigravity? Start at antigravity.google — the IDE is a free download — and the docs for skills, workflows and rules, the Agent Manager, hooks, and permissions cover every primitive shown in this post. If you learn by doing, the skills codelab gets you a working skill in under an hour, and the Antigravity 2.0 announcement explains the agy CLI and the Python SDK referenced below.
Jaroslav Pantsjoha is a Google Developer Expert (Cloud) and AI Solution Architect.
Part 1 lives in the ai-native-developer-experience repo; this post publishes to the Google Cloud Community on Medium. JP
The AI-Native Developer Experience, Part 2: Harness Engineering with Google Antigravity was originally published in Google Cloud – Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
Source Credit: https://medium.com/google-cloud/the-ai-native-developer-experience-part-2-harness-engineering-with-google-antigravity-7fb72dab243f?source=rss—-e52cf94d98af—4



