
I’ve been running Claude Code linked to a local LLM server for a while now, and I’m convinced it’s the setup to aim for. You don’t need a dedicated AI box or heavy workstation GPUs (though I have used both), and I’ve moved to serving my LLMs from my gaming PC.
I’ve found that for the coding I actually do, I don’t need huge models that strain even the RTX Pro 6000; I can get by with many of the 4B models, which means my RTX 5090 no longer sounds like it’s going to take off while crunching code. And if I need anything bigger, I can use Nvidia’s cloud models or my Claude subscription.
Oh, yeah. About that. I’m not cutting my Claude Max subscription out of the picture. It’s too useful, whether it’s Cowork helping fix my Home Assistant setup or Opus figuring out thorny problems. But I am being a little more careful about shepherding my token allocations into tasks that need the power of cloud models, and using local LLMs for everything else.
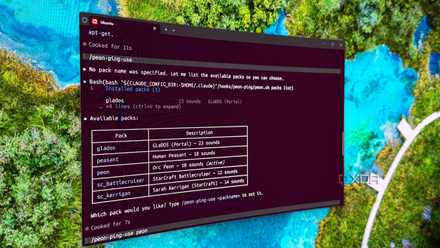
I customized Claude Code to interrupt me with Warcraft sounds, and now I actually notice when it’s done
Work, work…
I’m not here to argue against Claude’s models
They’re good, end of story
Running local LLMs to offset my use of Claude was a smart play, but I can’t deny that Claude’s models are fantastic. Opus has been the best for reasoning among any LLMs I’ve used, even the frontier models from other companies.
|
Model |
Best for |
Speed |
Cost |
Notes |
|---|---|---|---|---|
|
Claude Opus 4.7 |
Complex reasoning, agentic coding, long-horizon tasks |
Moderate |
Highest |
Anthropic’s most capable generally available model. |
|
Claude Sonnet 4.6 |
General-purpose work, coding, analysis, enterprise workflows |
Fast |
Medium |
The best balance of speed and intelligence. |
|
Claude Haiku 4.5 |
Quick responses, high-volume tasks, cost-sensitive use |
Fastest |
Lowest |
Near-frontier performance at the cheapest price point. |
Sonnet is my workhorse, and Haiku is good when I want a quick answer, but I regularly hit the daily and weekly limits even on the Max plan. To be more specific, the $100 plan, although I upgraded to the $200 one, and I’m already hitting the daily limits there, especially when using Claude Design.

- OS
-
Windows, macOS
- Individual pricing
-
Free plan available; $17/month Pro plan
Everything is a nail when all you have is a hammer
Model devs push their flagships the most, because why wouldn’t you start with the best? But you don’t need the power of those models for a huge swathe of the tasks they’re used for. I’m not going to generalize and throw out some random percentages, but from my personal usage, local LLMs have improved substantially.
Maybe they’re a year or so behind, in terms of the quality of their output on complex tasks, but for simple things like refactors or minor bug fixes, they’re just as capable. Which is staggering when you take a second to think about it, because the local model runs on your GPU’s VRAM (or a mix of VRAM and system RAM, depending on your setup), while the cloud model runs on literally thousands of servers, each with thousands of GPUs inside.
Take Qwen3.6-27B, for example: it can run on an AMD APU or an Apple Mac with 32GB of unified memory or a 24GB graphics card, yet boasts “flagship coding power.” That was impossible to conceive of a short while ago, and the time to the next jump keeps shrinking.
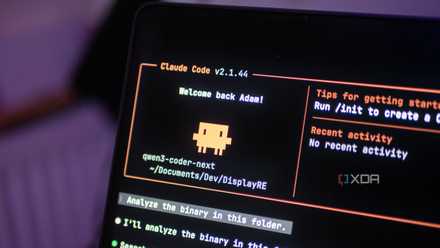
I finally found a local LLM I actually want to use for coding
Qwen3-Coder-Next is a great model, and it’s even better with Claude Code as a harness.
Choice is the point
You don’t need to pay for tokens if your task can be done locally

I could use Claude for everything, and I have in the past. But I don’t need to burn tokens on summarizing documents, or even picking at connections between multiple documents and providing reasoning. That’s something that can be done on 4B models running on your CPU, or even on your smartphone.
Model diversity also makes for a more interesting field. Reasoning models can “think” for longer to make up for their smaller size. Mixture-of-experts (MoE) models might look large, but with only a few billion parameters active at any one time, you can run them on modest hardware and still get an interactive experience.
I’ve also noticed that Claude isn’t ideal for some tasks. Image generation, even for simple graphs, is behind the curve, and I can use FLUX.1.Dev or SDXL instead, or use Qwen 2.5VL or Llama 3.2 Vision for design tasks. Deepseek’s models are great at reasoning and also good for coding alongside Qwen Coder.
The last part is that by running multiple local LLMs for each use case, I can run the same prompt on them and then have them critique each other’s work. I’ve found that gives the best results, even with frontier models, and I regularly get ChatGPT to check over things Claude has created.
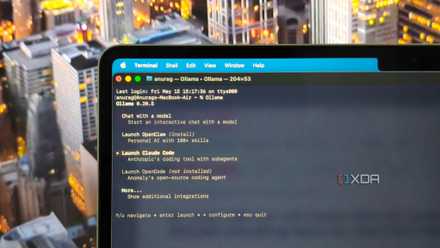
My local LLM can call Claude when it’s stuck, and it changed everything about my local-first setup
Local LLMs aren’t very good on their own
Freedom in model choice makes AI workflows better
Using the frontier models for every task is a waste of tokens. You wouldn’t go grocery shopping in a hypercar, but that’s what you’re doing when you ask Opus to make simple changes to code. Qwen’s Coder family of models is just as capable at most coding tasks, and runs on much more affordable hardware. And you don’t need Claude to scan your email inbox and give you a summary, even if it makes the job easier.
The point I’m trying to make is that picking the right tool for the job is essential and will become even more so as API and token costs increase. Yes, increase. The current subscriptions are being heavily subsidized, and I think everyone is in for a shock when the subsidies stop. Getting used to the quirks and speed of local LLMs now is a wise move.






